论文阅读笔记:Layer Normalization
提示:阅读论文时进行相关思想、结构、优缺点,内容进行提炼和记录,论文和相关引用会标明出处。
文章目录
- 前言
- Abstract
- Introduction
- Background
- Layer normalization
- Layer normalized recurrent neural networks
- Related work
- Analysis
- Experimental results
- Conclusion
前言
标题:Layer Normalization
原文链接:Link
Github:NLP相关Paper笔记和实现
说明:阅读论文时进行相关思想、结构、优缺点,内容进行提炼和记录,论文和相关引用会标明出处,引用之处如有侵权,烦请告知删除。
转载请注明:DengBoCong
Abstract
训练最新的深度神经网络在计算上是昂贵的,减少训练时间的一种方法是归一化神经元,最近引入的一种称为批归一化的技术使用训练案例的小批量上神经元的总输入分布来计算均值和方差,然后使用均值和方差对每个训练案例中该神经元的总输入进行归一化,这大大减少了前馈神经网络的训练时间。但是,批归一化的效果取决于小批量的大小,如何将其应用于递归神经网络尚不明显。在本文中,我们通过在单个训练案例上计算从层的所有总输入到神经元的归一化的均值和方差,将批归一化转换为层归一化。像批归一化一样,我们还为每个神经元提供了自己的自适应偏差和增益,这些偏差和增益在归一化之后且在非线性之前应用。与批归一化不同,层归一化在训练和测试期间执行完全相同的计算。通过在每个时间步分别计算归一化统计量,将其应用于递归神经网络也很简单。层归一化在动态稳定循环网络中的隐藏状态方面非常有效。从经验上讲,我们表明与以前发布的技术相比,层归一化可以大大减少训练时间。
Introduction
已经证明,使用某种形式的随机梯度下降训练的深度神经网络在计算机视觉和语音处理的各种监督学习任务上的性能大大优于以前的方法。但是最先进的深度神经网络通常需要几天的训练,可以通过在不同机器上为训练案例的不同子集计算梯度或在许多机器上拆分神经网络本身来加快学习速度,但这可能需要大量的交互且复杂 软件,随着并行度的增加,这将导致收益迅速减少。正交方法是修改在神经网络的前向传递中执行的计算,以使学习更轻松。最近,提出了批归一化,以通过在深度神经网络中包括其他标准化阶段来减少训练时间。归一化使用训练数据中的平均值和标准差对每个求和的输入进行标准化,即使使用简单的SGD,使用批归一化训练的前馈神经网络也能更快收敛,除了改善训练时间外,批统计中的随机性还可以作为训练期间的正则化器。
尽管简单,但批归一化仍需要对求和的输入统计信息求平均值,在深度固定的前馈网络中,直接为每个隐藏层分别存储统计信息很简单,但是,递归神经网络(RNN)中递归神经元的总输入通常随序列长度而变化,因此对RNN应用批归一化似乎需要针对不同时间步长进行不同统计。此外,批归一化不能应用于在线学习任务或批必须很小的超大型分布式模型。
本文介绍了层归一化,这是一种提高各种神经网络模型训练速度的简单归一化方法,与批量归一化不同,该方法从隐藏层内神经元的总输入直接估算归一化统计数据,因此归一化不会在训练案例之间引入任何新的依存关系,我们表明,层归一化对RNN效果很好,并改善了几种现有RNN模型的训练时间和泛化性能。
Background
前馈神经网络是从输入模式 x x x到输出向量 y y y的非线性映射,考虑深度前馈神经网络中的第 l l l个隐藏层,并将 l l l表示为该层中神经元的总输入的向量表示,通过权重矩阵 W l W^l Wl和自下而上的输入 h l h^l hl的线性投影来计算总和输入,如下所示:
a i l = w i l T h l a_{i}^{l}={w_{i}^{l}}^{T}h^l ail=wilThl h i l + 1 = f ( a i l + b i l ) h_{i}^{l+1}=f(a_{i}^{l}+b_{i}^{l}) hil+1=f(ail+bil)
其中f(.)是逐个元素的非线性函数,而 w i l w_{i}^{l} wil是第 i i i个隐藏单元的传入权重, b i l b_{i}^{l} bil是标量偏差参数,使用基于梯度的优化算法学习神经网络中的参数,并通过反向传播计算梯度。
深度学习的挑战之一是,相对于一层中权重的梯度高度依赖于上一层中神经元的输出,特别是如果这些输出以高度相关的方式变化时。因此提出了批归一化,以减少这种不希望的“Internal Covariate Shift”。该方法对训练案例中每个隐藏单元的求和输入进行归一化。 具体来说,对于第 l l l层中的第 i i i个求和输入,批归一化方法根据求和输入在数据分布下的方差重新缩放
a ˉ i l = g i l σ i l ( a i l − μ i l ) \bar{a}_{i}^{l}=\frac{g_{i}^{l}}{\sigma_{i}^{l}}(a_{i}^{l}-\mu_{i}^{l}) aˉil=σilgil(ail−μil) μ i l = E X ∼ P ( x ) [ a i l ] \mu_{i}^{l}=\underset{X\sim P(x)}{\mathbb{E}}[a_{i}^{l}] μil=X∼P(x)E[ail] σ i l = E X ∼ P ( x ) [ ( a i l − μ i l ) 2 ] \sigma_{i}^{l}=\sqrt{\underset{X\sim P(x)}{\mathbb{E}}[(a_{i}^{l}-\mu_{i}^{l})^2]} σil=X∼P(x)E[(ail−μil)2]
其中 a ˉ i l \bar{a}_{i}^{l} aˉil是第 l l l层中第 i i i个隐藏单元的归一化总和输入, g i g_i gi是在非线性激活函数之前缩放归一化激活的增益参数,注意期望是在整个训练数据分布下。 在上面的等式中精准计算期望值通常是不切实际的,因为这将需要使用当前的权重集前向传递至整个训练数据集。 取而代之的是,使用当前小批量的经验样本估算出 µ µ µ和 σ σ σ,这限制了小批量生产的规模,并且很难应用于递归神经网络。
Internal Covariate Shift一个较规范的定义:在深层网络训练的过程中,由于网络中参数变化而引起内部结点数据分布发生变化的这一过程被称作Internal Covariate Shift。
关于Batch Normalization的相关介绍,可以看这边知乎文章,里面写的蛮清晰的。
Layer normalization
请注意,一层输出的变化将趋向于导致对下一层求和的输入发生高度相关的变化,尤其是对于ReLU单元,其输出可以变化 l l l。这表明可以通过固定每一层内求和输入的均值和方差来减少“covariate shift”问题。因此,我们计算与以下相同层中所有隐藏单元的层归一化统计量:
μ l = 1 H ∑ i = 1 H a i l \mu^{l}=\frac{1}{H}\sum_{i=1}^{H}a_{i}^{l} μl=H1i=1∑Hail σ l = 1 H ∑ i = 1 H ( a i l − μ l ) 2 \sigma^{l}=\sqrt{\frac{1}{H}\sum_{i=1}^{H}(a_{i}^{l}-\mu^l)^2} σl=H1i=1∑H(ail−μl)2
其中H表示层中隐藏单元的数量,和batch Normalization不同的是,这是在层归一化下,层中所有隐藏单元共享相同的归一化项 μ μ μ和 σ σ σ,但是不同的训练案例具有不同的归一化项。
与批归一化不同,层归一化对小批处理的大小没有任何限制,它可以在批大小为1的在线方式中使用。
Layer normalized recurrent neural networks
在NLP任务中,对于不同的训练案例,通常有不同的句子长度。这在RNN中很容易处理,因为每个时间步使用相同的权重。但是,当我们以明显的方式将批归一化应用于RNN时,我们需要为序列中的每个时间步计算并存储单独的统计信息。如果测试序列比任何训练序列都要长,这是有问题的。层归一化不存在此类问题,因为其归一化项仅取决于当前时间步对层的求和输入。 在所有时间步中,它也只有一组增益和偏置参数共享。
在标准RNN中,根据当前输入 x t x^t xt和隐藏状态 h t − 1 h^{t-1} ht−1的计算递归层中的总输入,计算得出 a t = W h h h t − 1 + W x h x t a^t=W_{hh}h^{t-1}+W_{xh}x^t at=Whhht−1+Wxhxt
h t = f [ g σ t ⨀ ( a t − μ t ) + b ] h^t=f[\frac{g}{\sigma^{t}}\bigodot (a^t-\mu^t)+b] ht=f[σtg⨀(at−μt)+b] μ t = 1 H ∑ i = 1 H a i t \mu^t=\frac{1}{H}\sum_{i=1}^{H}a_{i}^{t} μt=H1i=1∑Hait σ t = 1 H ∑ i = 1 H ( a i t − μ t ) 2 \sigma^t=\sqrt{\frac{1}{H}\sum_{i=1}^{H}(a_{i}^{t}-\mu^t)^2} σt=H1i=1∑H(ait−μt)2
W h h W_{hh} Whh是递归隐藏层的隐藏权重, W x h W_{xh} Wxh是自底向上的输入的隐藏权重, ⨀ \bigodot ⨀是两向量之间逐元素点积, b b b和 g g g定义为与 h t h^t ht维度相同的偏置和增益参数。
在标准RNN中,递归单元的总输入的平均幅度影响了每个时间步长增长或收缩,从而导致梯度爆炸或消失。在层归一化的RNN中,归一化项使将所有求和的输入重新缩放为层不变,这将导致更稳定的隐藏到隐藏的变化。
Related work
在权重归一化中,使用输入权重的L2范数代替方差来归一化对神经的求和输入,使用预期统计量应用权重归一化或批归一化等效于对原始前馈神经网络进行不同的参数化,但是,我们提出的层归一化方法不是对原始神经网络的重新参数化。因此,层归一化模型具有与其他方法不同的不变性,我们将在以下部分中研究该方法。
Analysis
- 权重不变和数据转换
- 训练期间参数的几何空间:paper证明归一化标量 σ σ σ可以隐式降低学习率并使学习更稳定

Experimental results
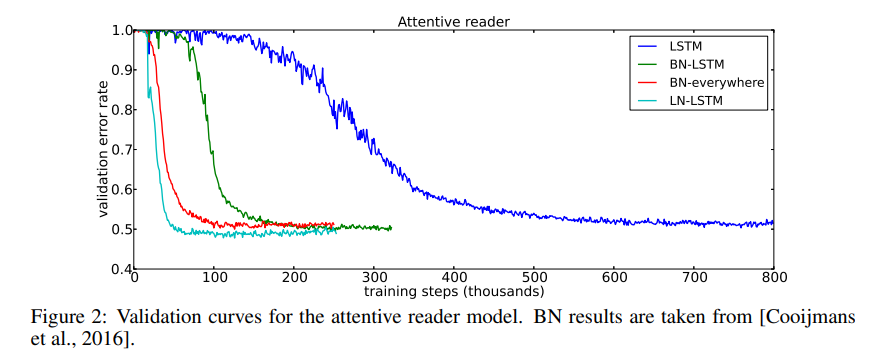
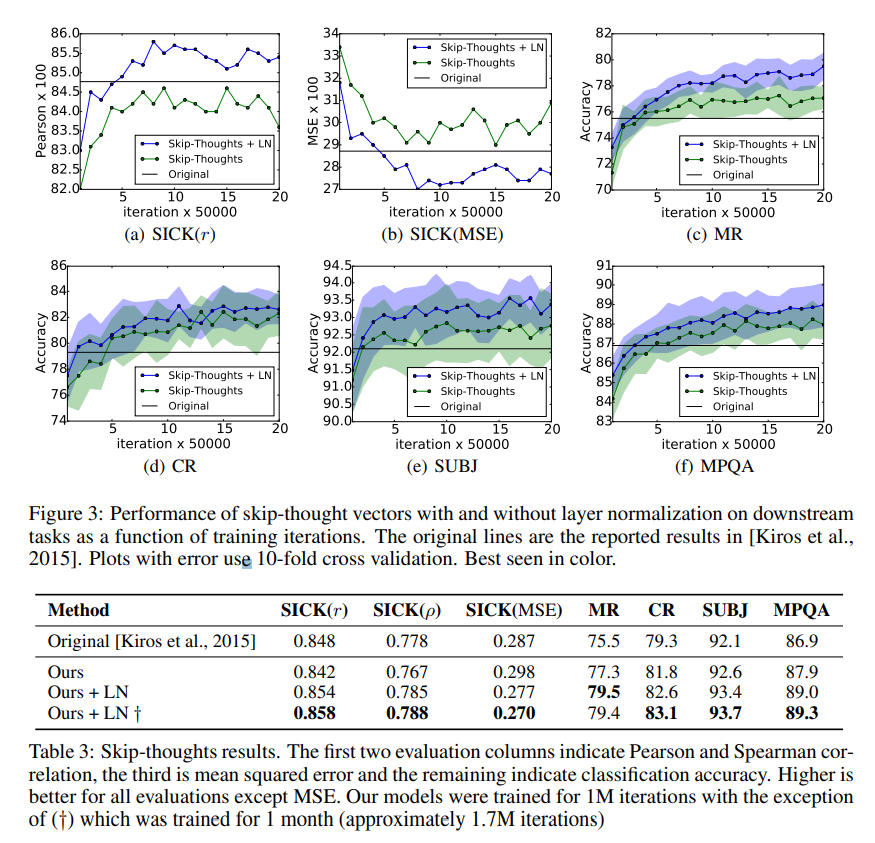
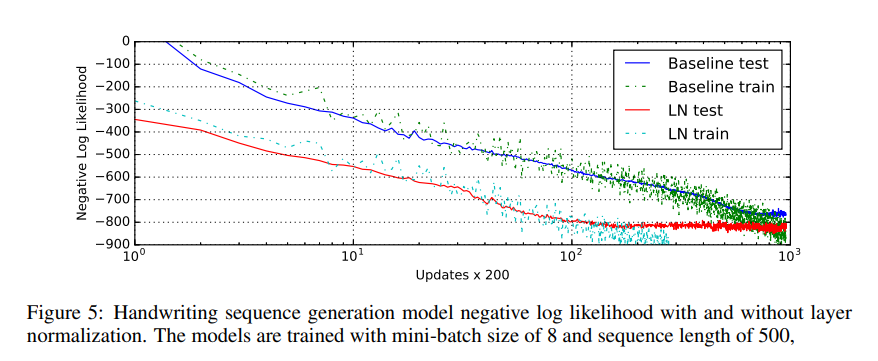
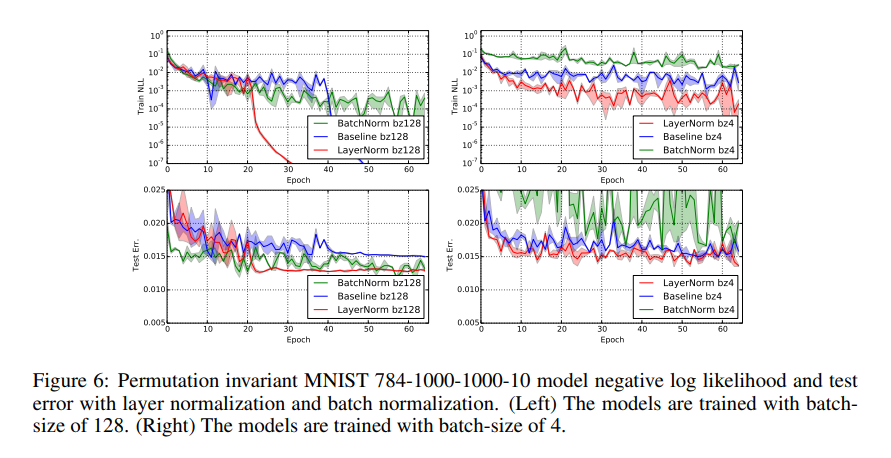
Conclusion
在本文中,我们介绍了层归一化以加快神经网络的训练。我们提供了理论分析,将层归一化与批归一化和权重归一化的不变性进行了比较。我们显示了层归一化对于每个训练案例特征平移和缩放都是不变的。根据经验,我们证明了递归神经网络从拟议的方法中受益最大,特别是对于长序列和小型小批处理。


































还没有评论,来说两句吧...