【论文阅读】batch normalization与layer normalization 在nlp的比较
文章目录
- BN
- BN在训练和测试的区别
- BN的缺点
- LN
- 区别
- NLP:BN or LN?
BN
神经网络学习的过程,本质是为了学习数据的分布。
- 一旦训练数据和测试数据的分布不同,网络的泛化能力就会大大降低。
- 一个batch的训练数据分布不同,网络就需要每次迭代去适应不同的分布,这会大大降低网络的训练速度。
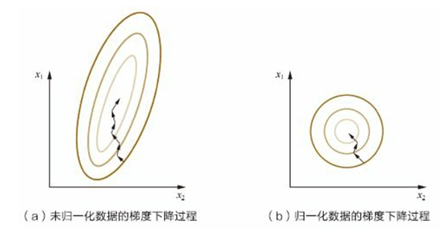
在学习速率相同的情况下,x1的更新速度大于x2,需要较多次数的迭代才能到达最优解。
如果将x1和x2归一化到相同的数值区间,优化目标的等值图像就变成图b中的圆形,x1和x2的更新速度变得一致,也允许使用较大的学习率,容易更快地梯度下降达到最优解,加速收敛。
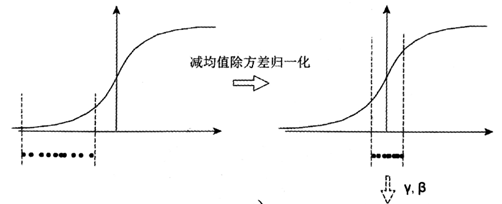
左图是没有经过任何处理的输入数据,如果数据在梯度比较小的区域,那么学习率会很慢陷入长时间的停滞。减均值除方差后,数据就被移动到右图的样子,对于大多数激活函数而言,这个区域的梯度都是最大的,可以对抗梯度消失。
对于一层数据是如此,如果每层都这么做的话,数据分布总是在变化敏感的区域。相当于不用考虑数据分布变化了,训练起来更有效率。
深度学习的挑战是,与一层权重相关的梯度,高度依赖于前一层神经元的输出,称之为协变量偏移。
batch normalization的提出,是为了减轻协变量偏移,对训练样本的每个隐藏单元的求和输入进行归一化处理。
有人提出可以在每层增加白化,让特征之间的相关性降低,特征的均值方差归一化。但是白化的计算量太大了,也不是处处可微的,不行。
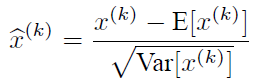
可以用这个归一化公式来处理,但是对网络的某一层A的输出做归一化,然后送入网络下一层B,这样强制的转换会破坏数据的分布。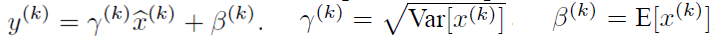
为了恢复原始的数据分布,BN引入了缩放平移,在训练过程中学习γ和β这两个参数,其中γ和β分别代表输入分布的方差和偏差。用这两个参数可以恢复最优的分布,与之前的网络层的参数解耦,提高模型的泛化能力。

计算过程:
- 计算当前batch每个通道的均值
- 计算当前batch每个通道的方差
- 对x归一化处理,获得x hat
- 加入缩放平移变量γ和β,也参与训练,保证每次数据经过归一化后,保留原本学习来的特征,同时又能完成归一化操作,加速训练。
不用BN,还需要慢慢调整学习率,甚至网络训练到一半的时候,还要想着学习率进一步调小的比例选择多少合适,现在我们可以用初始很大的学习率,衰减速度也很大,收敛快。
BN具有提高网络泛化能力的特性,具有轻微的正则化效果,减轻对dropout的依赖。

BN在训练和测试的区别
- 在训练时,我们可以计算每个batch的均值和方差,迭代训练的过程中,均值和方差一直在变化。
在测试时,是单实例的,不存在mini batch,无法获得BN计算所需的均值和方差。一般解决办法是,采用训练时记录的每个mini batch的统计量的数学期望,来推算全局的均值和方差,均值和方差是固定的。
z = g ( W u + b ) z=g(Wu+b) z=g(Wu+b) g是sigmoid激活函数,需要先经过BN层,再送入激活函数。
z = g ( B N ( W u + b ) ) z=g(BN(Wu+b)) z=g(BN(Wu+b)) 但是因为偏置参数b经过BN层后是没用的,反正BN层里有专门的β参数作为偏置项,所以参数b就不用了。
最后就变成了 z = g ( B N ( W u ) ) z=g(BN(Wu)) z=g(BN(Wu))
BN的缺点
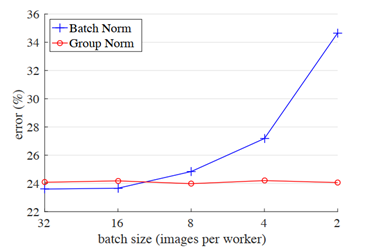
可以看出,在resnet网络的验证集上,随着batch size越来越小,BN产生的误差是显著增加的。
因为BN对于batch size的大小是比较敏感的,由于每次计算均值和方差是在一个batch上,所以batch size太小,计算的均值和方差就不足以代表整个数据分布。
BN实际使用时需要计算并保存某一层神经网络batch的均值和方差等统计信息,对于固定深度的前向神经网络,如CNN、DNN,就很方便。
对于RNN,求和输入通常随序列长度变化而变化,sequence的长度是不一致的,RNN的深度是不固定的,不同的time-step需要保存不同的特征。可能存在一个特殊的sequence比其他sequence长很多,这样训练时,计算很麻烦。需要对序列里每一个time-step计算和存储单独的统计信息。如果测试序列比任何训练序列都长,就有问题了。
一个自然的想法是:把对batch的依赖去掉,转换统计集合范围。
LN
这就引入了LN,在统计均值和方差的时候,不依赖batch内数据,只用当前处理的单个训练数据来获得均值方差的统计量,这样因为不再依赖batch内其他训练数据,不存在batch约束导致的问题。
与BN不同,LN在训练和测试阶段,执行完全相同的计算。实验证明,LN是稳定递归神经网络隐含状态的有效方法。
LN直接估计归一化统计量,从累加的输入到隐藏层中的神经元,因此LN不会在训练集直接引入新的依赖关系。
对于协变量偏移问题,可以通过固定每一层的总和输入的均值和方差来减少,因此计算同一层中所有隐藏单元的层归一化估计。
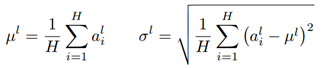
H H H是一层中,隐层结点的数量,和batch size 无关,只要隐层结点数量足够多就行。
层中所有隐藏单元共享相同的均值和方差,但不同样本对应不同的均值和方差。因此LN不受batch size大小的限制,也可以应用在batch size为1的情况。
尽管与BN计算方法不同,但是都可以归结为通过均值和方差将总和输入归一化到一个神经元。他们也学习一个自适应偏差b,并在归一化后为每个神经元获得g
对于RNN而言,他的归一化项只依赖于当前步长对层的输入求和。当前输入是 x t x^t xt,上一个隐藏状态为 h t − 1 h^{t-1} ht−1,加权输入向量为 a t = W h h h t − 1 + W x h x t a^t=W_{hh}h^{t-1}+W_{xh}x^t at=Whhht−1+Wxhxt,再对输入向量进行层标准化,再缩放平移,得到标准化输入y
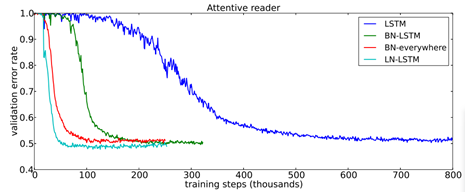
这张图展示的是,对于LSTM网络而言,使用LN(青色)不仅训练更快,而且能收敛到较好的效果。与之比较的是,绿色的是仅在LSTM使用BN,红色的是在整个网络处处使用BN,他俩都不如LN。
区别
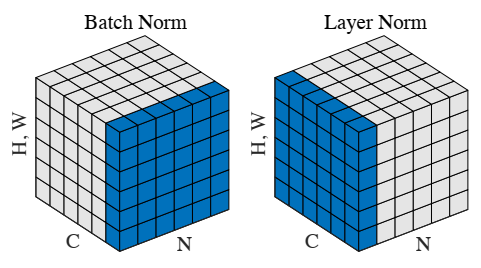
左边是BN,右边是LN
BN针对不同神经元的输入计算均值和方差,同一个batch的输入有相同的均值和方差。
LN中同一层神经元有相同的均值和方差,不同样本有不同的均值和方差。不依赖于batch大小和输入序列的深度,因此对于batch size为1和RNN的情况,都表现较好。
NLP:BN or LN?
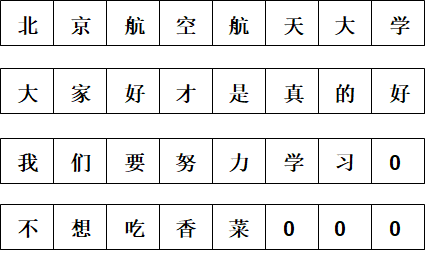
上面四条文本组成一个batch的数据,那么BN的操作是把4条样本相同位置的字来做归一化处理,例如:北大我不,这就破坏了一句话内在的语义联系。
而LN是对每句话做归一化处理,例如:大家好才是真的好,归一化处理后,一句话每个字之间的联系没有破坏。从这个角度看,LN适合NLP任务,也就是bert和Transformer用的比较多。
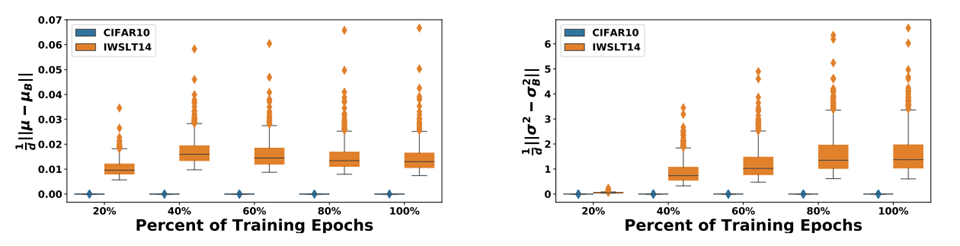
在论文《rethinking batch normalization in transformers》,作者将Transformer中的LN都换成BN,然后在CV任务(蓝色)和NLP任务(黄色),都观测了BN中的均值和方差在训练中的稳定程度。
蓝色是resnet20在CIFAR10做图像分类的任务,黄色是Transformer + BN在IWSLT14做翻译的任务。
可以看出,在CV任务震荡很小,在NLP任务震荡剧烈,而且有极端异常值。


























及SPRO的使用技巧")







还没有评论,来说两句吧...