Linux下hadoop伪分布式模式部署
文章目录
- 一、前言
- 二、设置环境变量
- 三、hadoop文件配置
- 四、启动hadoop
- 五、总结
一、前言
hadoop伪分布式部署需要jdk环境及安装hadoop,因之前在hadoop单机版配置写过,这里就不多赘述,未配置jdk环境或未安装hadoop可以去看看
https://blog.csdn.net/qq_41521180/article/details/88311299#hadoop_146
二、设置环境变量
编辑环境变量文件
vim ~/.bash_profile
在环境变量中添加hadoop的home、bin、sbin目录,我hadoop安装的路径为/usr/local/hadoop-2.6.5,大家记得修改为自己安装hadoop的路径
HADOOP_HOME=/usr/local/hadoop-2.6.5 //此处改为自己的hadoop目录路径export HADOOP_HOMEPATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHexport PATH
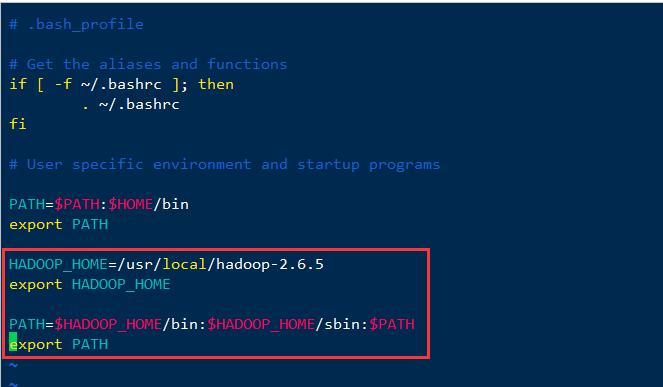
使环境变量生效
source ~/.bash_profile
三、hadoop文件配置
进入hadoop下的etc/hadoop目录编辑hadoop-env.sh文件
vim hadoop-env.sh
注释以下这行
export JAVA_HOME=${JAVA_HOME}
在注释下增加
export JAVA_HOME=/usr/java/jdk1.8.0_191-amd64
路径为jdk安装路径,安装过的可输入 echo $JAVA_HOME获取

在hadoop目录下新建tmp文件夹用以存放datanode数据
mkdir tmp
分别配置hdfs-site.xml、core-site.xml、mapred-site.xml、yarn-site.xml文件
配置文件在hadoop目录里的etc/hadoop/目录下
在hadoop路径下进入配置文件目录
cd etc/hadoop //进入配置文件目录
注意!在配置文件中,云服务器用户的,ip地址需要使用服务器私有ip
可输入ip addr查看或在云服务控制台查看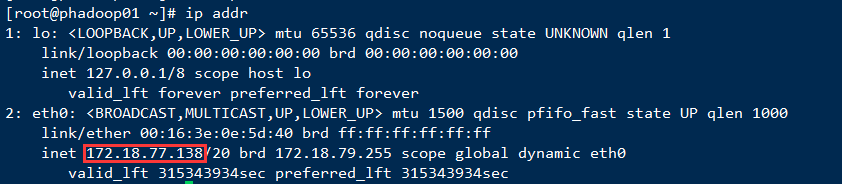
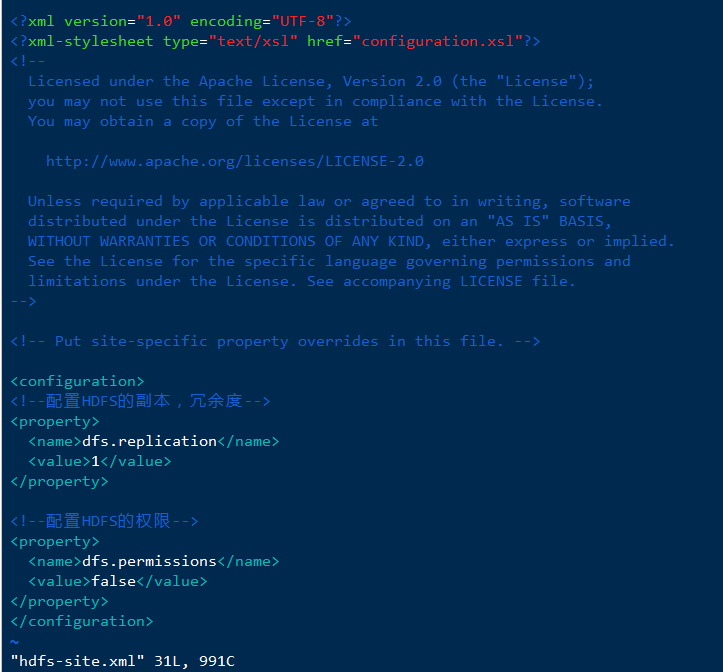
1、配置hdfs-site.xml文件
vim hdfs-site.xml
在 < configuration > < /configuration > 里添加以下内容
<!--配置HDFS的副本,冗余度--><property><name>dfs.replication</name><value>1</value></property><!--配置HDFS的权限--><property><name>dfs.permissions</name><value>false</value></property>
以此类推
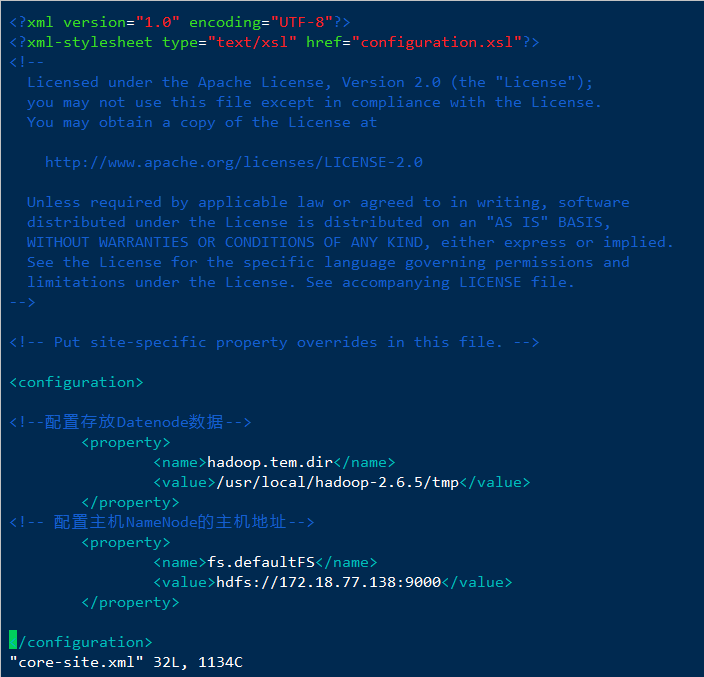
2、配置core-site.xml文件
<!--配置存放Datenode数据--><property><name>hadoop.tem.dir</name><value>tem文件路径</value></property><!-- 配置主机NameNode的主机地址--><property><name>fs.defaultFS</name><value>hdfs://ip地址:9000</value></property>
其中 我的tem文件路径为/usr/local/hadoop-2.6.5/tmp,服务器私有ip为
172.18.77.138,大家要根据自身情况修改,以免错误,下同
3、配置mapred-site.xml文件
<!--配置MR运行框架--><configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
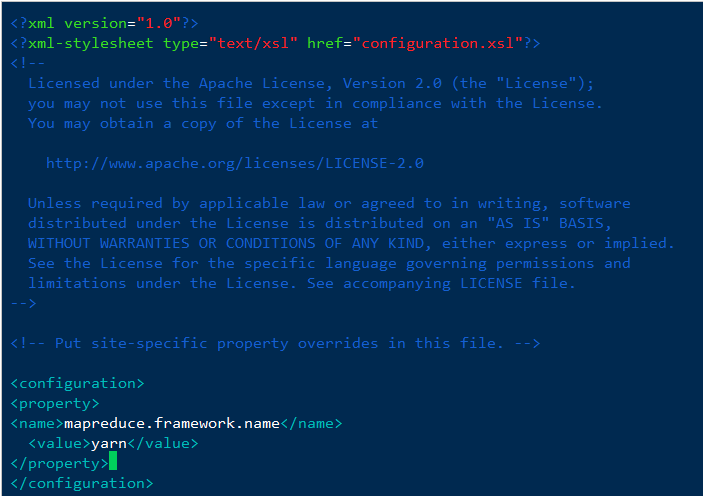
4、配置yarn-site.xml文件
<!--配置resourcemanagerd的地址--><property><name>yarn.resourcemanager.hostname</name><value>ip地址</value></property><!--配置Nodename的执行方式--><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
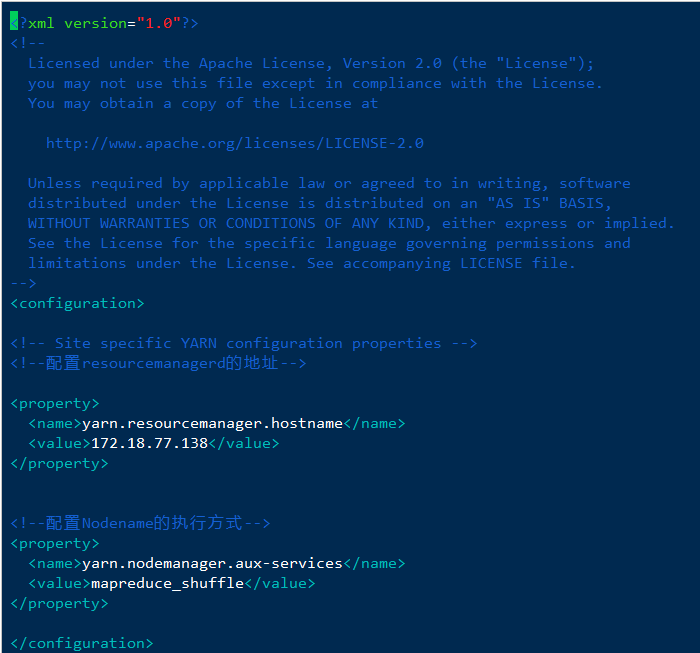
四、启动hadoop
格式化namenode
hdfs namenode -format
格式化成功后,启动hadoop,有让选择yes/no的选择yes,输入多次密码即可启动成功
start-all.sh
键入jps命令查看结点情况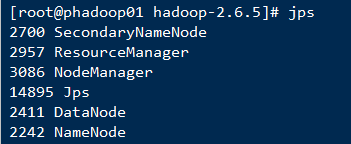
如上图则启动成功,在网页输入http://ip:8088 可看到一只黄色小象
注意!!!!:在网页输入的ip地址为公网ip,而不是私有ip
云服务器则需要在安全组开放8088端口才可访问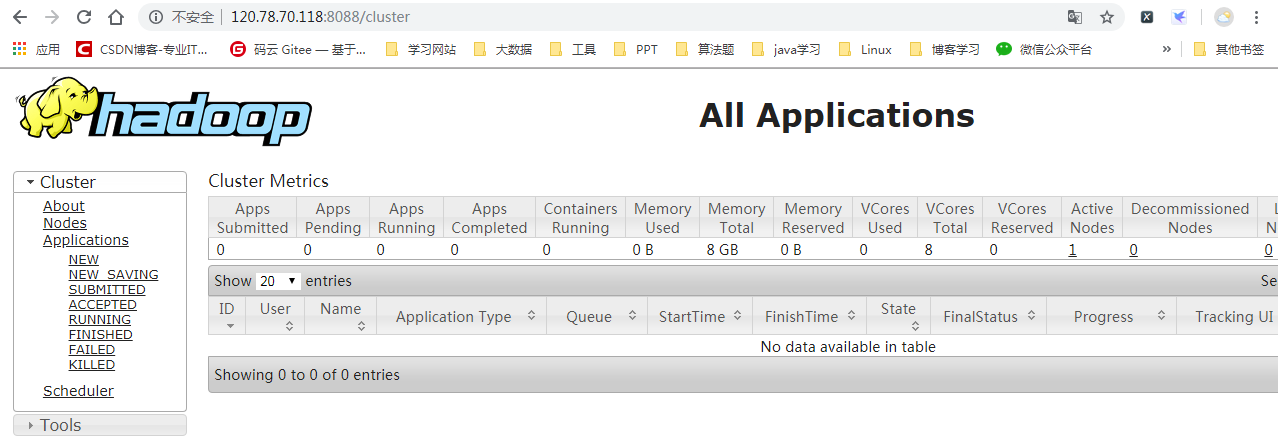
五、总结
hadoop伪分布式模式是本地模式的升级版,基本具备所有hadoop功能,如果结点只启动了部分,可以去logs目录查看未启动结点的日志信息,根据错误提示来解决问题。


































还没有评论,来说两句吧...