Centos7伪分布式部署Hadoop
前期准备
本教程基于vmware中创建的Centos7虚拟机环境进行教学。vmware中创建虚拟机与安装Centos7系统的步骤这里就不再赘述了,直接从系统安装完成后进行静态网络IP的配置开始说起。
配置静态网络
首先在vmware的 编辑 => 虚拟网络编辑器 下查看本机虚拟网卡的所在网段。可见此处的网段是192.168.72.0,子网掩码为255.255.255.0,记下这些信息。
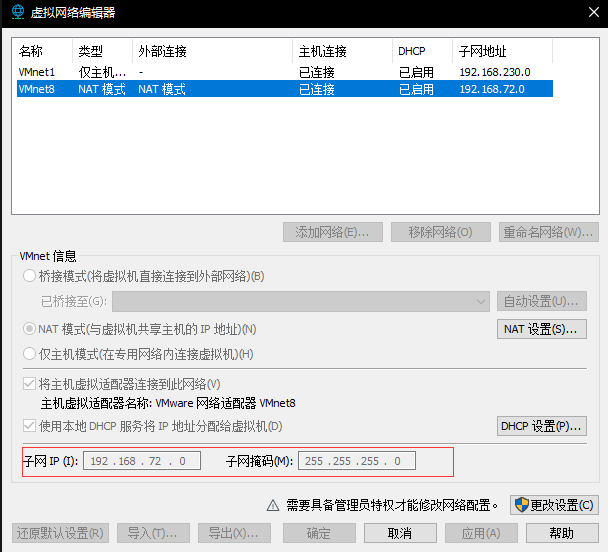
打开 网络和Internet设置 => 更改适配器选项 找到vmnet8网卡,右击打开 属性 选项卡

双击 Internet 协议版本4
修改ip、子网掩码与网关信息。注意:ip与网关要与vmware中的网段一致,子网掩码也要与vmware中保持一致。记住这里所配置的网关,之后虚拟机中配置网络需要使用。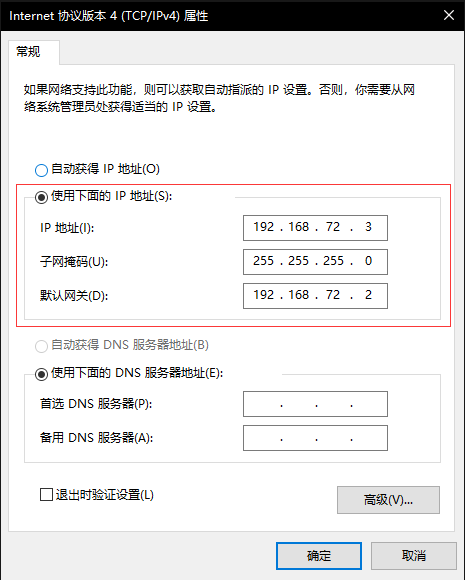
使用 vi /etc/sysconfig/network-scripts/ifcfg-ens33 修改网卡配置信息(由于镜像不同,ifcfg-ens后数字可能会不同)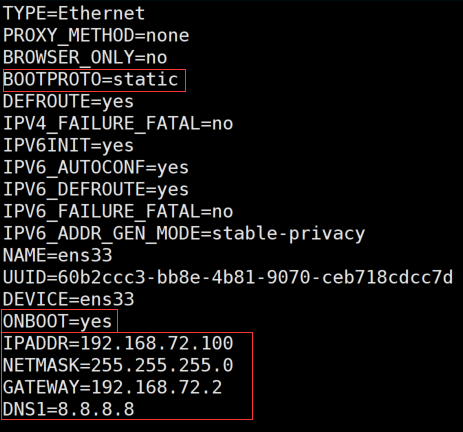
BOOTPROTO 设置为static 说明是静态IP
ONBOOT 设置为yes 开机自启
IPADDR 设置IP (网段与vmware中保持一致,且IP与之前本地虚拟网卡的IP与网关IP不一致)
NETMASK 设置子网掩码(与vmware保持一致)
GATEWAY 设置网关 (与本地虚拟网卡配置中的网关一致)
DNS1 (可选)
systemctl restart network 重启网络服务后使用 ip addr 命令查看配置的网络信息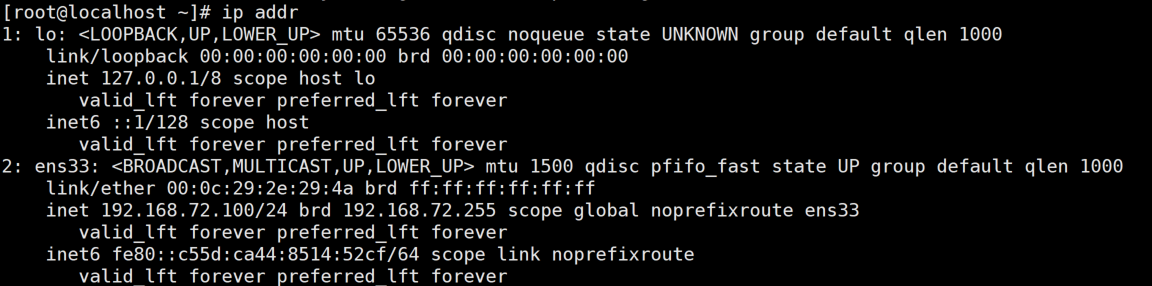
关闭防火墙
systemctl stop firewalld 关闭防火墙,systemctl status firewalld 查看防火墙状态
systemctl disable firewalld 关闭防火墙开机自启
关闭selinux服务
setenforce 0 临时关闭selinux服务,再通过 vi /etc/selinux/config 修改配置文件,将SELINUX字段更改为disabled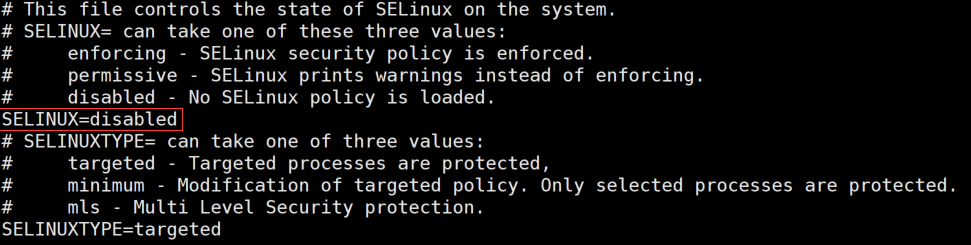
配置免密登录
建议先切换到root用户执行免密登录配置
ssh-keygen -t rsa 生成rsa秘钥对,出现选项直接回车选择默认即可。
ssh-copy-id root@本机的IP 由于是伪分布式,需要将刚刚的密钥对复制到本机,从而免去每次输入密码的步骤,途中需要输入当前账号的密码
至此,前期准备工作就完成了,可以在此拍摄快照,防止由于之后操作出现未知错误而重装虚拟机。
需要的软件
点击下列链接下载相应的软件资源。
jdk1.8.0_161
hadoop2.7.7
配置JDK
解压源码包
通过 tar -zxvf jdk-8u161-linux-x64.tar.gz -C /usr/local (-C 参数指定解压路径)将JDK的tar包解压到/usr/local/目录下
配置环境变量
vi /etc/profile 配置环境变量
在文件底部添加以下内容
JAVA_HOME=/usr/local/jdk1.8.0_161CLASSPATH=$JAVA_HOME/lib/PATH=$PATH:$JAVA_HOME/binexport PATH JAVA_HOME CLASSPATH
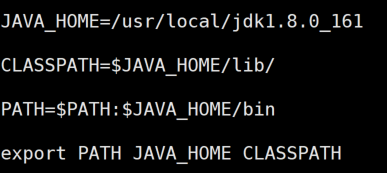
修改后执行 source /etc/profile 使配置生效
输入 java -version 测试JDK是否配置成功,若出现版本号则说明JDK配置成功

配置Hadoop
解压源码包
通过 tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local 解压tar包
修改配置文件
cd /usr/local/hadoop-2.7.7/etc/hadoop/ 进入目录 vi hadoop-env.sh 修改配置文件,指定JDK的路径
export JAVA_HOME=/usr/local/jdk1.8.0_161

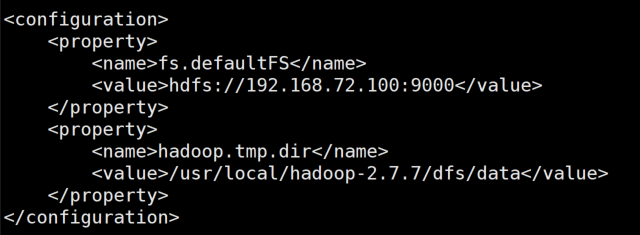
vi core-site.xml 修改配置文件,指定Hadoop的存储位置与访问IP
<property><name>fs.defaultFS</name><value>hdfs://本地IP:9000</value></property><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop-2.7.7/dfs/data</value></property>
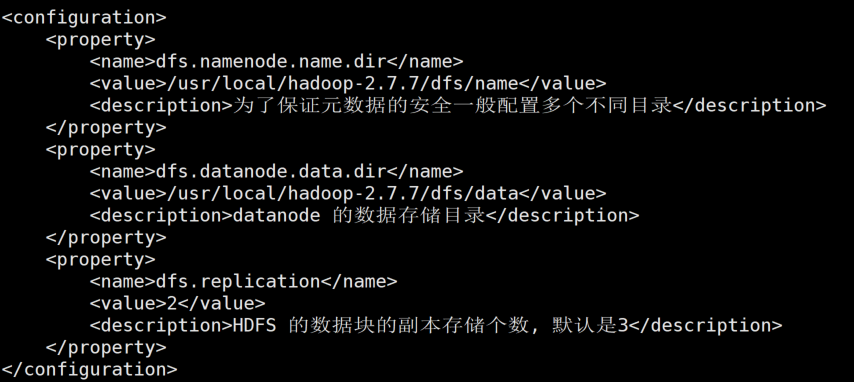
vi hdfs-site.xml 修改配置文件,配置hdfs的存储路径
<property><name>dfs.namenode.name.dir</name><value>/usr/local/hadoop-2.7.7/dfs/name</value><description>为了保证元数据的安全一般配置多个不同目录</description></property><property><name>dfs.datanode.data.dir</name><value>/usr/local/hadoop-2.7.7/dfs/data</value><description>datanode 的数据存储目录</description></property><property><name>dfs.replication</name><value>2</value><description>HDFS 的数据块的副本存储个数, 默认是3</description></property>
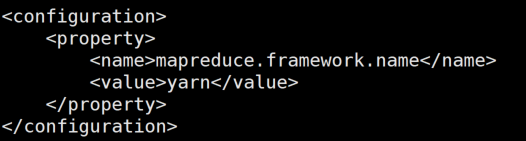
cp mapred-site.xml.template mapred-site.xml 将配置文件重命名,再 vi mapred-site.xml 修改配置文件,指定yarn作为资源调度组件。
<property><name>mapreduce.framework.name</name><value>yarn</value></property>
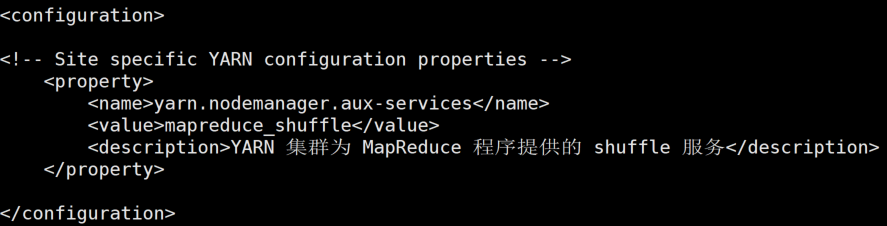
vi yarn-site.xml 修改配置文件,指定yarn为MapReduce组件服务。
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>YARN 集群为 MapReduce 程序提供的 shuffle 服务</description></property>
配置环境变量
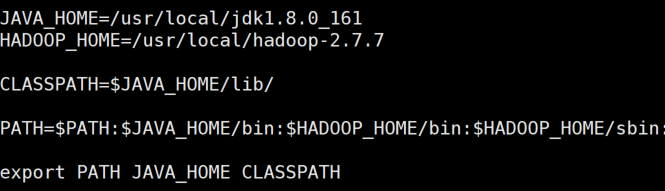
vi /etc/profile 配置环境变量
JAVA_HOME=/usr/local/jdk1.8.0_161HADOOP_HOME=/usr/local/hadoop-2.7.7CLASSPATH=$JAVA_HOME/lib/PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:export PATH JAVA_HOME CLASSPATH
修改后执行 source /etc/profile 使配置生效
输入 hadoop version 测试Hadoop是否配置成功,若出现版本号则说明Hadoop配置成功

创建目录
创建hdfs-site.xml里配置的路径,依次执行 mkdir -p /usr/local/hadoop-2.7.7/dfs/name 与 mkdir -p /usr/local/hadoop-2.7.7/dfs/data (-p参数为遍历创建文件夹,若上级文件夹不存在会依次进行创建)
启动Hadoop服务
运行 hadoop namenode -format 对namenode进行初始化,途中可能需要输入相应的信息,最终显示status 0 则表示初始化成功

cd /usr/local/hadoop-2.7.7/sbin/ 目录 运行 sh start-all.sh 启动Hadoop服务。
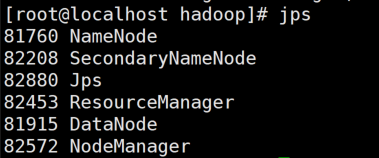
输入 jps 查看Hadoop的进程是否正常启动
在主机的浏览器中输入 ip:50070 进行访问Hadoop的web监控端,若能正常显示,则部署完成。若不能显示,先检查防火墙是否正常关闭。
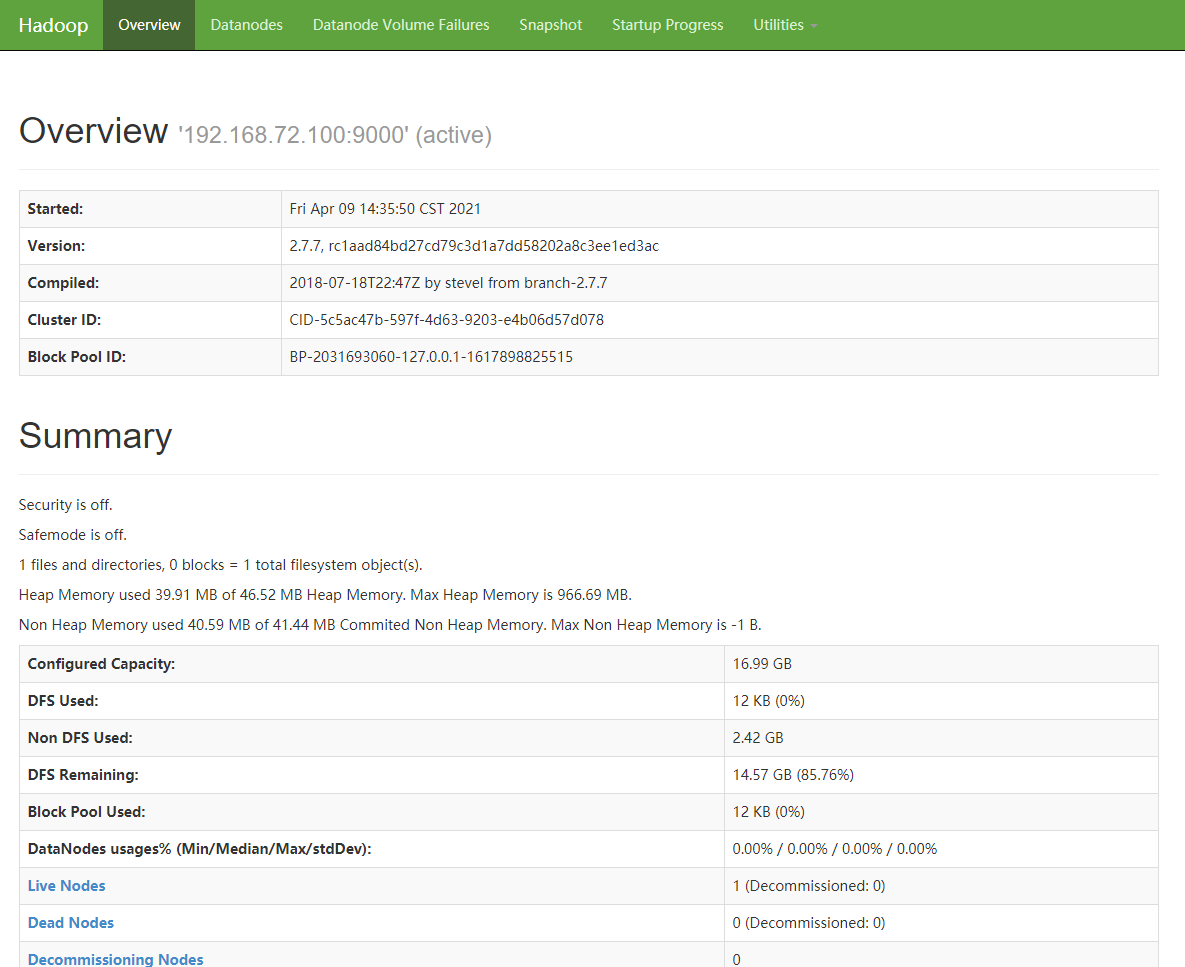
至此,Hadoop伪分布式部署就结束啦!
结语
如果说这篇文章有让你学到一定的知识的话,不妨点个赞和关注,让博主能够看到。如果讲解中有什么错误和疏忽,也劳烦在评论中指出或提问,博主会第一时间进行更新和答复,谢谢!




























")





还没有评论,来说两句吧...