VirtualBox + CentOS7 搭建 Hadoop 伪分布式模式
目录
一、准备好 CentOS7 的ISO 文件,JDK1.8 安装文件,hadoop-2.7 安装文件
二、安装CentOS7系统
三、CentOS7环境准备
1、关闭防火墙
2、安装 ifconfig 命令用于查看IP
3、将所jdk,hadoop文件传入linux系统
4、解压缩 jdk-8u281-linux-x64.tar.gz
5、配置jdk环境变量 vi /etc/profile 在最末未增加
6、检查jdk安装是否成功
7、免密码ssh设置
四、配置Hadoop
1、解压缩 hadoop-2.7.5.tar.gz
2、配置 hadoop-env.sh
3、配置 core-site.xml
4、配置 hdfs-site.xml
5、将Hadoop加入环境变量
6、格式化一个新的分布式文件系统
7、启动NameNode和DataNode守护进程
8、浏览Web界面以查找NameNode
9、关闭 Hadoop
五、在单节点上的YARN
1、配置 mapred-site.xml
2、配置 yarn-site.xml
3、启动ResourceManager守护程序和NodeManager守护程序
4、浏览Web界面以找到ResourceManager
5、停止守护进程
一、准备好 CentOS7 的ISO 文件,JDK1.8 安装文件,hadoop-2.7 安装文件
链接:https://pan.baidu.com/s/1lmA0Ai9ivPftJgC6DbpN7g
提取码:iw3g

二、安装CentOS7系统
没有截图的页面默认配置直接下一步


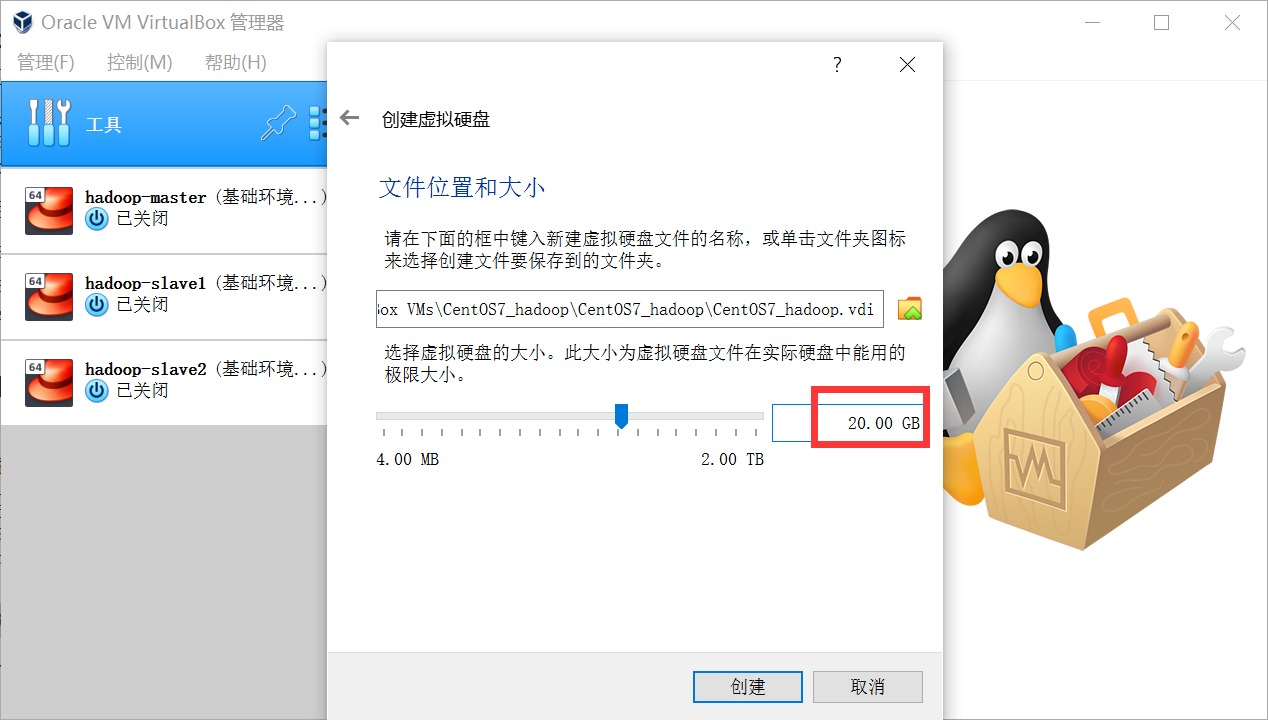







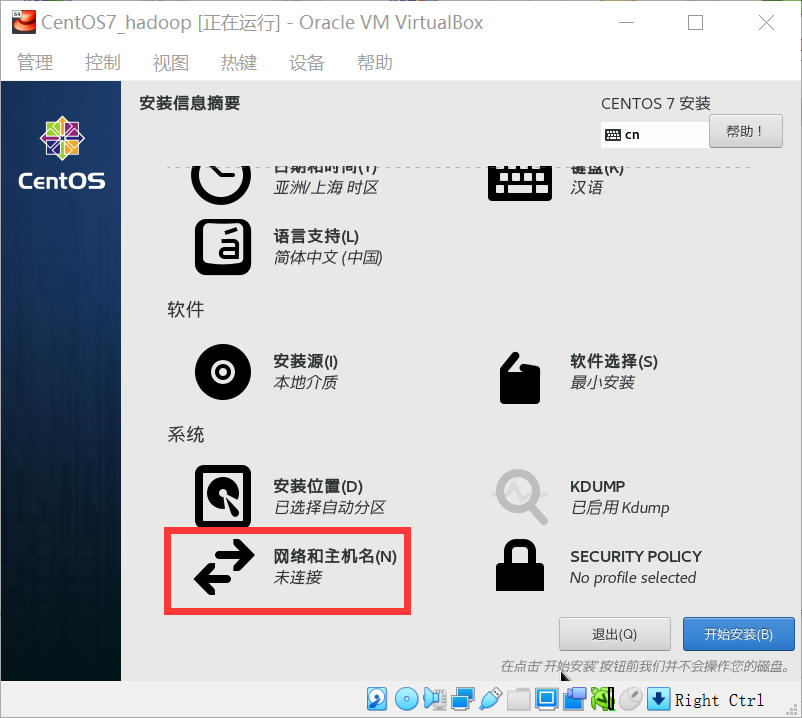



三、CentOS7环境准备
root 登录系统
1、关闭防火墙
查看当前防火墙状态 Active: active (running) 表示开启[root@centos7-hadoop sbin]# systemctl status firewalld.service关闭防火墙[root@centos7-hadoop sbin]# systemctl stop firewalld.service查看当前防火墙状态 Active: inactive (dead) 表示关闭[root@centos7-hadoop sbin]# systemctl status firewalld.service永久关闭防火墙[root@centos7-hadoop sbin]# systemctl disable firewalld.service
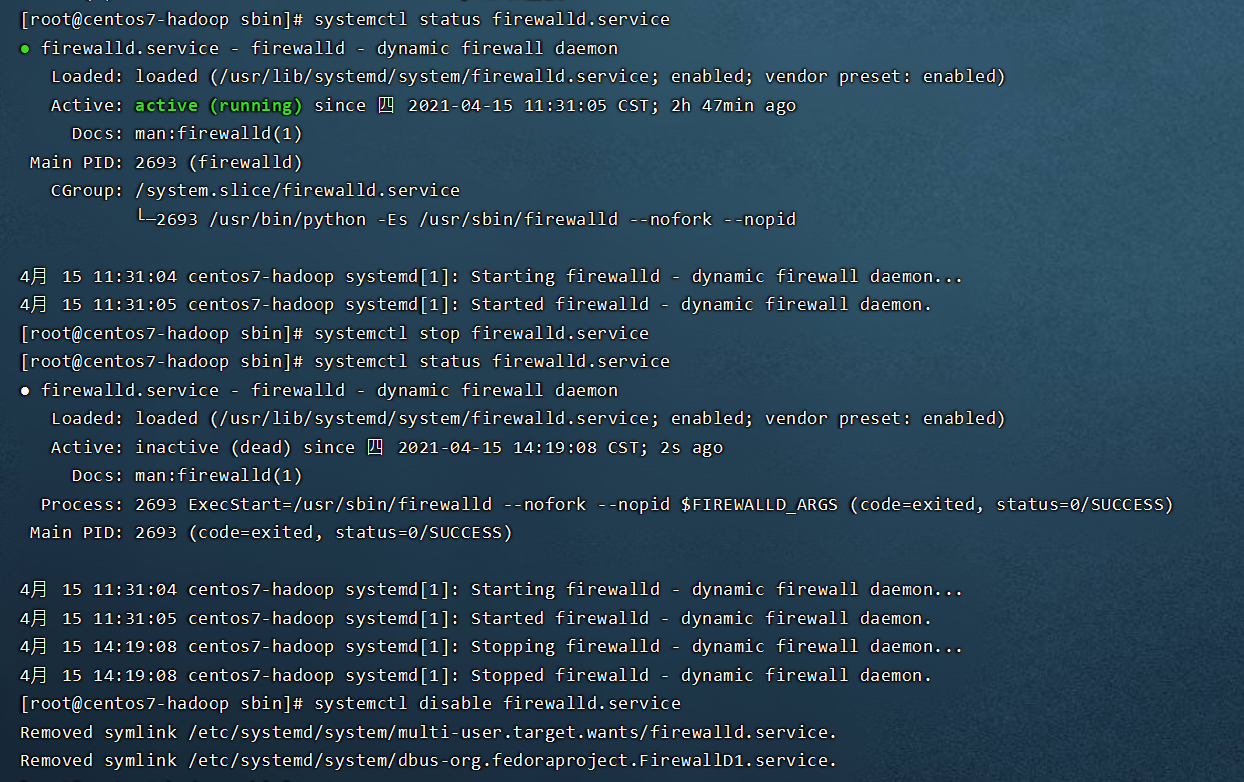
2、安装 ifconfig 命令用于查看IP


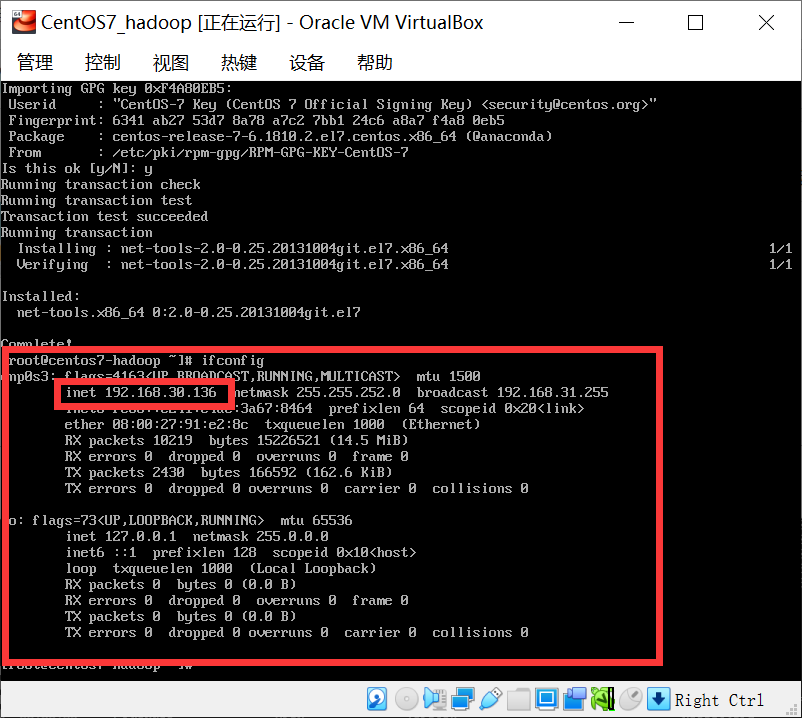
3、将所jdk,hadoop文件传入linux系统
jdk目录:/usr/java
hadoop目录:/opt/hadoop
目录不存在的情况先创建目录
4、解压缩 jdk-8u281-linux-x64.tar.gz
tar -zxvf jdk-8u281-linux-x64.tar.gz 到 /usr/java
5、配置jdk环境变量 vi /etc/profile 在最末未增加
#javaexport JAVA_HOME=/usr/java/jdk1.8.0_281export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib
6、检查jdk安装是否成功
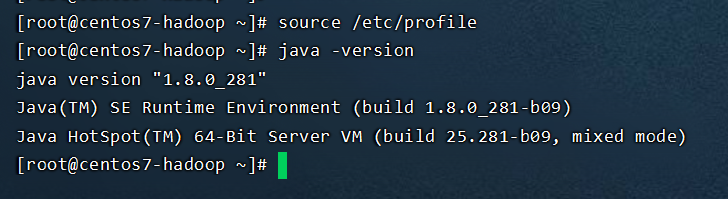
7、免密码ssh设置
现在确认能否不输入口令就用ssh登录localhost:
$ ssh localhost
如果不输入口令就无法用ssh登陆localhost,执行下面的命令:
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys$ chmod 0600 ~/.ssh/authorized_keys
四、配置Hadoop
1、解压缩 hadoop-2.7.5.tar.gz
tar -zxvf hadoop-2.7.5.tar.gz 到 /opt/hadoop
进入目录 /opt/hadoop/hadoop-2.7.5/
2、配置 hadoop-env.sh
vi /opt/hadoop/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
将 export JAVA_HOME=${JAVA_HOME}
改成 export JAVA_HOME=/usr/java/jdk1.8.0_281
3、配置 core-site.xml
vi /opt/hadoop/hadoop-2.7.5/etc/hadoop/core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://localhost:9000</value></property></configuration>
4、配置 hdfs-site.xml
vi /opt/hadoop/hadoop-2.7.5/etc/hadoop/hdfs-site.xml
<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>
5、将Hadoop加入环境变量
vi ~/.bash_profile 在文件最后加入
#HADOOPexport HADOOP_HOME=/opt/hadoop/hadoop-2.7.5export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
执行 source ~/.bash_profile 使环境变量生效
6、格式化一个新的分布式文件系统
$ bin/hdfs namenode -format
7、启动NameNode和DataNode守护进程
$ sbin/start-dfs.sh
8、浏览Web界面以查找NameNode
- NameNode- http://localhost:50070/
9、关闭 Hadoop
$ sbin/stop-dfs.sh
五、在单节点上的YARN
进入目录 /opt/hadoop/hadoop-2.7.5/
1、配置 mapred-site.xml
复制模板文件
cp /opt/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
编辑文件 vi /opt/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
2、配置 yarn-site.xml
编辑文件 vi /opt/hadoop/hadoop-2.7.5/etc/hadoop/yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
3、启动ResourceManager守护程序和NodeManager守护程序
$ sbin/start-yarn.sh
4、浏览Web界面以找到ResourceManager
ResourceManager - http://localhost:8088/
5、停止守护进程
$ sbin/stop-yarn.sh


































还没有评论,来说两句吧...