[Hadoop] Hadoop2.8.1 伪分布式部署
Hadoop2.8.1 伪分布式安装,需要先把Hadoop的源码包编译成tar包,或者直接下载已编译好的tar包,再来部署。
为分布式部署方式的HDFS NameNode、DataNode、Secondary NameNode以及Yarn的Resource Manager和Node Manager全部运行在同一台主机上,因此部署过程中只需要一台主机。
操作系统:CentOS7.3
- 准备环境
1.1 修改主机名并添加主机名到IP地址的映射
[root@localhost ~]# hostnamectl set-hostname hadoop01[root@localhost ~]# vi /etc/hosts写入192.168.1.8 hadoop01
重启主机
[root@localhost ~]# reboot
1.2 安装JDK
卸载系统自带的JDK7
[root@hadoop01 ~]# rpm -qa | grep -i javatzdata-java-2016g-2.el7.noarchjava-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64python-javapackages-3.4.1-11.el7.noarchjavamail-1.4.6-8.el7.noarchjavapackages-tools-3.4.1-11.el7.noarchjava-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64[root@hadoop01 ~]# cat /etc/redhat-releaseCentOS Linux release 7.3.1611 (Core)[root@hadoop01 ~]# rpm -e --nodeps tzdata-java-2016g-2.el7.noarch[root@hadoop01 ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.111-2.6.7.8.el7.x86_64[root@hadoop01 ~]# rpm -e --nodeps python-javapackages-3.4.1-11.el7.noarch[root@hadoop01 ~]# rpm -e --nodeps javamail-1.4.6-8.el7.noarch[root@hadoop01 ~]# rpm -e --nodeps javapackages-tools-3.4.1-11.el7.noarch[root@hadoop01 ~]# rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.111-2.6.7.8.el7.x86_64[root@hadoop01 ~]# rpm -qa | grep -i java[root@hadoop01 ~]# java -version-bash: java: command not found[root@hadoop01 ~]#
安装JDK8
[root@hadoop01 software]# cd[root@hadoop01 ~]# mkdir /usr/java[root@hadoop01 ~]# cp /opt/software/jdk-8u45-linux-x64.gz /usr/java/[root@hadoop01 ~]# cd /usr/java/[root@hadoop01 java]# tar -zxvf jdk-8u45-linux-x64.gz[root@hadoop01 java]# chown -R root:root jdk1.8.0_45/ # 注意Linux下解压出来的文件夹属主
配置环境变量
[root@hadoop01 jdk1.8.0_45]# vi /etc/profile# 写入export JAVA_HOME=/usr/java/jdk1.8.0_45/export PATH=$PATH:$JAVA_HOME/bin# 让配置生效[root@hadoop01 jdk1.8.0_45]# source /etc/profile[root@hadoop01 jdk1.8.0_45]# java -versionjava version "1.8.0_45"Java(TM) SE Runtime Environment (build 1.8.0_45-b14)Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)[root@hadoop01 jdk1.8.0_45]#
1.3 创建hadoop用户组和用户
[root@hadoop01 ~]# groupadd hadoop[root@hadoop01 ~]# useradd -d /home/hadoop -g hadoop hadoop[root@hadoop01 ~]# passwd hadoop[root@hadoop01 ~]# id hadoopuid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)[root@hadoop01 ~]#
配置hadoop用户ssh到本机免密
[root@hadoop01 ~]# su - hadoopLast login: Tue May 22 09:21:15 EDT 2018 on pts/0[hadoop@hadoop01 ~]$ ssh-keygen[hadoop@hadoop01 ~]$ cat .ssh/id_rsa.pub >> .ssh/authorized_keys[hadoop@hadoop01 ~]$ chmod 600 .ssh/authorized_keys[hadoop@hadoop01 ~]$ ssh hadoop01 dateThe authenticity of host 'hadoop01 (192.168.1.8)' can't be established.ECDSA key fingerprint is c4:8b:d9:92:fe:e2:85:dd:1e:06:dd:d7:e5:9e:a5:c4.Are you sure you want to continue connecting (yes/no)? yesWarning: Permanently added 'hadoop01,192.168.1.8' (ECDSA) to the list of known hosts.Tue May 22 05:33:18 EDT 2018[hadoop@hadoop01 ~]$ exitlogout[root@hadoop01 ~]#
- Hadoop伪分布式部署
2.1 解压Hadoop
拷贝编译完成的Hadoop tar包(或者直接下载编译好的tar包)到指定路径下解压
[root@hadoop01 software]# tar -zxvf hadoop-2.8.1.tar.gz
配置环境变量
[root@hadoop01 hadoop-2.8.1]# vi /etc/profile# 写入export HADOOP_HOME=/opt/software/hadoop-2.8.1export PATH=$HADOOP_HOME/bin:$JAVA_HOME/bin:$PATH# 让配置生效[root@hadoop01 hadoop-2.8.1]# source /etc/profile[root@hadoop01 hadoop-2.8.1]# hadoop versionHadoop 2.8.1Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 20fe5304904fc2f5a18053c389e43cd26f7a70feCompiled by vinodkv on 2017-06-02T06:14ZCompiled with protoc 2.5.0From source with checksum 60125541c2b3e266cbf3becc5bda666This command was run using /opt/software/hadoop-2.8.1/share/hadoop/common/hadoop-common-2.8.1.jar[root@hadoop01 hadoop-2.8.1]#
2.2 修改Hadoop配置文件
配置core-site.xm
[root@hadoop01 hadoop-2.8.1]# pwd/opt/software/hadoop-2.8.1[root@hadoop01 hadoop-2.8.1]# vi etc/hadoop/core-site.xml# 写入配置<configuration><property><name>fs.defaultFS</name><value>hdfs://l92.168.1.8:9000</value> # 官网拷贝下来的配置为localhost,改为自己主机的IP地址,配置nn对外提供服务</property></configuration>
配置hdfs-site.xml
[root@hadoop01 hadoop-2.8.1]# vi etc/hadoop/hdfs-site.xml# 写入配置<configuration><property><name>dfs.replication</name><value>1</value> # 生产集群环境,默认副本数写3. 伪分布式模式只有一台主机,副本数写1</property><property><name>dfs.namenode.secondary.http-address</name><value>192.168.1.8:50090</value> # 配置snn对外提供服务</property><property><name>dfs.namenode.secondary.https-address</name><value>192.168.1.8:50091</value> # 配置snn对外提供服务</property></configuration>
配置slaves(配置dn对外提供服务)
[root@hadoop01 hadoop-2.8.1]# vi etc/hadoop/slaves# 修改localhost为自己主机的IP地址192.168.1.8
配置hadoop-env.sh(配置JAVA_HOME)
[root@hadoop01 hadoop-2.8.1]# vi etc/hadoop/hadoop-env.sh# 写入配置export JAVA_HOME=/usr/java/jdk1.8.0_45
最终我们会以haoop用户(不用root)来运行Hadoop服务,先把hadoop安装路径的属主设为hadoop用户,然后用hadoop用户来启动hdfs。
2.3 修改hadoop安装路径的属主为hadoop
[root@hadoop01 software]# cd /opt/software/[root@hadoop01 software]# chown -R hadoop:hadoop hadoop-2.8.1[root@hadoop01 software]# ls -ld hadoop-2.8.1drwxrwxr-x. 9 hadoop hadoop 149 Jun 2 2017 hadoop-2.8.1[root@hadoop01 software]#
2.4 格式化hdfs
切换到hadoop用户
[root@hadoop01 ~]# su - hadoopLast login: Tue May 22 09:22:54 EDT 2018 on pts/0[hadoop@hadoop01 ~]$
格式化hdfs
[hadoop@hadoop01 ~]$ hdfs namenode -format
2.5 启动hdfs
[hadoop@hadoop01 ~]$ /opt/software/hadoop-2.8.1/sbin/start-dfs.shStarting namenodes on [hadoop01]hadoop01: starting namenode, logging to /opt/software/hadoop-2.8.1/logs/hadoop-hadoop-namenode-hadoop01.out192.168.1.8: starting datanode, logging to /opt/software/hadoop-2.8.1/logs/hadoop-hadoop-datanode-hadoop01.outStarting secondary namenodes [hadoop01]hadoop01: starting secondarynamenode, logging to /opt/software/hadoop-2.8.1/logs/hadoop-hadoop-secondarynamenode-hadoop01.out[hadoop@hadoop01 ~]$ jps3683 Jps3206 NameNode # hdfs正常启动后jps可以看到NN,SNN,DN三个进程3513 SecondaryNameNode3341 DataNode[hadoop@hadoop01 ~]$
同时,可以通过浏览器的50070端口访问hdfs的Web UI:http://192.168.1.8:50070/
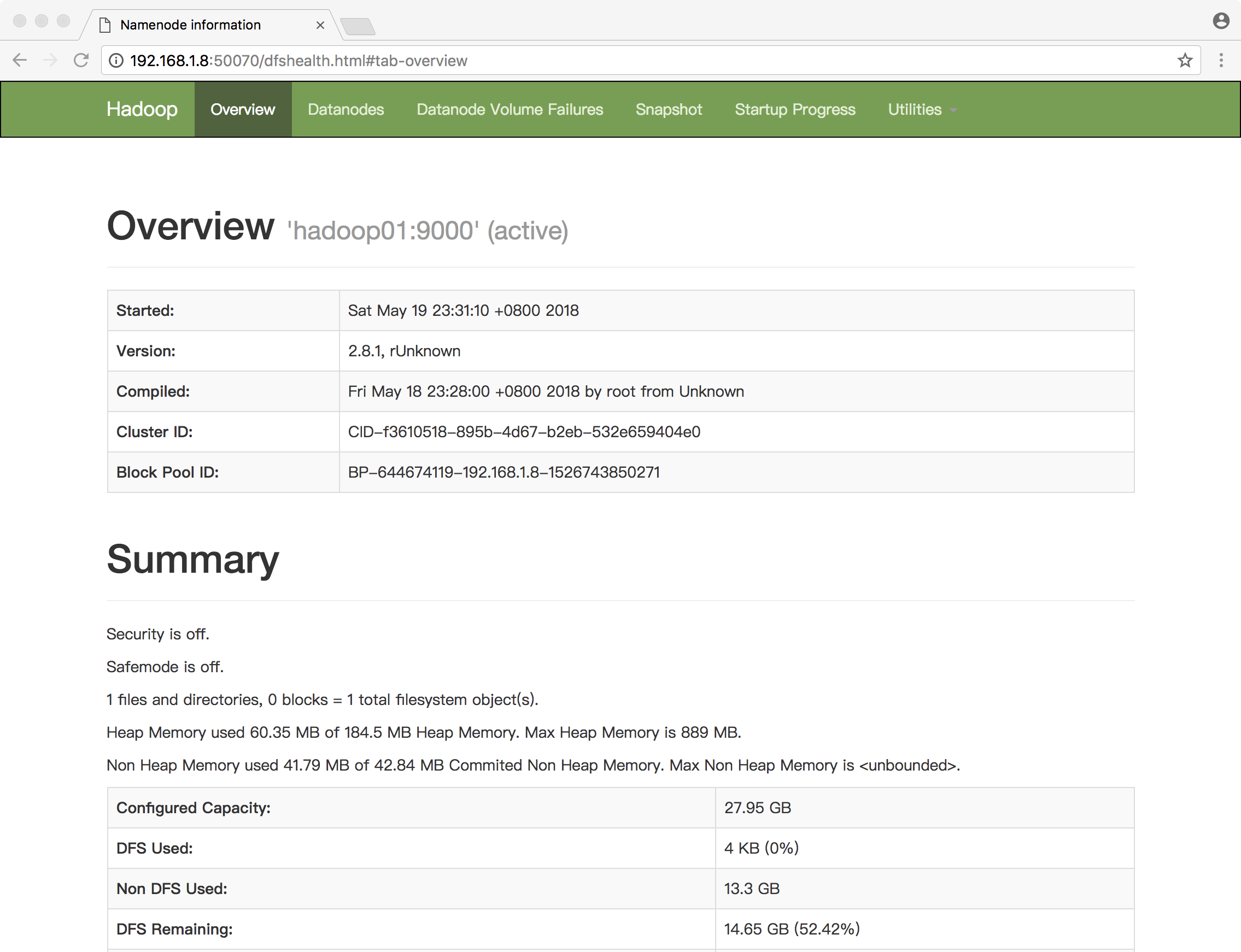
至此,用hadoop用户启动hdfs完成。
2.6 Yarn伪分布式部署
配置mapred-site.xml
[hadoop@hadoop01 hadoop-2.8.1]$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml[hadoop@hadoop01 hadoop-2.8.1]$ vi etc/hadoop/mapred-site.xml# 写入配置<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
配置yarn-site.xml
[hadoop@hadoop01 hadoop-2.8.1]$ vi etc/hadoop/yarn-site.xml# 写入配置<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
启动Yarn
[hadoop@hadoop01 hadoop-2.8.1]$ sbin/start-yarn.shstarting yarn daemonsstarting resourcemanager, logging to /opt/software/hadoop-2.8.1/logs/yarn-hadoop-resourcemanager-hadoop01.out192.168.1.8: starting nodemanager, logging to /opt/software/hadoop-2.8.1/logs/yarn-hadoop-nodemanager-hadoop01.out[hadoop@hadoop01 hadoop-2.8.1]$ jps4371 Jps3206 NameNode4071 NodeManager3513 SecondaryNameNode3341 DataNode3967 ResourceManager # 可以看到yarn启动后多了两个进程:ResourceManager和NodeManager[hadoop@hadoop01 hadoop-2.8.1]$
同样可以通过Yarn的Web UI页面查看Yarn服务:http://192.168.1.8:8088/
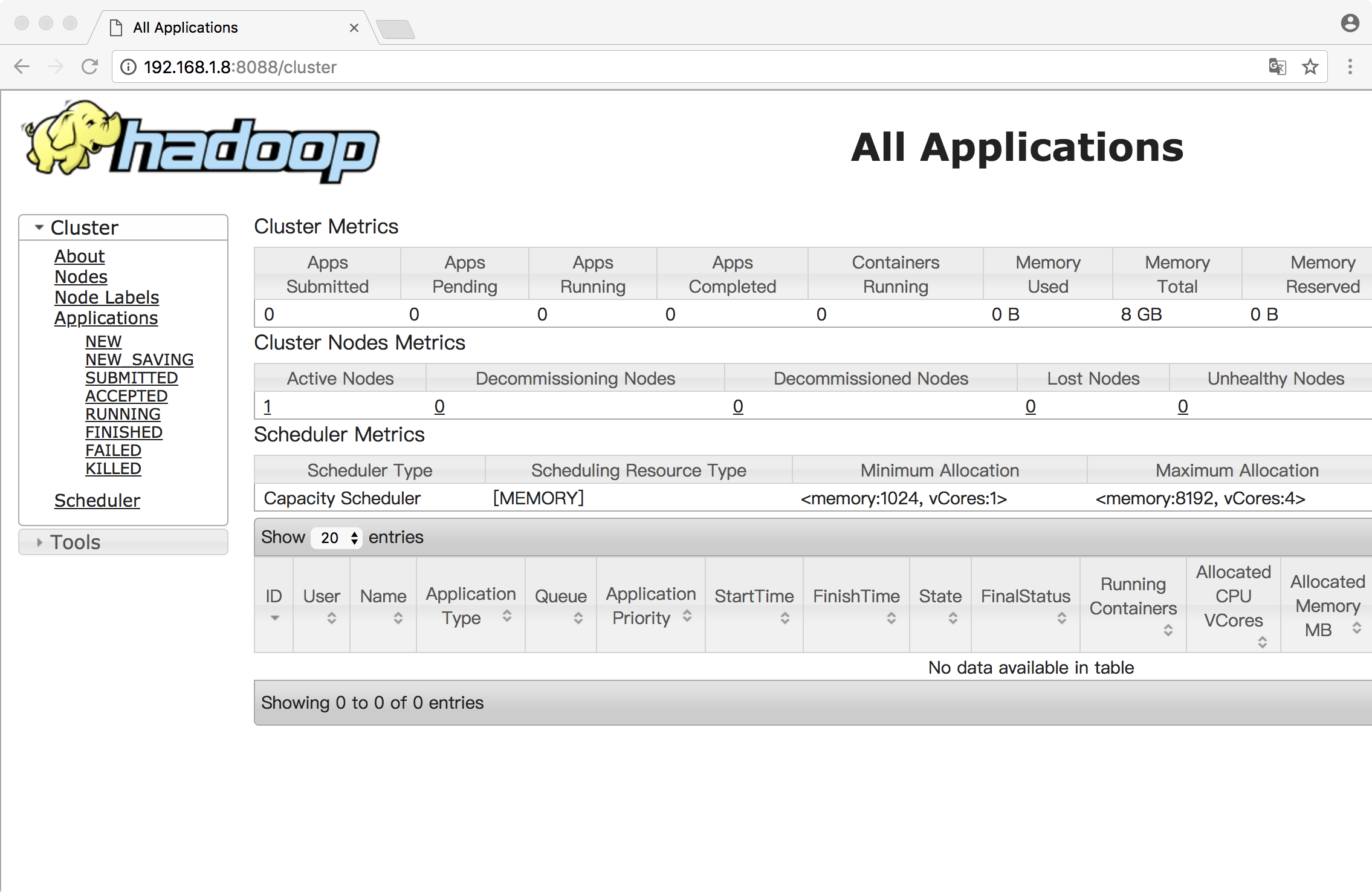
2.7 运行一个MapReduce job
MapReduce本身并不启动任何java进程,只有向hdfs提交jar任务时才产生任务进程。
启动一个MapReduce任务
[hadoop@hadoop01 hadoop-2.8.1]$ hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar pi 5 20Number of Maps = 5Samples per Map = 20Wrote input for Map #0Wrote input for Map #1Wrote input for Map #2Wrote input for Map #3Wrote input for Map #4Starting Job18/05/22 09:40:31 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:803218/05/22 09:40:32 INFO input.FileInputFormat: Total input files to process : 518/05/22 09:40:32 INFO mapreduce.JobSubmitter: number of splits:518/05/22 09:40:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1526996199577_000118/05/22 09:40:33 INFO impl.YarnClientImpl: Submitted application application_1526996199577_000118/05/22 09:40:33 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1526996199577_0001/18/05/22 09:40:33 INFO mapreduce.Job: Running job: job_1526996199577_000118/05/22 09:40:41 INFO mapreduce.Job: Job job_1526996199577_0001 running in uber mode : false18/05/22 09:40:41 INFO mapreduce.Job: map 0% reduce 0%18/05/22 09:40:51 INFO mapreduce.Job: map 100% reduce 0%18/05/22 09:40:57 INFO mapreduce.Job: map 100% reduce 100%18/05/22 09:40:58 INFO mapreduce.Job: Job job_1526996199577_0001 completed successfully18/05/22 09:40:58 INFO mapreduce.Job: Counters: 49File System CountersFILE: Number of bytes read=116FILE: Number of bytes written=819909FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=1345HDFS: Number of bytes written=215HDFS: Number of read operations=23HDFS: Number of large read operations=0HDFS: Number of write operations=3Job CountersLaunched map tasks=5Launched reduce tasks=1Data-local map tasks=5Total time spent by all maps in occupied slots (ms)=34336Total time spent by all reduces in occupied slots (ms)=3669Total time spent by all map tasks (ms)=34336Total time spent by all reduce tasks (ms)=3669Total vcore-milliseconds taken by all map tasks=34336Total vcore-milliseconds taken by all reduce tasks=3669Total megabyte-milliseconds taken by all map tasks=35160064Total megabyte-milliseconds taken by all reduce tasks=3757056Map-Reduce FrameworkMap input records=5Map output records=10Map output bytes=90Map output materialized bytes=140Input split bytes=755Combine input records=0Combine output records=0Reduce input groups=2Reduce shuffle bytes=140Reduce input records=10Reduce output records=0Spilled Records=20Shuffled Maps =5Failed Shuffles=0Merged Map outputs=5GC time elapsed (ms)=1073CPU time spent (ms)=3480Physical memory (bytes) snapshot=1536045056Virtual memory (bytes) snapshot=12665720832Total committed heap usage (bytes)=1157627904Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format CountersBytes Read=590File Output Format CountersBytes Written=97Job Finished in 26.73 secondsEstimated value of Pi is 3.20000000000000000000[hadoop@hadoop01 hadoop-2.8.1]$
在Yarn的页面上可以看到对应的maoreduce作业执行状况
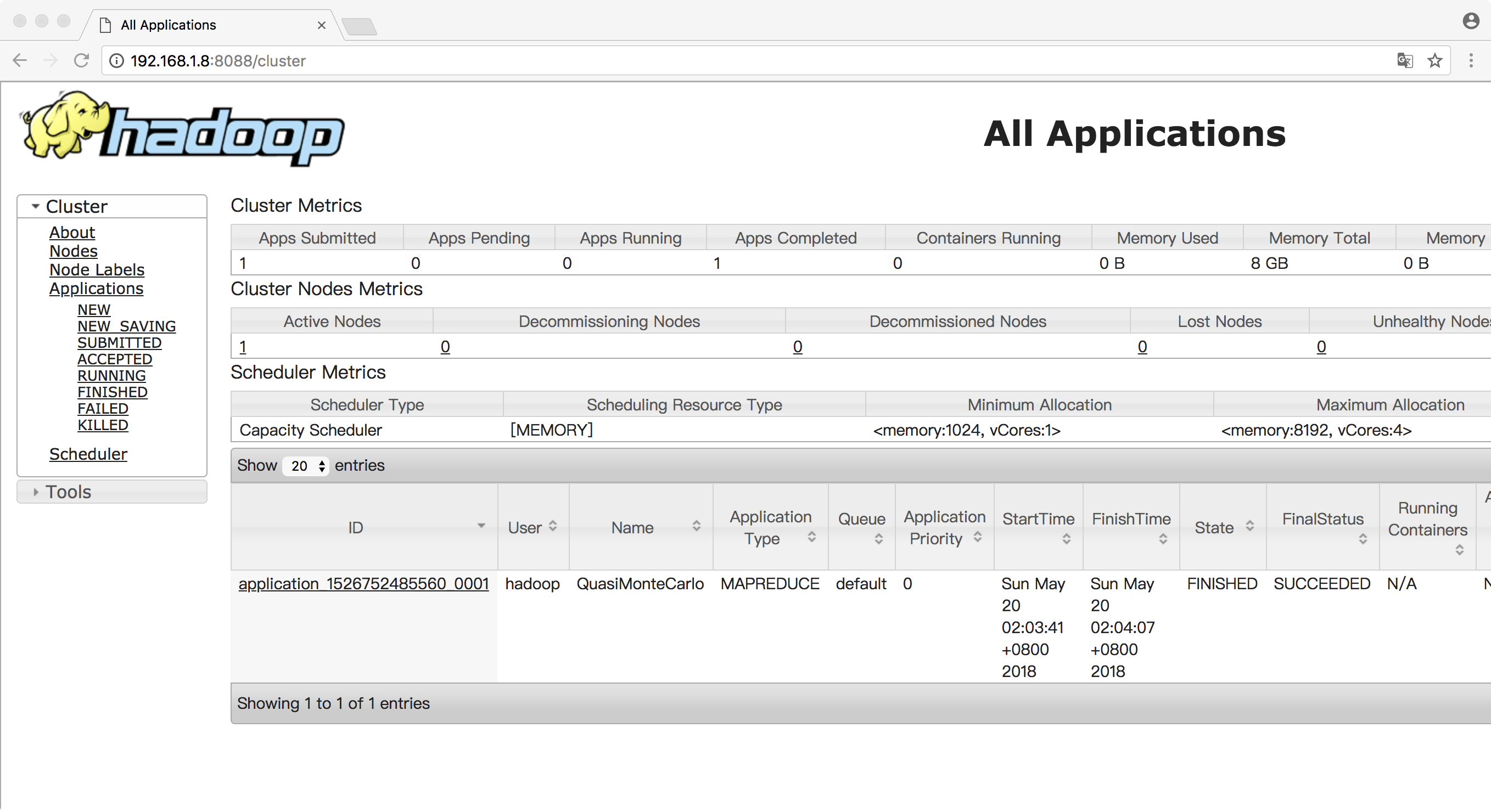
至此,整个Hadoop伪分布式环境部署完成。
注意事项:
- 单机模式中,Hadoop是没有进程的,只有用户在提交作业运行时才会产生进程;
- 伪分布式模式中,每个Hadoop进程运行在一个独立的java进程;
- 学习时,用最大权限用户root,避免造成不必要的问题;
- 单机/集群要对外提供服务时,需要配置的localhost为IP地址;
- 重新部署HDFS时,要先删除/tmp/下产生的临时文件,再格式化hdfs,再启动;
- Web UI页面远程无法访问时,检查防火墙;
- 核心配置文件去官方文档查看。


































还没有评论,来说两句吧...