MySql模糊查询性能优化
先看例子:
通用模糊查询操作:
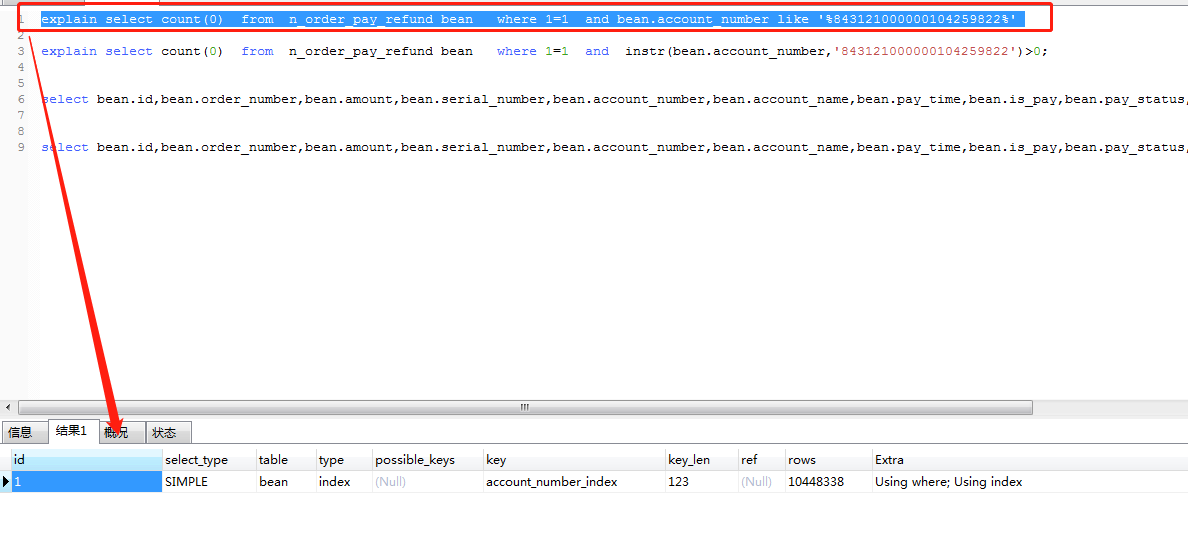
select * from n_order_pay_refund bean where 1=1 and bean.account_number like ‘%843121000000104259822%’ order by bean.pay_time
调用instr()函数:
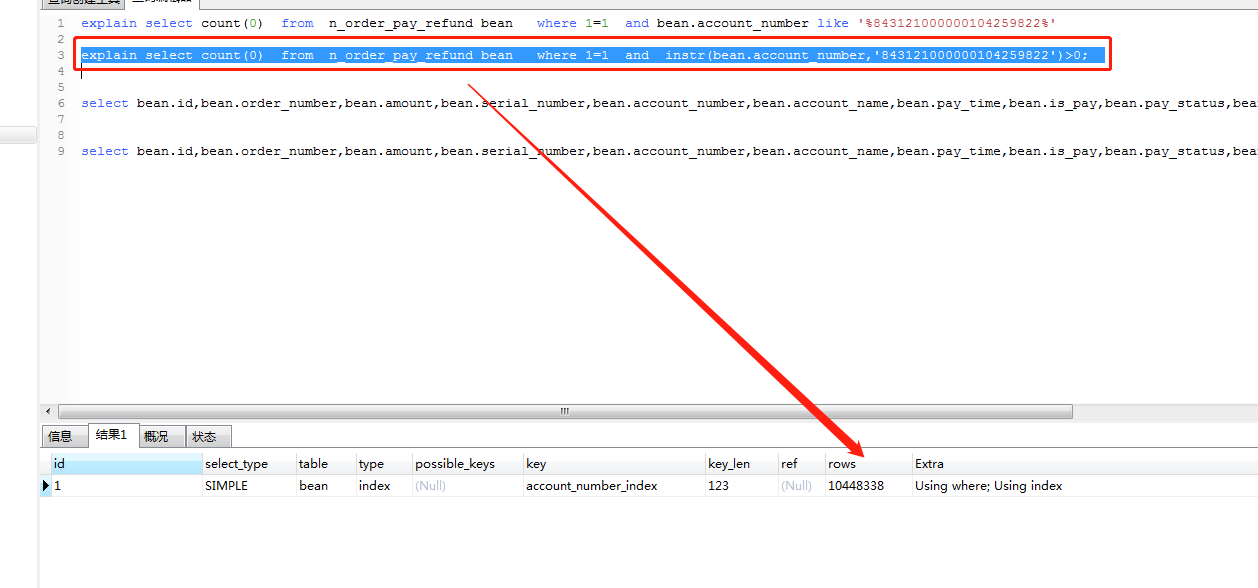
select * from n_order_pay_refund bean where 1=1 and instr(bean.account_number,’843121000000104259822’)>0 order by bean.pay_time
利用explain可以看出上面两个查询的访问行数是一致的。
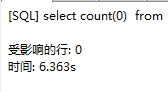
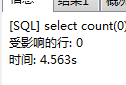
但执行sql之后查看信息相比确实快了两秒。
like
instr()
INSTR(STR,SUBSTR) 在一个字符串(STR)中搜索指定的字符(SUBSTR),返回发现指定的字符的位置(INDEX);
STR 被搜索的字符串
SUBSTR 希望搜索的字符串
结论:在字符串STR里面,字符串SUBSTR出现的第一个位置(INDEX),INDEX是从1开始计算,如果没有找到就直接返回0,没有返回负数的情况。
其实instr( )项目中的实际应用,查看用户注册创建的用户名是否包含敏感词汇其中,INSTR(),中的第一个为传入的用户名,第二个为敏感词库的表.

























——管道符")
——通配符与其他特殊符号")


地图制作")




还没有评论,来说两句吧...