【MySQL】MySQL优化提高查询性能
1.MySQL 执行计划分析
1. 查看 SQL 执行计划:
explain SQL;
在查看执行计划(explain)时, Extra 列为 Using index 则表示优化器使用了覆盖索引。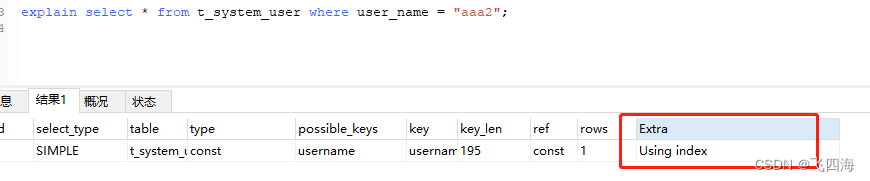
一般建议优先考虑使用覆盖索引,这是因为如果 SQL 需要查询辅助索引中不包含的数据列时,就需要先通过辅助索引查找到主键值,然后再回表通过主键查询到其他数据列(即回表查询),需要查询两次。而覆盖索引能从索引中直接获取查询需要的所有数据,从⽽避免回表进行二次查找,节省IO,效率较⾼。
select_type 类型:
- simple:简单查询,不包含子查询和 union; primary:复杂查询的最外层查询;
- subquary:包含在select中不包含在from的子查询;
- derived:包含在from中的子查询,mysql会把这些数据放到临时表中,也称为派生查询;
- union:在union中第二个和随后的select。
type 类型:
- NULL:MySQL在优化阶段分解查询语句,在执行阶段不需要访问索引树或表的查询类型
- system:这是常量的特殊情况。当表中只有一条数据时,常量查询为system
- const:MySQL优化了查询的一部分,并将其转换为常量。将主键与常量进行比较时,表最多返回一条记录。
- eq_ref:当主键或非主键索引的所有部分都被引用时,最多只返回一条记录。简单选择查询不会显示此类型。
- ref:使用唯一索引是不实际的。如果使用公共索引或唯一索引的前缀部分,则与值进行比较时,索引可能会返回多行
- range:范围扫描,in between
- index:可以通过扫描整个索引获得结果。通常,扫描二级索引。此扫描不会从根节点开始快速搜索,而是直接扫描辅助索引的子节点。速度相对较慢。这种查询通常用于覆盖索引。次要索引通常较小,比所有索引都快
- All:全表扫描,扫描聚集索引的所有单词节点。通常,这种情况需要优化。
extra类型:
- 通常性能排序的结果是 usd index > use where > use filsort
2. 通过 Profile 定位 QUERY 代价消耗:
set profiling=1;-- 执行 SQL;show profiles; 获取 Query_ID。show profile for query Query_ID; -- 查看详细的 profile 信息;-- 参数:-- Sending data:从服务端发送到客户端的数据,数据量大时会出现耗时长情况。show profile cpu for query Query_ID;-- CPU_user:当前用户占用的 CPU;-- CPU_system:当前系统占用的CPU。set profiling=0;-- 关了
案例:
set profiling=1;select * from t_system_user;show profiles;SHOW profile CPU,BLOCK IO FOR query 487;set profiling=0;

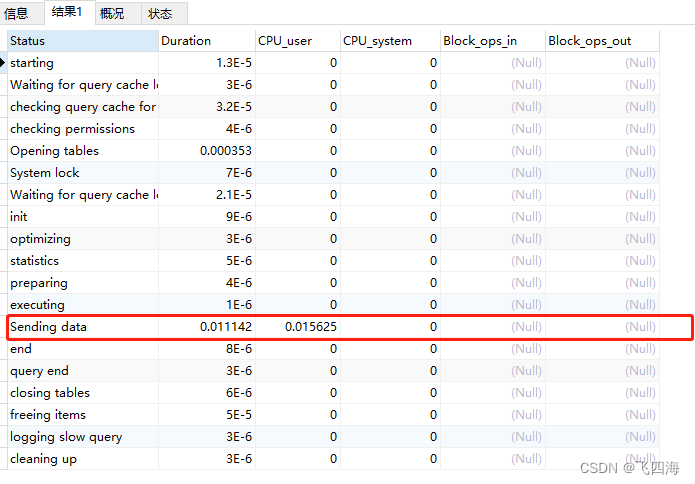
解释:
starting:开始checking permissions:检查权限Opening tables:打开表init : 初始化System lock :系统锁optimizing : 优化statistics : 统计preparing :准备executing :执行Sending data :发送数据Sorting result :排序end :结束query end :查询 结束closing tables : 关闭表 /去除TMP 表freeing items : 释放物品cleaning up :清理
3. 通过 Optimizer Trace 表查看 SQL 执行计划树:
- 注意:mariadb直到10.4版本才有Optimizer Trace, 之前的版本执行’SET optimizer_trace=‘enabled=on’; ‘会返回错误
我的:mysql Ver 14.14 Distrib 5.5.61, for Win64 (AMD64) 版本低用不了,公司的可以,自己试试吧
set session optimizer_trace=’enabled=on’;
执行 SQL;
SELECT trace FROM information_schema.OPTIMIZER_TRACE; — 获取 SQL 查询计划树;
set session optimizer_trace=’enabled=off’;— 开启此项影响性能,记得用后关闭。
2.Mysql相关参数(慢查询)
首先,MySQL 可以通过设置一些参数,将运行时间长或者非索引查找的 SQL 记录到慢查询文件中。可以分析慢查询文件中的 SQL,有针对性的进行优化。
- 参数 slow_query_log,表示是否开启慢查询日志,ON 或者 1 表示开启,OFF 或者 0 表示关闭。
- 参数 long_query_time,设置慢查询的阈值,MySQL 5.7 版本支持微秒级。
- 参数 slow_query_log_file,慢查询文件的存放路径。
- 参数 log_queries_not_using_indexes,表示是否将非索引查找的 SQL 也记录到慢查询文件中。
- 参数 log_throttle_queries_not_using_indexes,表示每分钟记录到慢查询文件中未使用索引的 SQL 语句上限,0 表示没限制。
- 参数 max_execution_time,用来控制 SELECT 语句的最大执行时间,单位毫秒,超过此值MySQL 自动 kill 掉该查询。
慢查询文件中记录包括了慢 SQL 产生的时间,SQL 源自的 IP 和对应的数据库用户名,以及访问的数据库名称;查询的总耗时,被 lock 的时间,结果集行数,扫描的行数,以及字节数等。当然还有具体的 SQL 语句。
3.如何优化 SQL
- 全表扫描还是索引扫描。
- 创建索引,在选择度高的列上创建索引。
- 多表关联的 SQL,在关联列上要有索引且字段类型一致,在优化 SQL 时需要重点排查这种情况。注意:索引列上使用函数也不会涉及索引。
- 创建索引以后,尽量不要过频修改。
- 多表关联时,尽量让结果集小的表作为驱动表,注意是结果集小的表,不是小表。
- 在日常中你会发现全模糊匹配的查询,由于 MySQL 的索引是 B+ 树结构,所以当查询条件为全模糊时,例如‘%**%’,索引无法使用,这时需要通过添加其他选择度高的列或者条件作为一种补充,从而加快查询速度。
- order by/group by 的 SQL 涉及排序,尽量在索引中包含排序字段,并让排序字段的排序顺序与索引列中的顺序相同,这样可以避免排序或减少排序次数。比如:where a=? order by b,c,就可以创建一个索引 (a,b,c)
- 不要总想着用一个SQL 解决所有事情;最烦同事写一大堆sql
4.基础数据库sql编写规范
- SELECT 只获取必要的字段,禁止使用 SELECT *。这样能减少网络带宽消耗,有效利用覆盖索引,表结构变更对程序基本无影响。
- 用 IN 代替 OR。SQL 语句中 IN 包含的值不宜过多,应少于 1000 个。过多会使随机 IO 增大,影响性能。
- 禁止使用 order by rand()。order by rand() 会为表增加几个伪列,然后用 rand() 函数为每一行数据计算 rand() 值,最后基于该行排序,这通常都会生成磁盘上的临时表,因此效率非常低。建议先使用 rand() 函数获得随机的主键值,然后通过主键获取数据。
- SQL 中避免出现 now()、rand()、sysdate()、current_user() 等不确定结果的函数。在语句级复制场景下,引起主从数据不一致;不确定值的函数,产生的 SQL 语句无法使用 QUERY CACHE。
- 重要SQL必须被索引:update、delete 的 where 条件列、order by、group by、distinct 字段、多表 join 字段。
- 禁止使用 % 前导查询,例如:like “%abc”,⽆法利⽤到索引。
- 禁止使⽤负向查询,例如:not in、!=、<>、not like。
- 使⽤ EXPLAIN 判断 SQL 语句是否合理使用索引,尽量避免 extra 列出现:Using File Sort、Using Temporary 等。
- 减少与数据库交互次数,尽量采用批量 SQL 语句。
- 获取大量数据时,建议分批次获取数据,每次获取数据少于 5000 条,结果集应小于 1M。
- 拆分复杂 SQL 为多个 小SQL,避免⼤事务。简单的 SQL 容易使用到 MySQL 的 QUERY CACHE;减少锁表时间特别是 MyISAM;可以使用多核 CPU。
5.应用层性能优化
除了对 MySQL 优化外,还有常用的缓存技术 Memcached、Redis、Codis、Pika、Aerospike 等,还需要知道常用的消息队列 Kafka、RabbitMQ、Redis Stream 数据结构等,还有常用的全文索引工具 Elasticsearch、Solr、sphinx 等,大数据系统 HBase、Spark、Druid 等等,都可以最为优化手段。






























、methods、watch的区别")



还没有评论,来说两句吧...