分布式搜索引擎ElasticSearch
学习的目标
安装ElasticSearch,并且可以使用RestAPI进行基本的增删改查操作
Head插件的安装,也就是ElasticSearch的客户端,并掌握他的使用方法
安装IK分词器,使用IK分词器进行分词
使用SpringDataElasticSerach完成搜索微服务
logstash完成mysql与ElasticSearch的同步
一、ElasticSearch:
特点:
- 可以作为一个大型分布式集群技术,处理pb级别的数据。
- 全文检索,数据分析以及分布式技术整合在一起
体系结构
ElasticSearch也是需要存储数据的,只不过和mysql数据库相比他是以文档(Documnet)形式来进行存储的,下面就是他和mysql的对比
| ElasticSearch | 关系型数据库mysql |
| 索引(index) | 数据库(database) |
| 类型(type) | 表(table) |
| 文档(Document) | 数据(value) |
安装部署:
下载ElasticSearch 5.6.8的版本 链接 下载路径
下载完成之后直接解压(无空格,无中文字的地方)进入到他的bin目录下,window+r 在cmd下输入 elasticsearch

上面红线表的9300的端口是java进行操作的,9200是其他用来操作的端口
打开浏览器,地址栏输入 localhost:9200
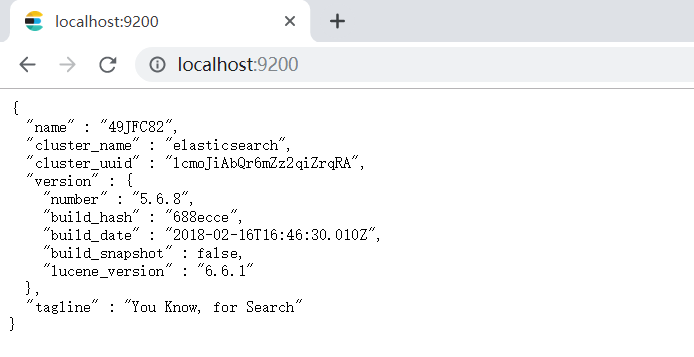
这样就显示你的ElasticSearch安装和启动成功
安装启动已经完成了,接下来我们使用postman调用RestAPI
新建索引(相当于创建一个数据库)
创建一个叫articindex,用put的方式进行创建localhost:9200/articindex/
新建文档(相当于创建了一个表,并在表里面添加了数据) post方式
localhost:9200/articindex/articbody:\{"title":"SpringBoot2.0","content":"发布啦\}数据是以json的格式进行保存的
执行结果为:

其中\_id是由系统自动生成的
查询 get方式 关键字 _search
路径 localhost:9200/articindex/artic/\_search返回的结果如图所示

修改文档 put方式
localhost:9200/articindex/artic/ \_id :所要修改的id号body中写上要修改的内容
如果id不存在,那么他会自动创建一个
说一下他的高级查询
1.基本匹配
http://192.168.184.134:9200/articleindex/article/\_search?q=title:零基础入门
2.模糊查询
http://192.168.184.134:9200/articleindex/article/_search?q=title:*s*
3.删除文档
[http://192.168.184.134:9200/articleindex/article/1][http_192.168.184.134_9200_articleindex_article_1] delete提交
二、Head插件的的安装和使用
下载:
下载地址: https://github.com/mobz/elasticsearch-head [下载地址][Link 2]
安装:
和ElasticSearch安装方式一样,直接解压就可以使用
注意: 先安装node.js就像java先安装JDK一样
他是需要先安装node.js的哦 node.js我会在下面提供链接
请不要复制直接粘贴,里面的空格要修改
npm install ‐g cnpm ‐‐registry=https://registry.npm.taobao.org
这句话的作用就是将下面这个文件去服务器下载,它相当于一个pom文件

将grunt设置为全局命令
npm install ‐g grunt‐cli
安装依赖
cnpm install
启动
grunt server (在head的安装目录下)
你以为结束了吗?NO,ElasticSearch它默认是没有跨域的,而head恰恰是一个前端的工程,所以是会报错的
所以要在ElasticSearch中添加配置,让其允许跨域访问。

修改这个文件夹:
http.cors.enabled: true
http.cors.allow‐origin: “*“
打开浏览器,输入localhost:9100
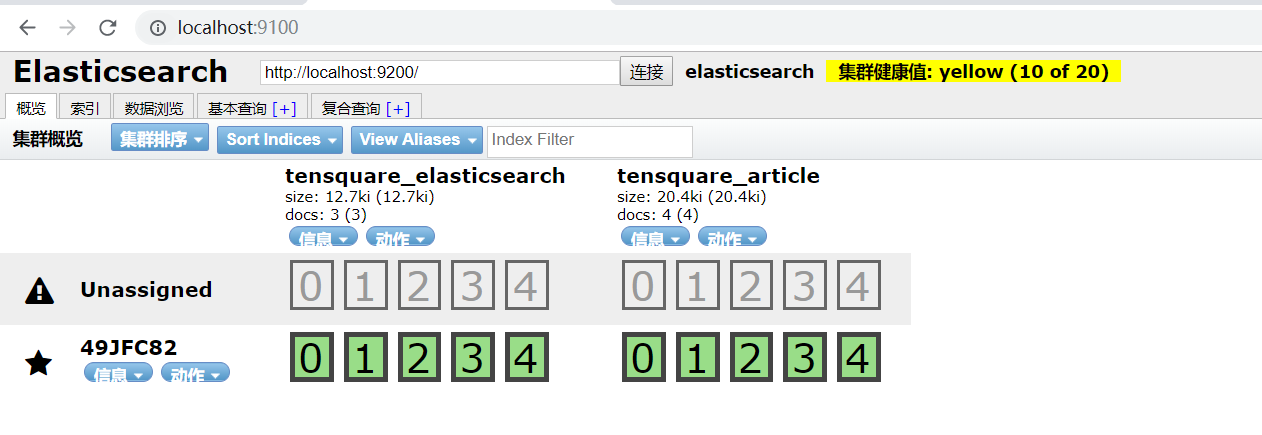
至于这个插件的使用。。。。。。。。。。。
懒得写了,望谅解
三、IK分词器
EalsticSearch的实现是通过分词来创建索引,在通过对关键字分词,去查找对应的索引值。IK就是一款针对中文的分词器
下载:
https://github.com/medcl/elasticsearch-analysis-ik/releases
IK分词器
安装:
将其解压,将其改名为ik将他放入elasticsearch目录下的plugins目录下重启。
说明:
IK分词器提供了两种算法 ik\_smart 和 ik\_max\_wordik\_smart 最少切分 ik\_max\_word 最细粒度切分



























![[C++] Value Categories](https://image.dandelioncloud.cn/images/20221021/aa4437ac757247c392f9012b5392f03e.png "[C++] Value Categories")







还没有评论,来说两句吧...