Scrapy 框架介绍
一、Scrapy是什么
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。我们只需要定制开发几个模块就可以轻松实现一个爬虫。
二、Scrapy优点
1、速度快
2、实现大批量爬取
三、Scrapy爬虫框架的架构

(1) Scrapy有五个部分组件组成:
中 > 引擎Scrapy Engine:用来处理整个系统的数据流处理、触发事务,是整个框架的核心上 > 调度器Scheduler:用来接受引擎发过来的请求并加入队列中,并在引擎再次请求的时候提供给引擎。左 > 管道item pipeline:负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。下 > 爬虫器(爬虫组件) Spiders:其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成提取结果和新的请求。Spider Middlewares(Spiders中间件):位于引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛输入的响应和输出的结果及新的请求。右 > 下载器 Downloader:用于下载网页内容,并将网页内容返回给Spiders爬虫器。Downloader Middlewares(下载器中间件):位于引擎和下载器之间的钩子框架,主要是处理引擎与下载器之间的请求及响应。
(2) Scrapy数据流机制:
引擎Scrapy Engine : C位,不用做事,接收任务,分发任务。爬虫器Spiders :1.确认目标url,根据这个url构造一个request对象,交给引擎4.接收了来自引擎的response,进行解析,解析完毕,把结果给引擎解析结果分为2种--(1)如果提取出来的是url,就把所有的步骤重头再走一遍--(2)如果是需要进行保存的数据data调度器Scheduler:2.接收了来自引擎的request对象,进行一个排序,把排序之后的结果交给引擎(假设有100个request对象,安装调度,安排谁先谁后).下载器Downloader:3.接收了来自经过了排序之后的引擎的request对象,发送网络请求获取响应对象response,交给引擎.管道item pipeline:5.接收了来自引擎的数据data,进行保存.通过多个组件的相互协作、不同组件完成工作的不同、组件很好地支持异步处理,scrapy 最大限度地利用了网络带宽,大大提高了数据爬取和处理的效率。
四、scrapy创建项目
(1) 爬虫项目
scrapy startproject 爬虫项目名
(2) 爬虫任务
cd 到项目的根目录
scrapy genspider 爬虫任务名称 域的范围.com
(3) 运行scrapy爬虫
scrapy crawl 爬虫任务名称
(4) Scrapy创建结构图
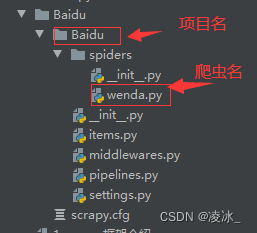
各个文件的功能描述如下:
- scrapy.cfg:它是 Scrapy 项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
- items.py:它定义 Item 数据结构,所有的 Item 的定义都可以放这里。
- pipelines.py:它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放这里。
- settings.py:它定义项目的全局配置。
- middlewares.py:它定义 Spider Middlewares 和 Downloader Middlewares 的实现。
- spiders:其内包含一个个 Spider 的实现,每个 Spider 都有一个文件。


































还没有评论,来说两句吧...