Scrapy爬虫框架介绍
scrapy安装:在cmd命令行中执行pip install scrapy
测试安装成功:执行scrapy -h
结构:
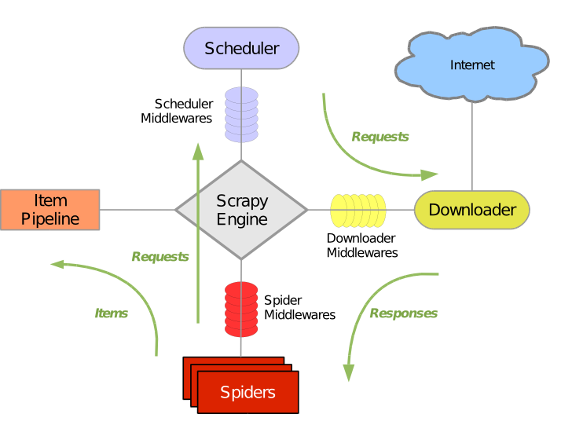
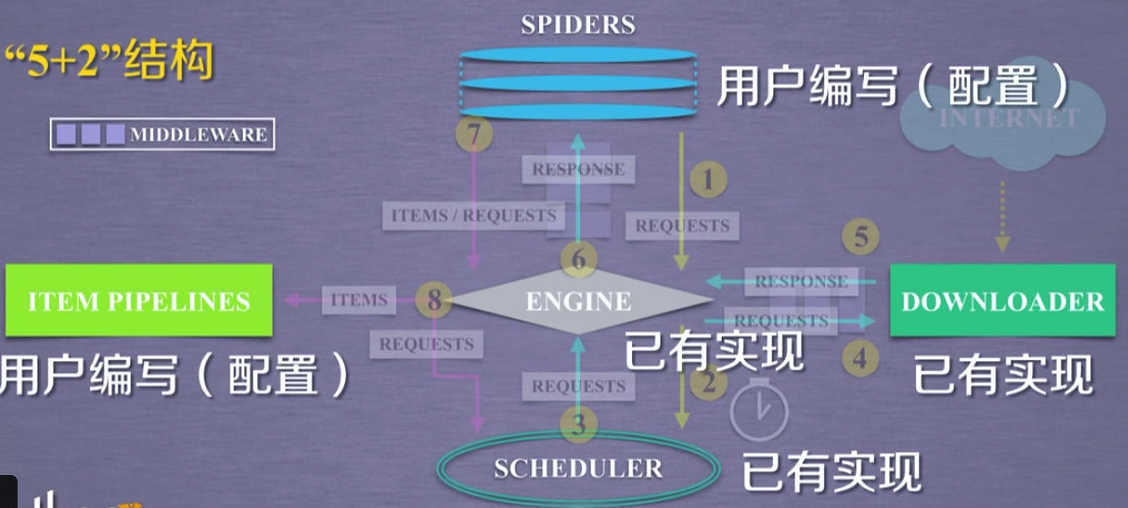
Engine:控制所有模块之间的数据流,根据条件触发事件(不需要用户修改)
Downloader:根据用户请求下载网页(不需要用户修改)
Scheduler:对所有爬取请求进行调度管理(不需要用户修改)
Downloader Middleware
目的:实施Engine、Scheduler和Downloader之间进行用户可配置的控制功能:修改、丢弃、新增请求或响应用户可以修改代码
Spider:解析Downloader返回的响应(Response)、产生爬取项(scraped item)、产生额外的爬取需求(Request) (需要用户编写配置代码)
Item Pipelines:以流水线方式处理Spider产生的爬取项、由一组操作顺序组成,类似流水线,每个操作是一个Item Pipeline类型、可能操作包括:清理,检验和查重爬取项中的HTML数据,将数据存储到数据库(由用户来编写配置代码)
Spider Middleware:(用户可以来编写配置代码)
目的:对请求和爬取项的再处理、功能:修改、丢弃、新增请求或爬取项


































还没有评论,来说两句吧...