MySQL模糊查询详解
单列模糊查询
使用的表结构
CREATE TABLE `user` (`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(32) DEFAULT NULL COMMENT '姓名',`city` varchar(32) DEFAULT NULL COMMENT '城市',`age` int(11) DEFAULT NULL COMMENT '年龄',PRIMARY KEY (`id`),KEY `idx_name_city` (`name`,`city`),KEY `idx_city` (`city`) USING BTREE) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8;insert into user(name, city, age) values("ZhaoDa", "BeiJing", 20),("QianEr", "ShangHai", 21),("SunSan", "GuanZhou", 22), ("LiSi", "ShenZhen", 24), ("ZhouWu", "NingBo", 25), ("WuLiu", "HangZhou", 26), ("ZhengQi", "NanNing", 27), ("WangBa", "YinChuan", 28), ("LiSi", "TianJin", 29), ("ZhangSan", "NanJing", 30), ("CuiShi", "ZhengZhou", 65), ("LiSi", "KunMing", 29), ("LiSi", "ZhengZhou", 30);
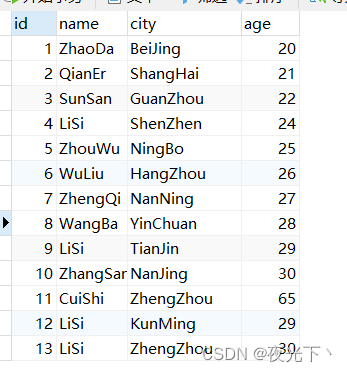
执行以下三条SQL
explain select * from user where city like '%h';

explain select * from user where city like 'h%';

explain select * from user where city like '%h%';

从执行结果上看只有第二条sql的索引没有失效,
结论:如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
单列模糊查询优化
对于如下SQL
explain select * from user where city like '%h%'
从执行计划看到 type=ALL,Extra=Using where 走的是全部扫描,没有利用到ICP特性。辅助索引idx_city(city)内部是包含主键id的,等价于(id,city)的复合索引,尝试利用覆盖索引特性
explain select id from user where city like '%h%';

从执行计划看到,type=index,Extra=Using where; Using index,索引全扫描,但是需要的数据都在索引列中能找到,不需要回表。利用这个特点,将原始的SQL语句先获取主键id,然后通过id跟原表进行关联,分析其执行计划。
explain select u.* from user u , (select id from user where city like '%h%') t where u.id = t.id;

从执行计划看,走了索引idx_city(city),不需要回表访问数据,执行时间从60ms降低为40ms,type = index 说明没有用到ICP特性,但是可以利用 Using where; Using index 这种索引扫描不回表的方式减少资源开销来提升性能。
联合索引模糊查询
索引条件下推ICP
ICP介绍
MySQL 5.6开始支持ICP(Index Condition Pushdown),不支持ICP之前,当进行索引查询时,首先根据索引来查找数据,然后再根据where条件来过滤,扫描了大量不必要的数据,增加了数据库IO操作。
在支持ICP后,MySQL在取出索引数据的同时,判断是否可以进行where条件过滤,将where的部分过滤操作放在存储引擎层提前过滤掉不必要的数据,减少了不必要数据被扫描带来的IO开销。
在某些查询下,可以减少Server层对存储引擎层数据的读取,从而提供数据库的整体性能。
官方文档:MySQL :: MySQL 8.0 Reference Manual :: 8.2.1.6 Index Condition Pushdown Optimization
ICP具有以下特点
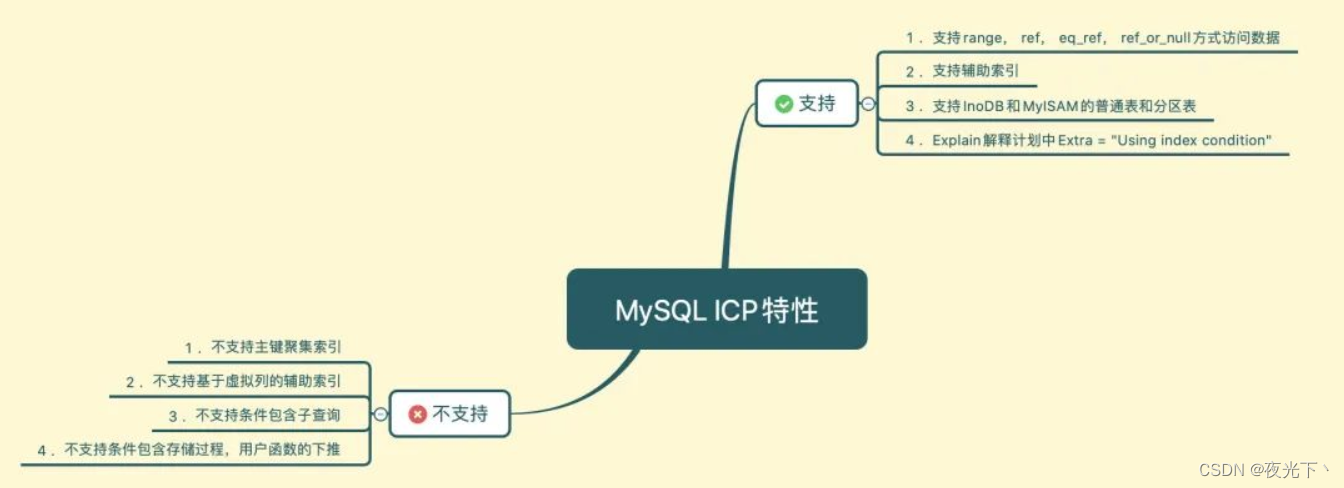
原理
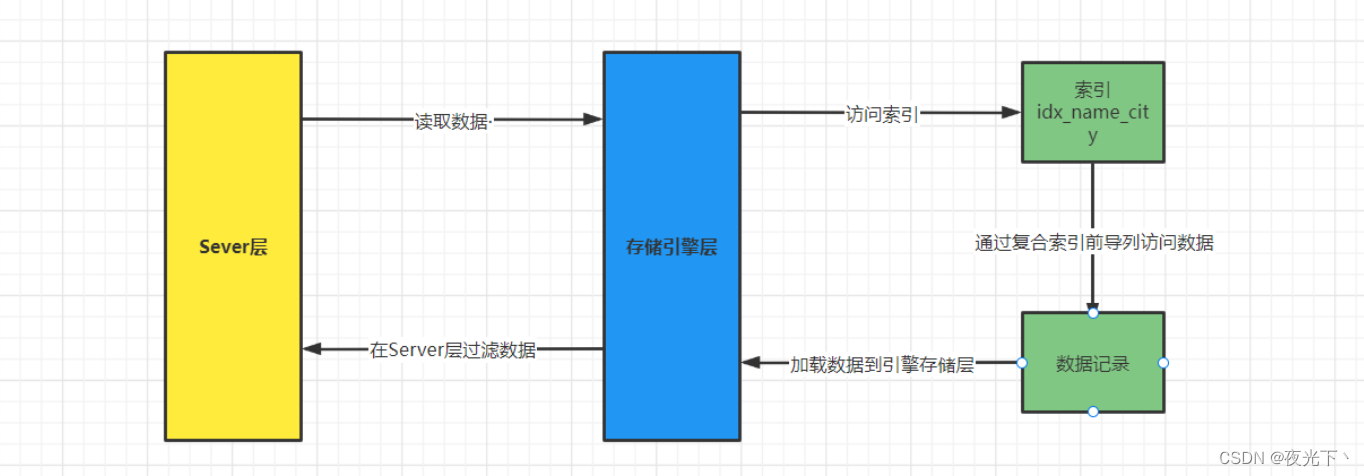
为了理解ICP是如何工作的,我们先了解下没有使用ICP的情况下,MySQL是如何查询的:
- 存储引擎读取索引记录;
- 根据索引中的主键值,定位并读取完整的行记录;
- 存储引擎把记录交给
Server层去检测该记录是否满足WHERE条件。
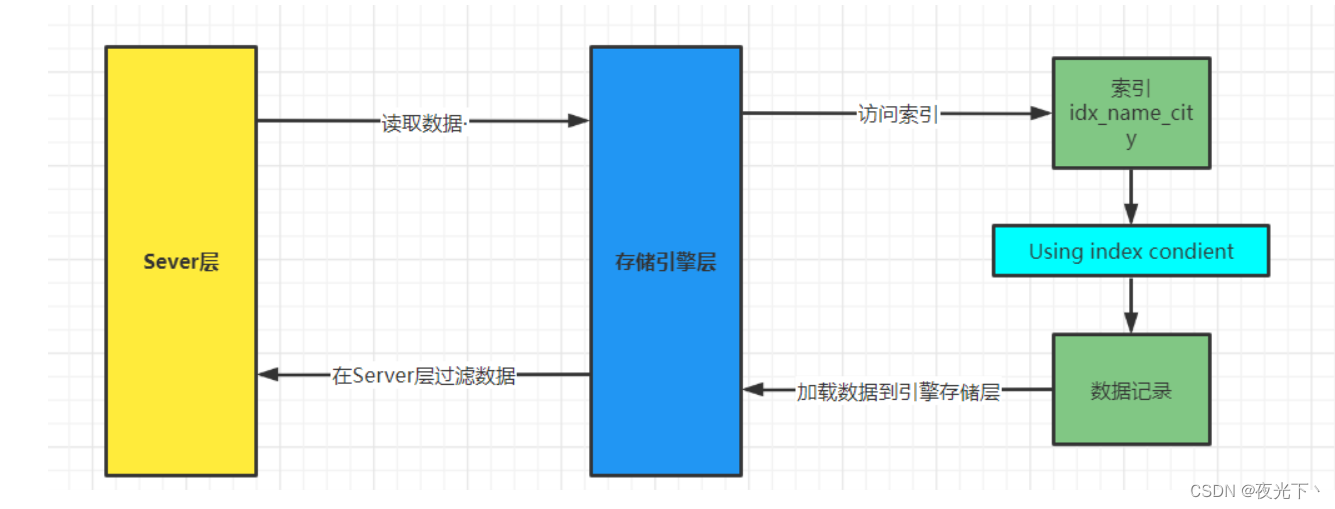
使用ICP的情况下,查询过程如下:
- 读取索引记录(不是完整的行记录);
- 判断
WHERE条件部分能否用索引中的列来做检查,条件不满足,则处理下一行索引记录; - 条件满足,使用索引中的主键去定位并读取完整的行记录(就是所谓的回表);
- 存储引擎把记录交给
Server层,Server层检测该记录是否满足WHERE条件的其余部分。
实践
set optimizer_switch = 'index_condition_pushdown=off';explain select * from user where name="LiSi" and city like "%Z%" and age > 25;

在不使用索引下推的情况下,根据联合索引“最左匹配”原则,只有name列能用到索引,city列由于是模糊匹配,是不能用到索引的,此时的执行过程是这样的:
使用索引下推
set optimizer_switch = 'index_condition_pushdown=on';explain select * from user where name="LiSi" and city like "%Z%" and age > 25;

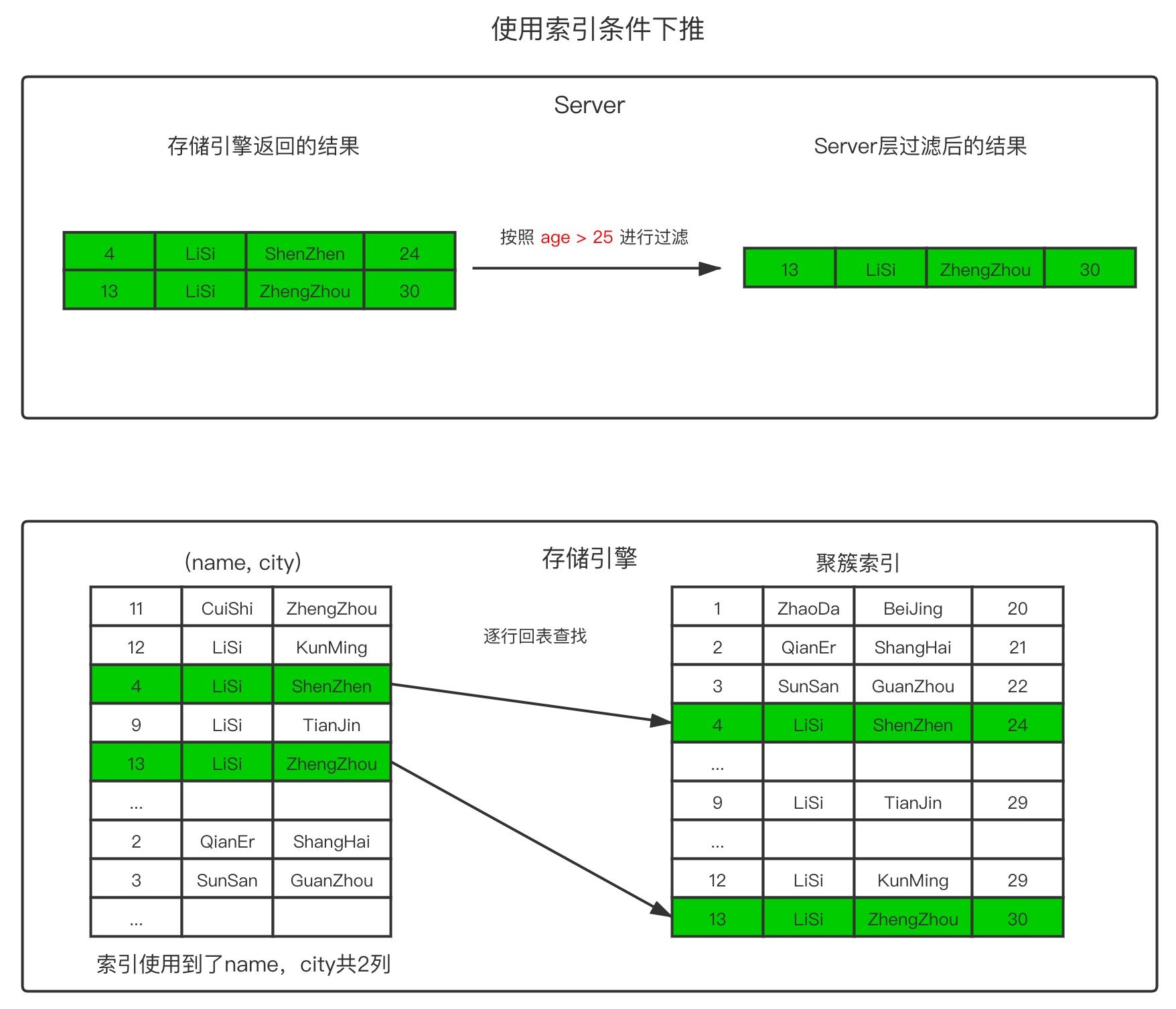
存储引擎根据
(name, city)联合索引,找到name='LiSi'的记录,共4条;由于联合索引中包含
city列,存储引擎直接在联合索引中按city like "%Z%"进行过滤,过滤后剩下2条记录;根据过滤后的记录的id值,逐一进行回表扫描,去聚簇索引中取出完整的行记录,并把这些记录返回给
Server层;Server层根据WHERE语句的其它条件age > 25,再次对行记录进行筛选,最终只留下("LiSi", "ZhengZhou", 30)这条记录。
对
InnoDB存储引擎来说,索引下推只适用于二级索引(也叫辅助索引),索引下推的目的是为了减少回表次数,也就是要减少IO操作。对于InnoDB的聚簇索引来说,完整的行记录已经加载到缓存区了,索引下推也就没什么意义了。



























![洛谷 P1169 [ZJOI2007]棋盘制作](https://image.dandelioncloud.cn/images/20230808/72ba490c52904facb1bad28940d1f12a.png "洛谷 P1169 [ZJOI2007]棋盘制作")





还没有评论,来说两句吧...