一条SQL语句如何执行
1、一条查询SQL语句执行
select * from tb_user;
数据库到底经历了哪些历程,其运转体系是什么样的?
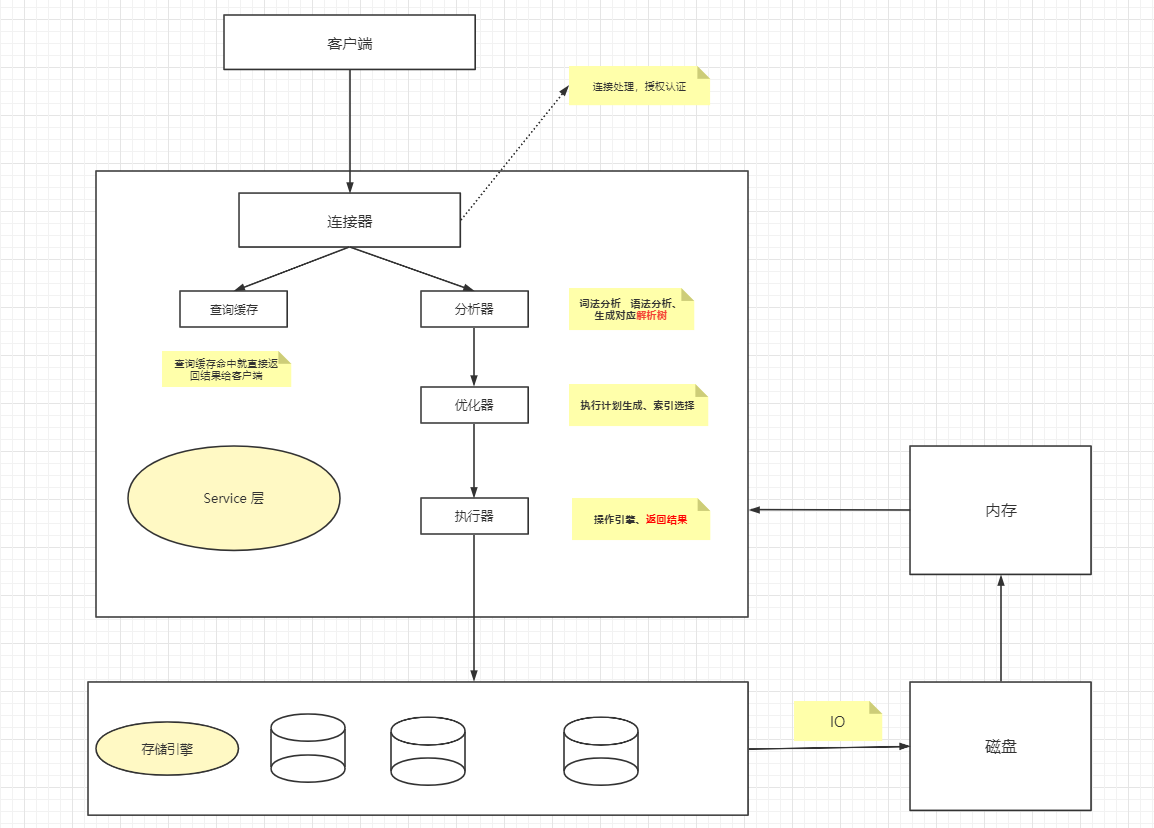
1.1、MySQL的逻辑架构图

Server层:
包括连接器、查询缓存、分析器、优化器、执行器等,涵盖MySQL的大多数核心服务功能,以及所有的内置函数,所有跨存储的功能都在这一层实现,比如存储过程、触发器、视图等。
存储引擎层:
负责数据的存储和提取。其架构模式是插件式的,支持InnoDB、MyISAM、Memory等多个存储引擎。
1) 连接器
连接器负责和客户端建立连接、获取权限、维持和管理连接
2) 查询缓存
MySQL拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句,之前执行过的语句及其结果可能会以key-value对的形式,key是查询的语句,value是查询的结果
如果你的查询能够直接在这个缓存中找到key,那么这个value就会直接返回给客户端。
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中
但是大多数情况下不要使用查询缓存,为什么呢?
因为查询缓存的失效率非常高,只要对一个表的更新,这个表上所有的查询缓存都会被清空。因为很可能费劲地吧结果存起来,还没使用呢,就被一个更新全清空.
3) 分析器
4)优化器
5)执行器
开始执行时,需要判断一下你对表有没有执行查询的权限,没有就返回权限错误
有权限就继续执行,执行器会根据表的存储引擎定义,使用存储引擎的接口
存储引擎:是管理表的方式(直接操作数据,从磁盘中拿到数据加载到内存中【IO操作】)
为什么要搞这么多的存储引擎
满足需求:
有的需要访问速度快,但是不用持久化
有的需要读写并发,较高的数据一致性
2、一条更新SQL语句执行
更新数据也是需要先查询出符合要求的(where)条件的数据,这一步还是执行了select,
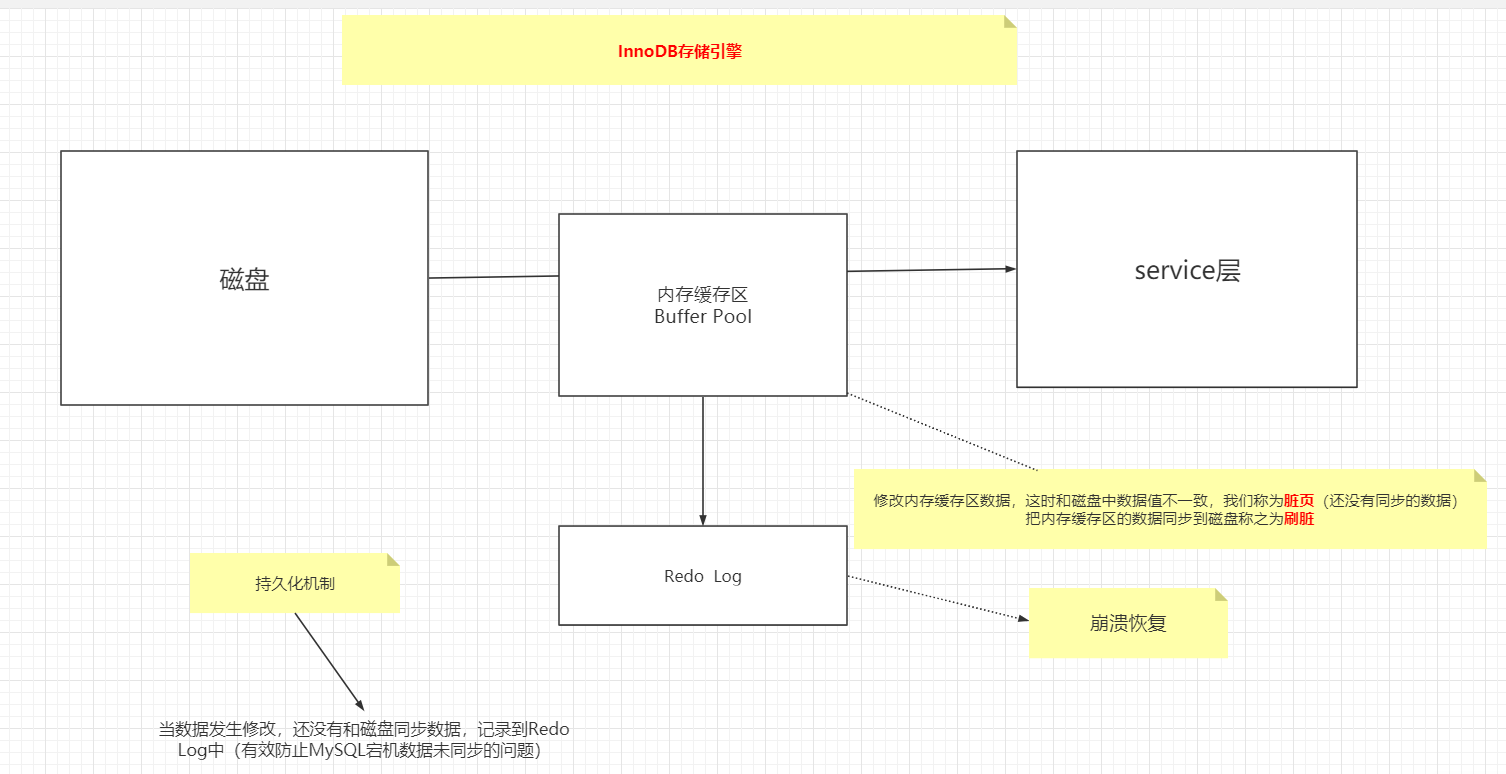
update tb_user set name='Tom' where name='ye'
执行过程分析
1、从存储引擎拿到数据,记录到Buffer Pool,进一步返回给Service(这是select操作)
2、service层会把上面数据页的name=’ye’的记录修改成name=‘Tom’
3、调用存储引擎,记录到Buffer Pool中,Redo Log Undo Log

























Deep Multi-instance Networks with Sparse Label Assignment for Whole Mammogram Classific")




")



还没有评论,来说两句吧...