一条SQL语句是如何执行的?
大家六一儿童节好呀!
接下来的一段时间内,将带领大家一同探索MySQL的奥妙,加油吧!我们。
下面进入正题:一条SQL语句是如何进行的?
对于这个问题,我想将其分为两个问题来回答,分别是:
- 一条查询SQL是如何执行的?
一条更新SQL是如何执行的?
我们都知道MySQL内部是分为Server层和存储引擎层的;每个层都有各自的职责;
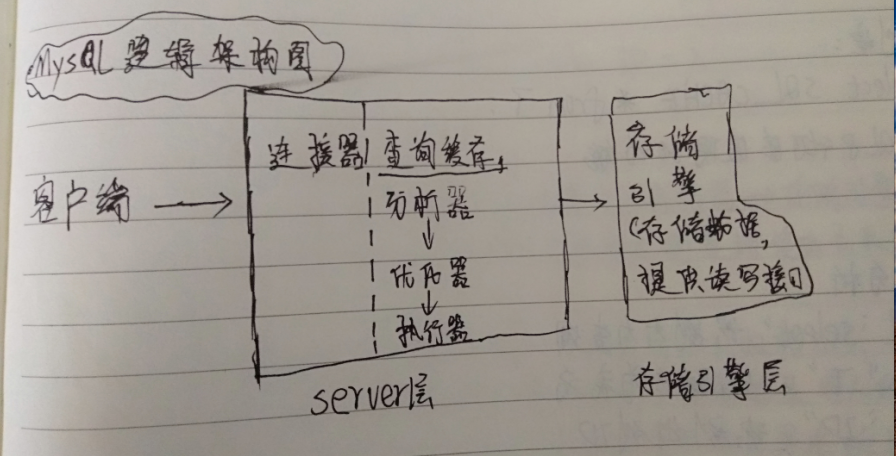
对于一个查询语句,eg:select * from T where ID=10
第一步:连接器(负责跟客户端简历连接、获取权限、维持和管理连接)
mysql -h IP -p Prot -u User -p Password #密码错误会提醒“Access denied for user”
如果验证通过,连接器会到表里面查出你拥有的权限;这个连接里面的权限判断逻辑,都依赖于此权限。
假如一个用户连接成功后,即使管理员账号对这个用户的权限进行了修改,也不会影响当前连接,除非重新建立连接。
完成后,如果你没有后续的动作,这个连接就处于空闲状态,可用“show processlist”命令查看。显示sleep则为空闲
这里涉及到一个长连接和短连接
长连接:建立连接成功后,如果客户端持续有请求,则一直使用同一个连接。
会发现有些时候MySQL占用内存涨的特别快,这是因为MySQL在执行过程中临时使用的内存是管理在连接对象中的,连接断开即释放。现象举例:MySQL异常重启
- 方案一:定期断开长连接
- 方案二:每次执行一个比较大的操作后,执行”mysql_reset_connection”(此过程不会重新做权限验证)
- 短连接:执行完很少的几次查询就断开连接
第二步:查询缓存
- 之前执行过的查询,MySQL以”Key - Value”的形式存在内存(key为SQL,value为结果集);
- 只要对该表有一个更新,则这个表上的查询缓存都会被清空;
- 手动创建命令:select SQL_CACHE * from T(MySQL8中已经彻底废除此功能);
第三步:分析器(词法分析 —— 语法分析)
词法分析:通过“select”,识别出为查询;通过“T”,识别出表名;通过条件“ID”,识别出ID那一列;等等;
语法分析:如果语法有误,则提示“You have an error in your SQL syntax”;
第四步:优化器
决定用哪个索引;联查表连接顺序;条件执行优先级 ,等等;
第五步:执行器 (执行SQL)
第六步:存储引擎(提供读写接口,供执行器调用并获取结果集)
- 首先会判断你是否有该权限;
- 如果命中查询缓存,则会在返回结果的时候进行权限验证;
补充:MySQL慢查询日志中,会有一个rows_examined字段,代表扫描了多少行。这个值就是在每次调用存储引擎获取数据行的时候累加的。不过,若是只调用一次,而扫描了多行,则rows_examined是不准确的。
对于一条更新SQL,同样走和查询一样的流程。
不过,执行更新SQL会涉及到两个重要的日志:redo log (重做日志)、bin log (归档日志)。
“《孔乙己》中,酒店掌柜有一个粉板,专门用来记录客人的赊账记录,如果赊账的人不多,那么他可以把顾客名和账目写在粉板上。但如果赊账太多了,粉板总有挤不下的时候,这个时候,掌柜一定还有一个专门记账的账本”
掌柜第一种做法:每次记账都打开账本
掌柜第二种做法:先写在粉板上,打烊后再核算
个人感觉掌柜很聪明。对于MySQL,同样也有类似的处理:
- MySQL的 WAL技术,(Write-Ahead-Logging),先写日志,再写磁盘。
- 对于innodb,会先把记录写到redo log中,并更新内存,同时,innodb会在适当的时候,将这个操作记录更新到磁盘中
有了redo log 会保证innodb在数据库发生异常重启之后,之前提交的记录都不会丢失,称之为:“crash_safe”
redo log是存储引擎层的日志,bin log是server层的日志
| redo log | bin log |
|---|---|
| innodb独有 | server层日志,所有引擎都有 |
| 物理日志,记录“在某个数据页上做了什么修改” | 逻辑日志,记录的是语句的原始逻辑 |
| 循环写,空间固定 | 追加写入 |
以上就是执行一个SQL语句会经历的过程,当中提到的很多名词,后期会慢慢给出对应详细解释,大家也可以提出来。
努力吧!坚持做正确的事!相信自己!!!




























还没有评论,来说两句吧...