AQS源码分析
ReentrantLock底层原理
文章目录
- ReentrantLock底层原理
- 一、AQS简介
- 1.1 成员变量
- 1.2 Node节点
- 1.3 继承关系
- 二、获取锁源码分析
- 2.1 为什么判断是否需要进入队列?
- 三、锁发生竞争源码分析
- 3.1 锁重入的体现
- 3.2 为什么要修改两次waitStatus的值?
- 3.3 线程阻塞时的中断情况
- 3.4 第三个线程入队的情况
- 四、解锁源码分析
- 4.1 为什么从后向前寻找节点?
一、AQS简介
- 抽象队列同步器
AbstractQueuedSynchronizer简称AQS,它是同步器的基础组件,JUC各种锁的底层实现均依赖于AQS
1.1 成员变量

state表示锁状态- 值为0表示没有人持有这把锁(处于自由状态),int型默认为0
- 值大于0表示有线程持有这把锁
- 如果发生锁重入则值+1
head和tail分别表示指向队列的头节点和尾节点的指针AQS中的队列是先进先出的双向链表
- 注意:队列中的头节点并不是要获取锁的节点,只是占位的摆设,真正要获取锁的节点是第二个节点,第二个节点获取到锁之后成为头节点
某个线程没有获取到锁则需要进入队列中等候
- 持有锁的线程一定不会在队列中(先记住结论,源码中分析原因)
1.2 Node节点
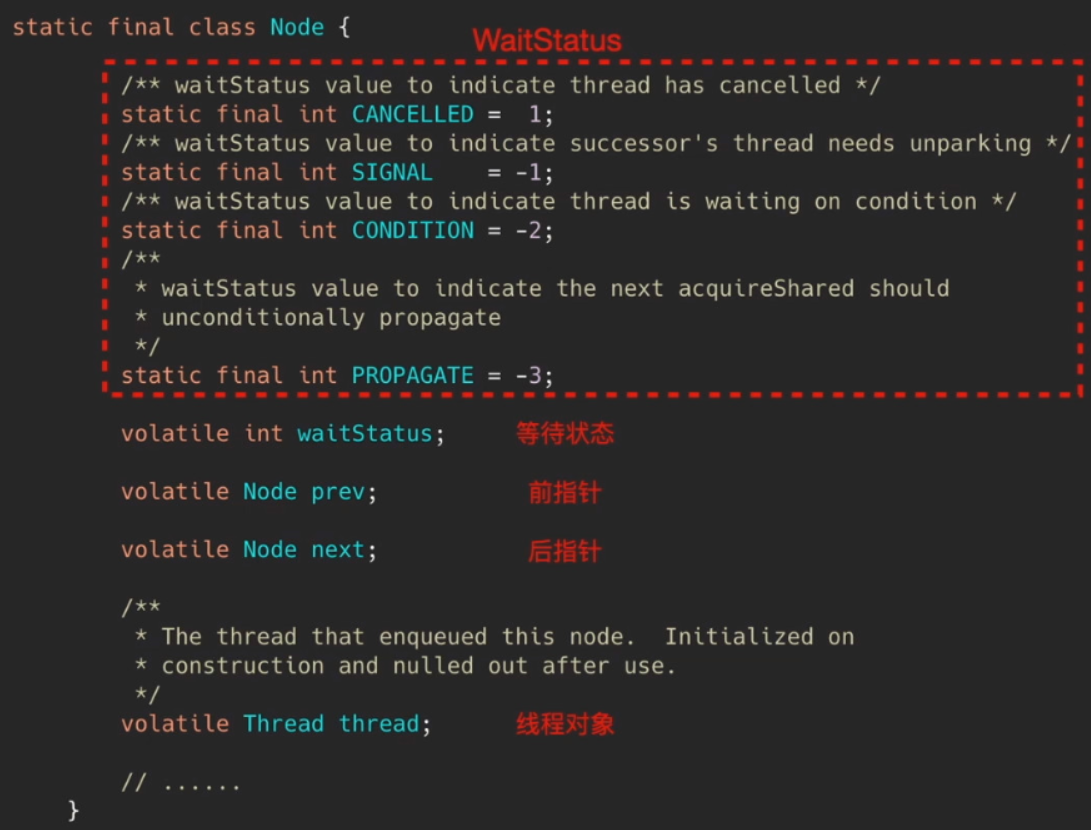
队列中的每个Node节点由四部分组成
- 前指针、后指针、当前线程、当前线程的等待状态
对于
WaitStatus枚举值,记录当前线程的等待状态,int型默认值为0CANCELLED(1)表示线程被取消了SIGNAL(-1)表示线程需要被唤醒,处于等待状态CONDITION(-2)表示线程在条件队列里面等待PROPAGATE(-3)表示释放共享资源时需要通知其他节点
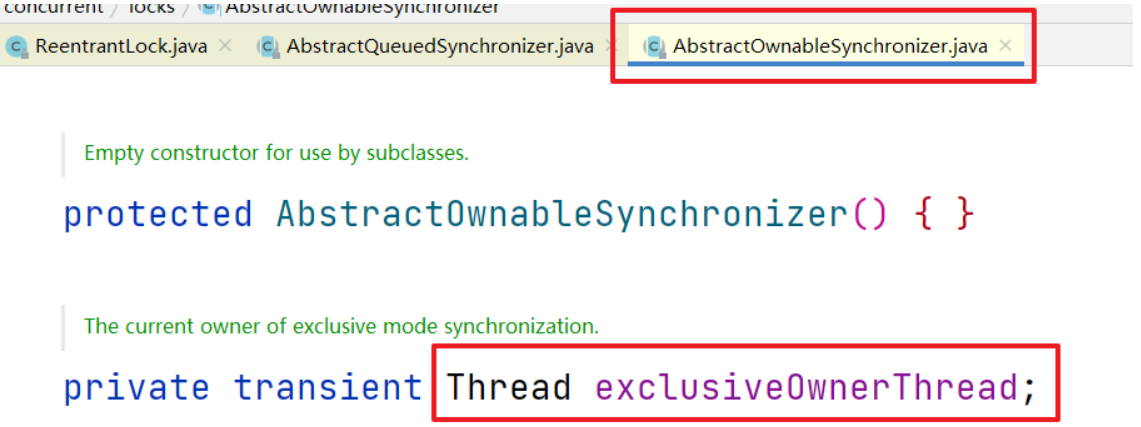
1.3 继承关系
AbstractQueuedSynchronizer 继承于 AbstractOwnableSynchronizer

exclusiveOwnerThread 表示当前持锁线程
二、获取锁源码分析
在正式分析之前,需要了解ReentrantLock中有一个队列,获取不到锁的线程都会进入队列排队
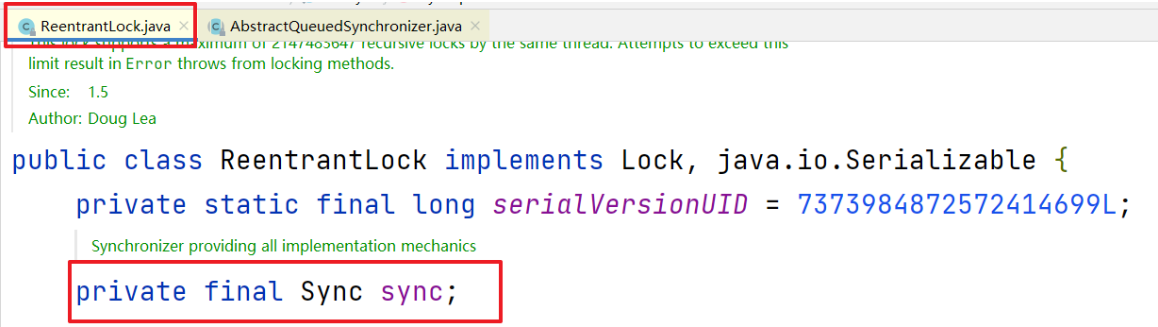
这个队列继承AQS,也就是说ReentrantLock包含了AQS队列

正式源码分析:
进入lock方法

继续进入lock方法
选择公平锁的实现方式

进入acquire方法
参数值固定为1,表示尝试将AQS中的属性state修改成为1(加锁)

进入tryAcquire方法
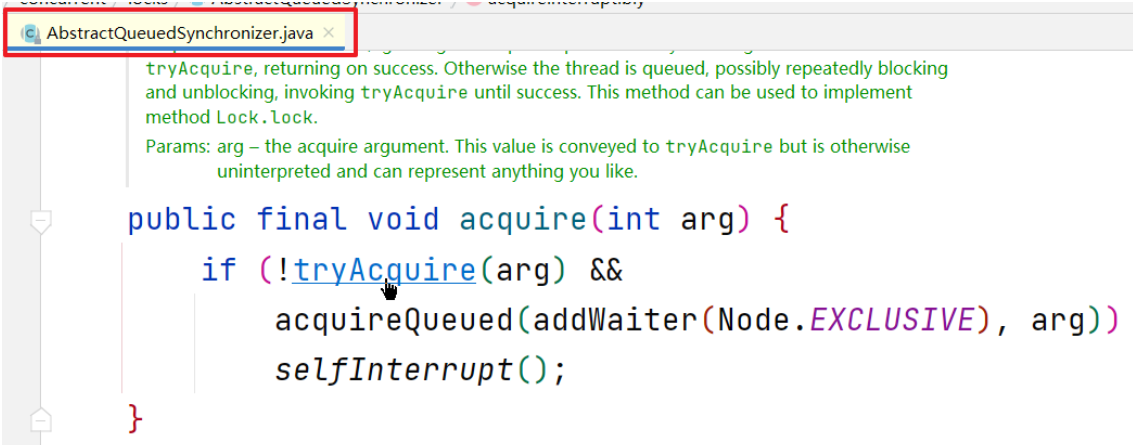
选择公平锁重写的方法
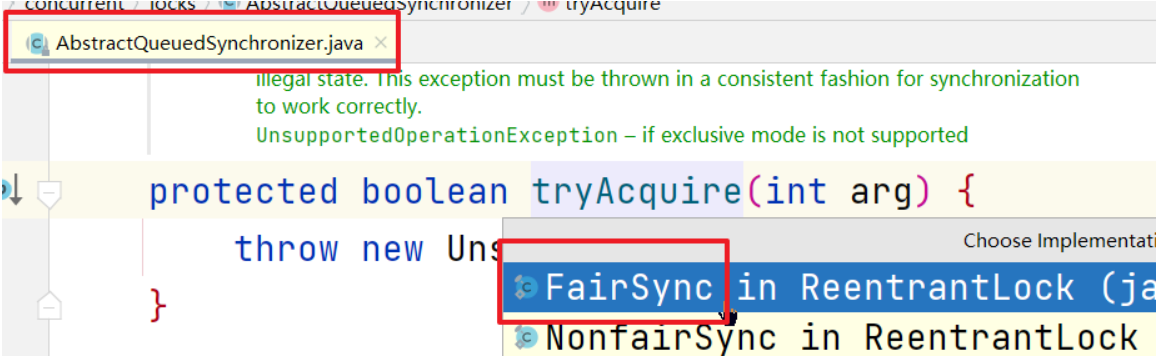
实现类必须重写tryAcquire方法,否则会抛出不支持该操作的异常

首先获取当前尝试加锁的线程,然后进入getState方法
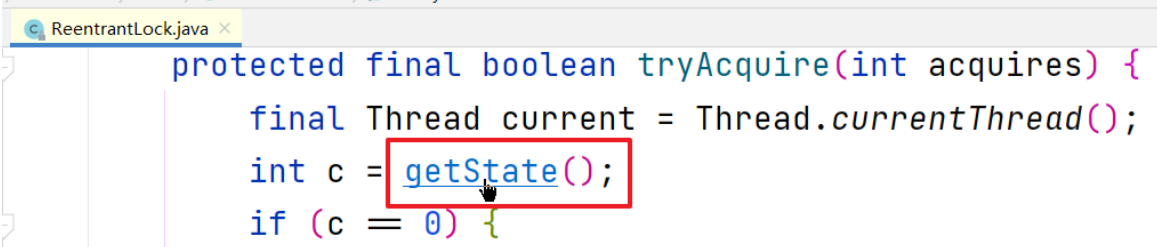
返回state的值,此时为0(还没有线程加锁)
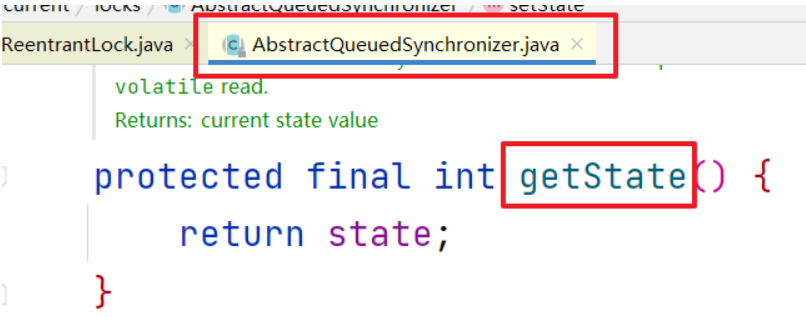
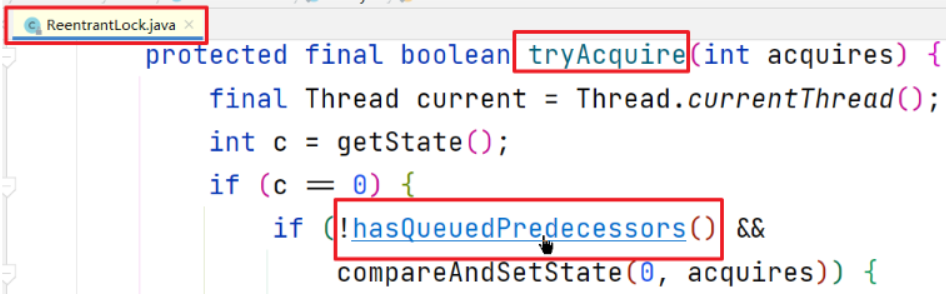
getState方法返回0,判断得知锁处于自由状态,进入if代码块,执行hasQueuedPredecessors方法
hasQueuedPredecessors方法用于判断当前线程需不需要在队列中等候
此时,可能你有疑惑,此时已经判断此线程可以加锁,直接通过CAS加锁就好了,为什么还要判断需不需要排队呢?(查看二、1解答)
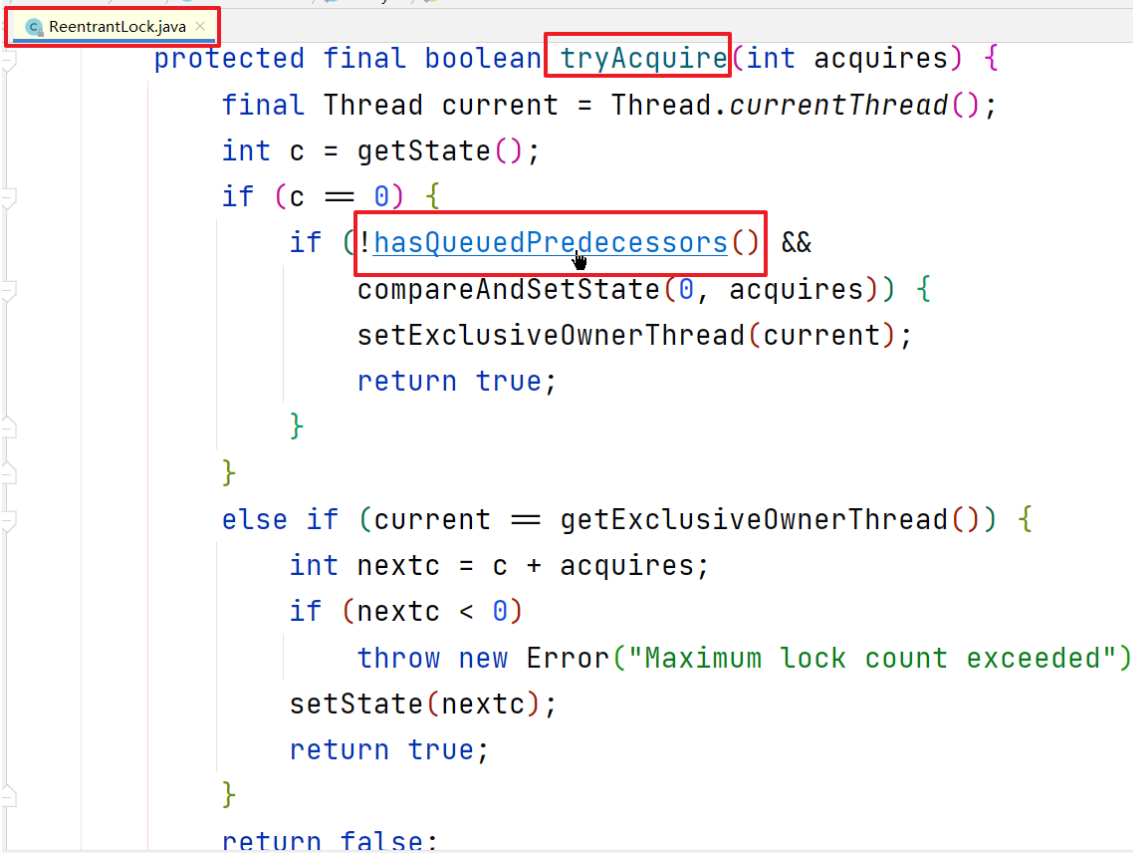
hasQueuedPredecessors方法返回false,表示不需要加入队列等待
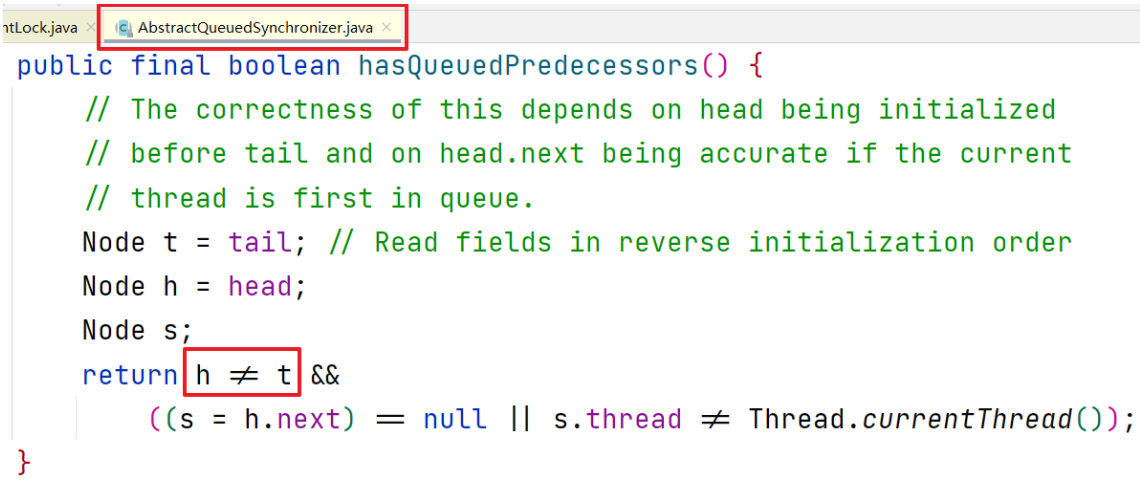
- 此时三者的值均为null,return的第一个判断返回false,整个方法返回false
源码退回第9步,即tryAcquire方法,进入setExclusiveOwnerThread方法
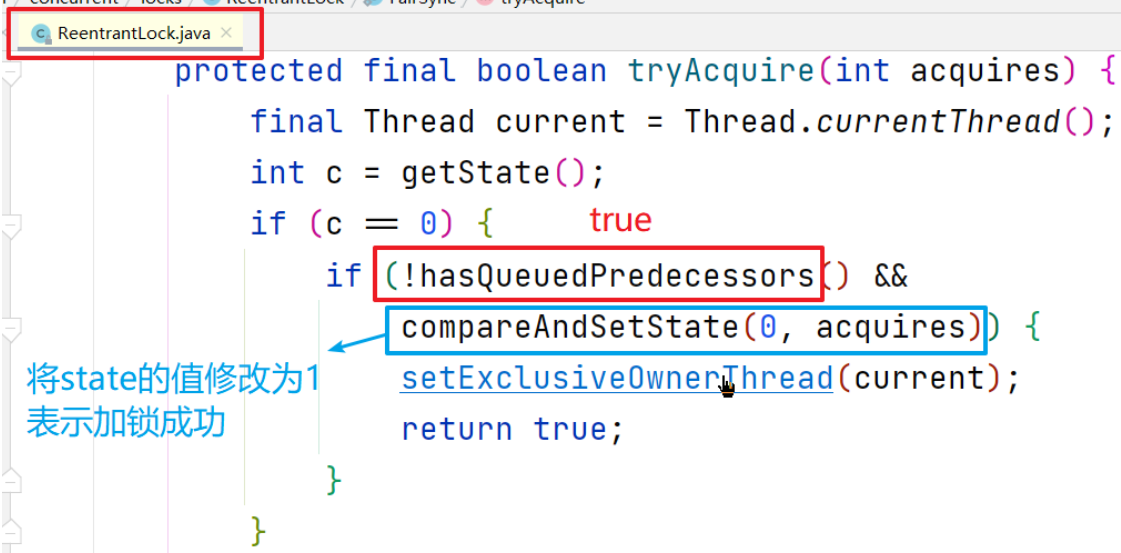
成功将持锁线程设置为当前线程

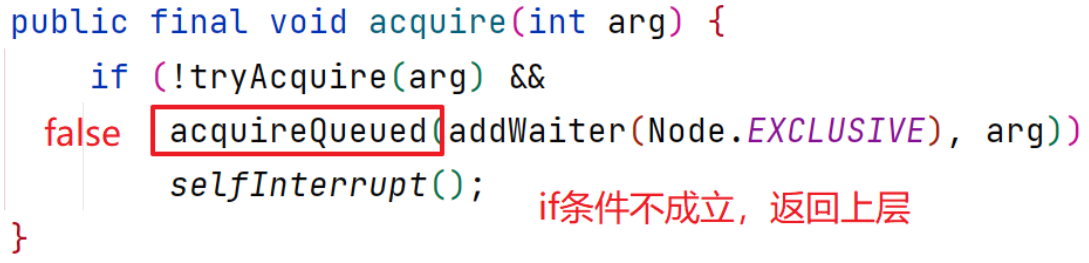
将源码退回至第11步,tryAcquire方法返回true,源码退回至第5步,即acquire方法
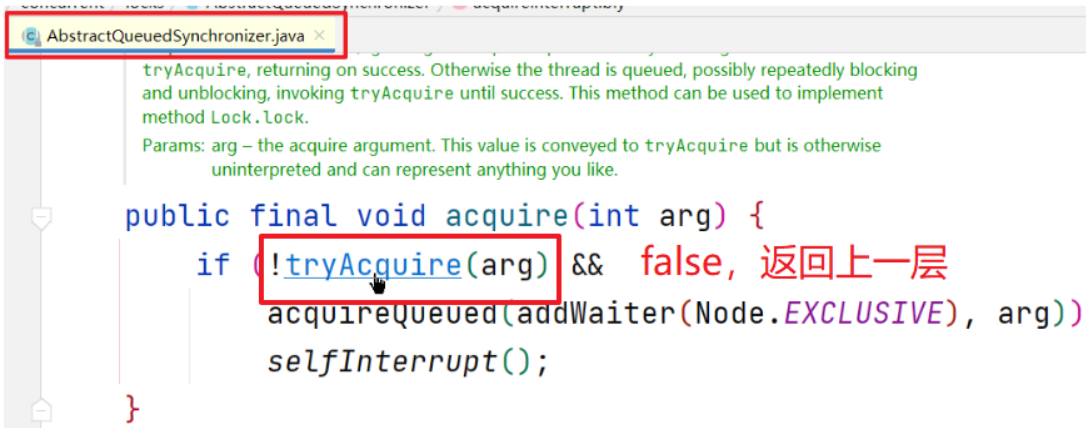
- 源码持续返回,直到第一步调用lock方法处,代码继续向下执行,表示加锁成功
结论:
- 单个线程或者多个线程没有竞争交替执行时,ReentrantLock在JDK层面就可以解决同步问题,不会涉及到操作系统底层接口的调用
- 多个线程没有竞争交替执行是不会使用到队列的,仅仅是修改state的值
- JDK1.6之前synchronized加锁、释放锁操作系统都需要切换到内核态,并调用操作系统中底层的接口,操作比较重量级,ReentrantLock比其轻量
- JDK1.6对synchronized进行了优化之后(偏向锁、轻量级锁),对于单线程、多线程没有竞争时也可以在JDK层面完成加锁、解锁操作,二者性能相差无几
总结:
加锁过程首先判断state的值,如果为0,则判断需不需要加入队列,如果不需要,将state值修改为1,并将持锁线程修改为当前线程,加锁成功
2.1 为什么判断是否需要进入队列?
为什么tryAcquire方法中已经判断此线程可以加锁,还要判断需不需要排队呢?
- 如果t1获得了锁,此时t2尝试加锁失败,会进入队列中排队,某一时刻t1执行完代码,释放锁,state的值变为了0,就在此刻t3尝试获取锁,判断state的值为0,如果立即通过CAS加锁,t3就会比t2更先一步获取锁,不满足公平的特点
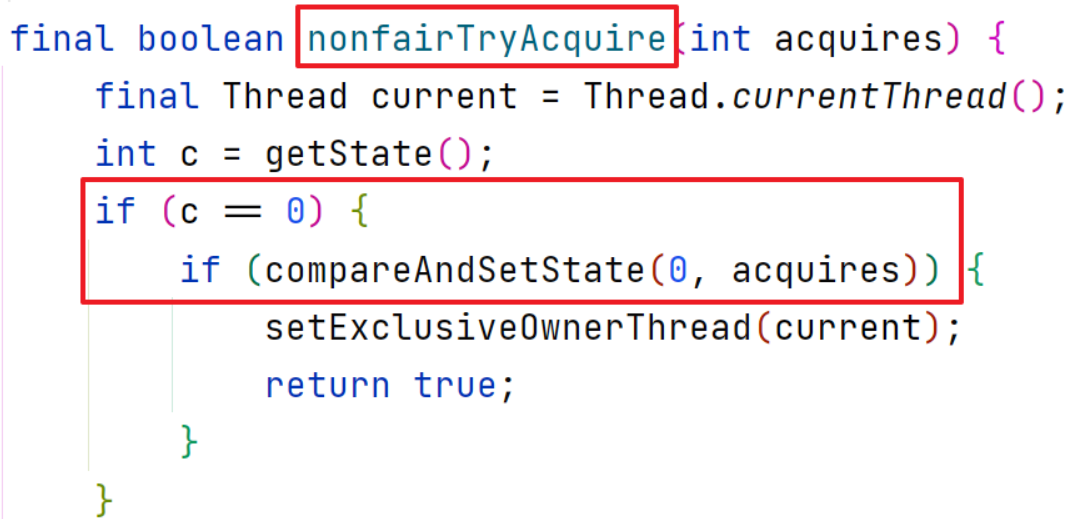
对于非公平锁
如果判断出当前的state值为0,则直接尝试加锁,而不去判断是否需要加入队列
三、锁发生竞争源码分析
持锁线程t1还没有释放锁,又有别的线程t2来尝试加锁,发生竞争
t2尝试加锁,和上述源码过程一致,执行至tryACquire方法
问题:ReentrantLock如何体现锁重入的呢?(查看三、1解答)
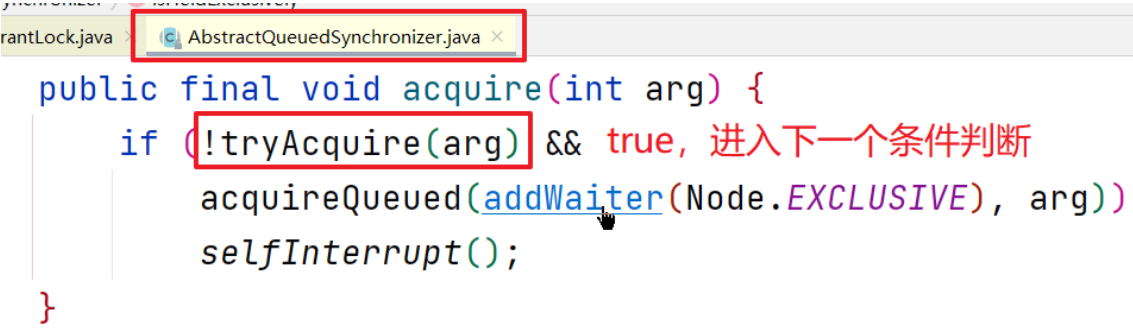
源码退回上层至acquire方法
执行addWaiter方法,将无法获取锁的线程加入队列中
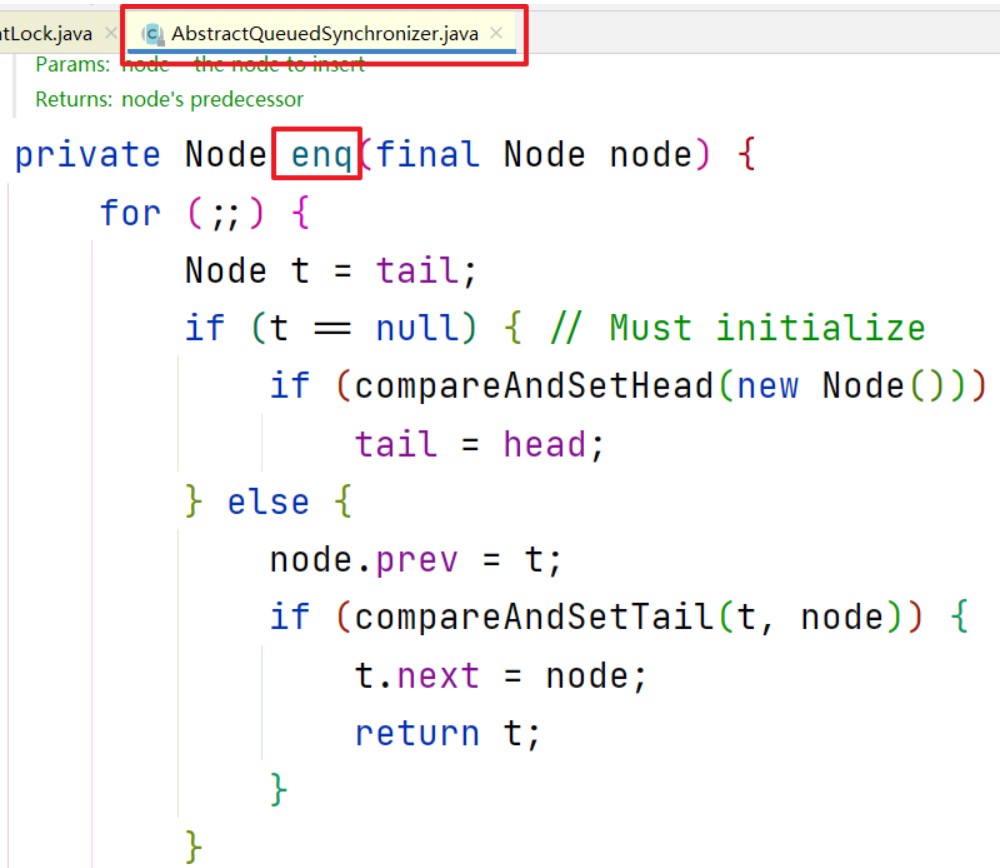
执行enq方法
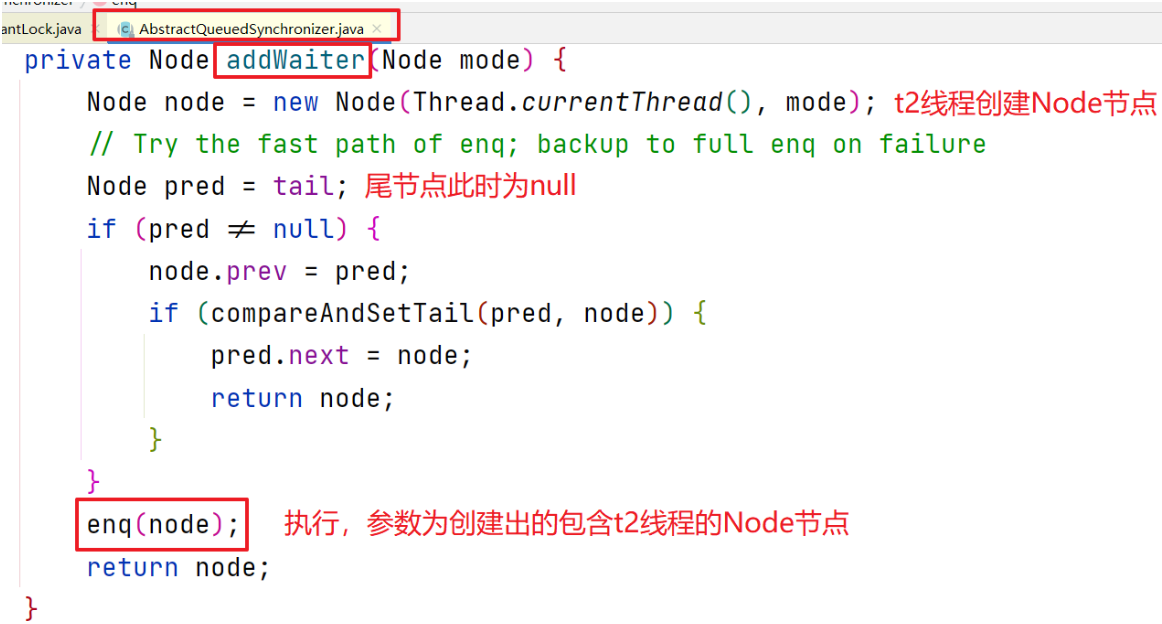
分析enq方法
enq方法创建队列的头尾节点,将参数节点设置为尾节点,并与头节点组成双向链表:
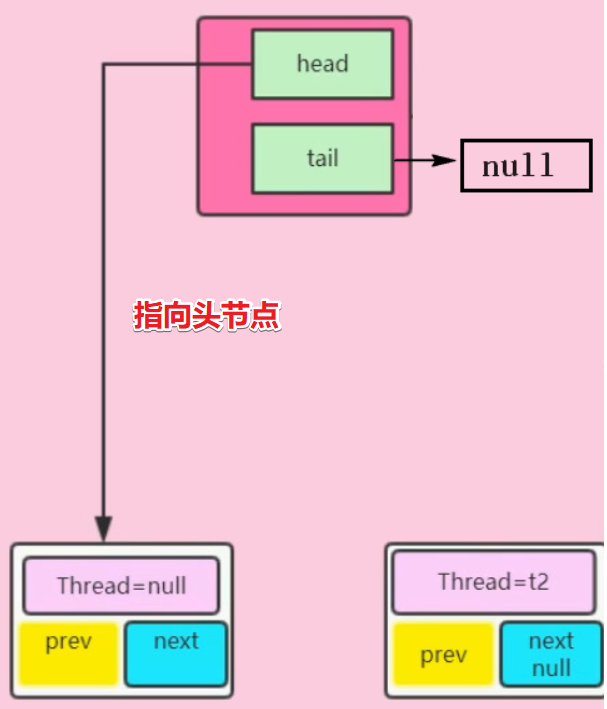
- 需要明确此时队列中的head和tail的值均为null
Node t = tail;赋值结果t为null进入if语句判断,创建一个线程为null值的空节点,并设置其为队列的头节点(队列的头节点中的Thread值永远为null)
tail = head;表示此时的头节点同时也成为了尾节点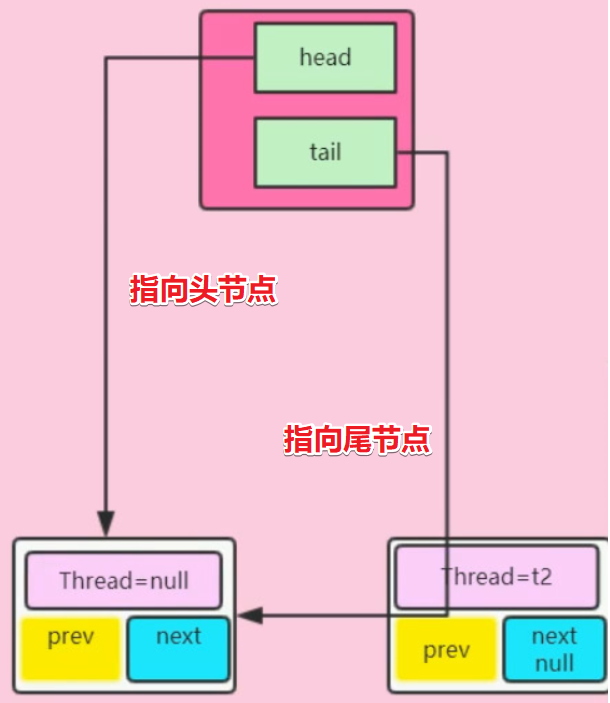
回到源码,不会进入else中,又进入了循环,判断得知此时t不为空,t是头节点(尾节点),进入else中
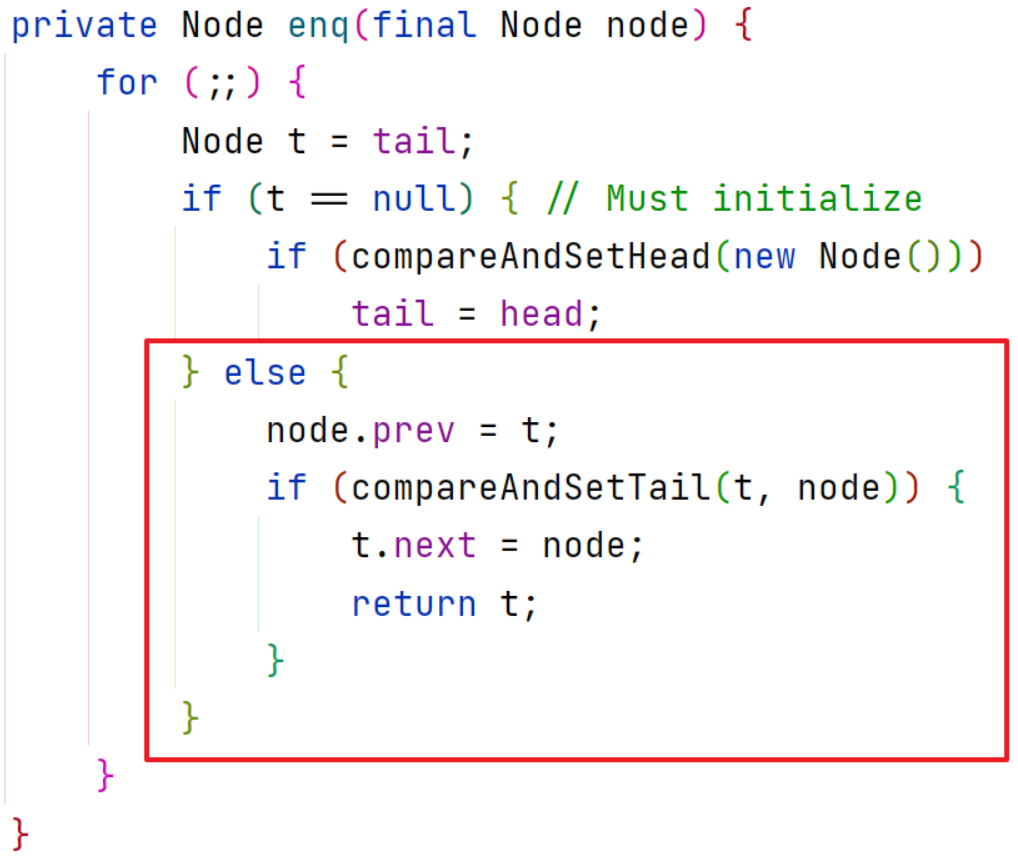
将包含t2线程的Node节点的前一个节点置为头节点,通过CAS操作将尾节点设置为包含t2线程的Node节点,头节点的下一个节点设置为包含t2线程的Node节点(双向链表),如图:
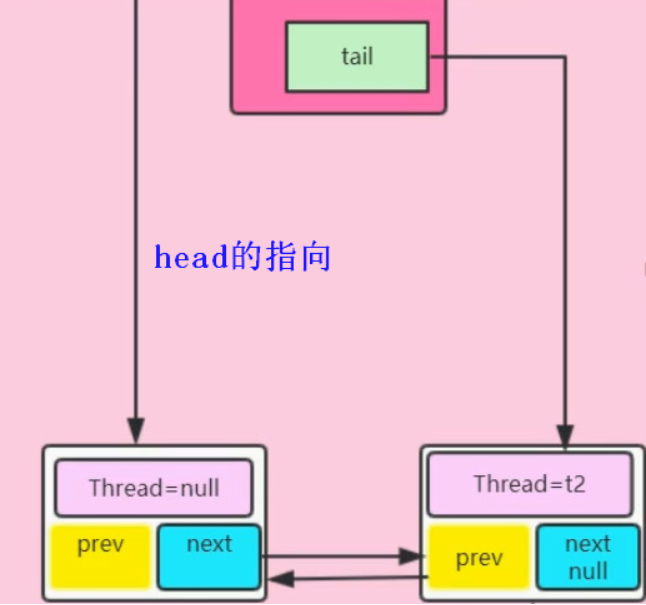
- 此时包含t2线程的Node节点入队成功,成为尾节点
源码退回上一层至addWaiter,返回此时成为尾节点的包含t2线程的Node节点
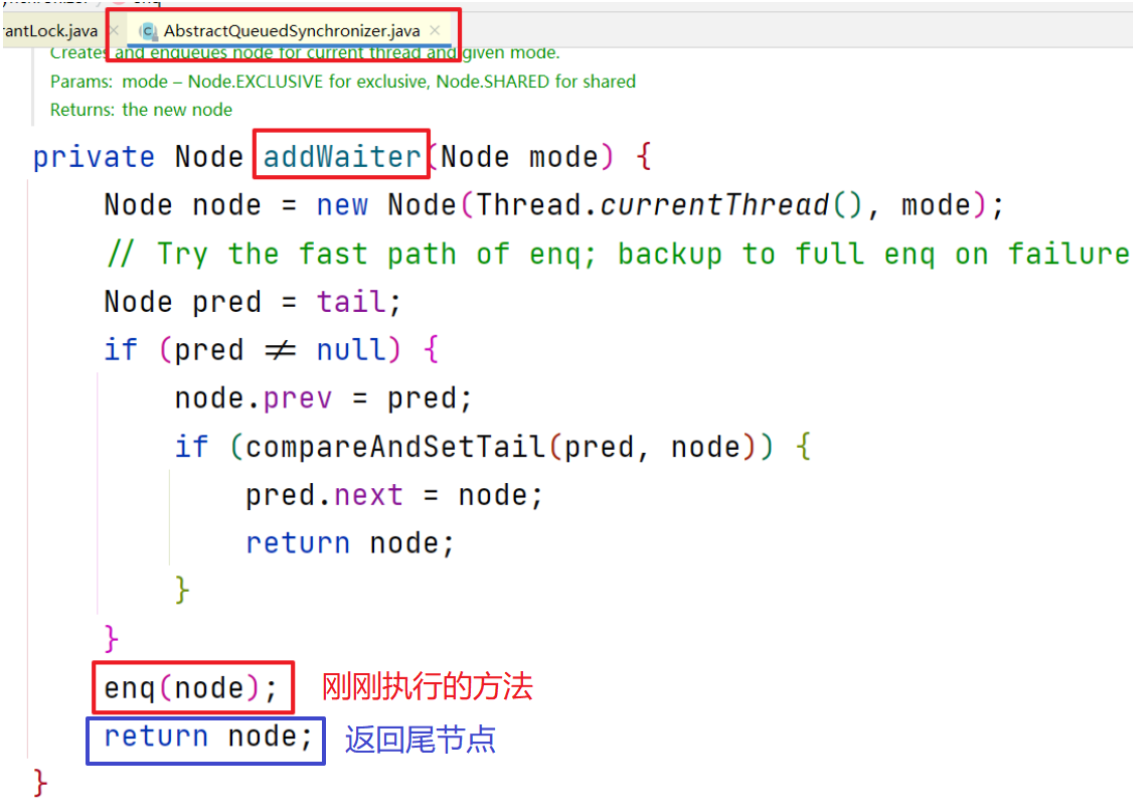
源码退回上一层至acquire方法,执行acquireQueued方法,参数是包含t2线程的Node节点 (尾节点) 和 1
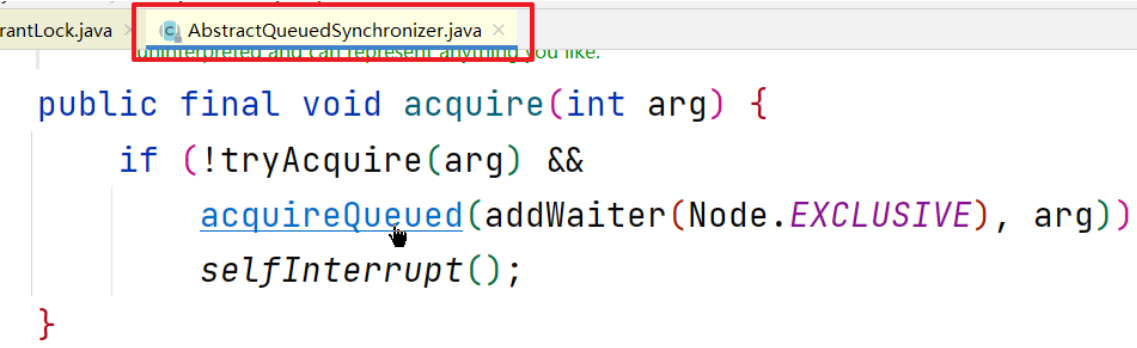
此时t2线程已经加入队列,但他还要去自旋的判断一下能不能获取到锁,因为有可能t1在它入队的过程中释放了锁,t2就不需要阻塞;如果自旋还是没有获取到锁,那么就需要将t2阻塞(入队并不是阻塞)
注意:对于t3线程来说,队列中它之前的节点是t2节点,出于公平的原则,无论如何都不会轮到t3获得锁,所以t3不会自旋,只有第二个节点对应的线程会自旋
对acquireQueued方法的分析
第二个节点对应的线程自旋两次后进入阻塞状态,等待被释放锁的线程唤醒后,成为队列的头节点(头节点的Thread要被置为null),第二个节点对应的线程成功获取到锁。原先的第一个节点脱离队列,被GC垃圾回收:
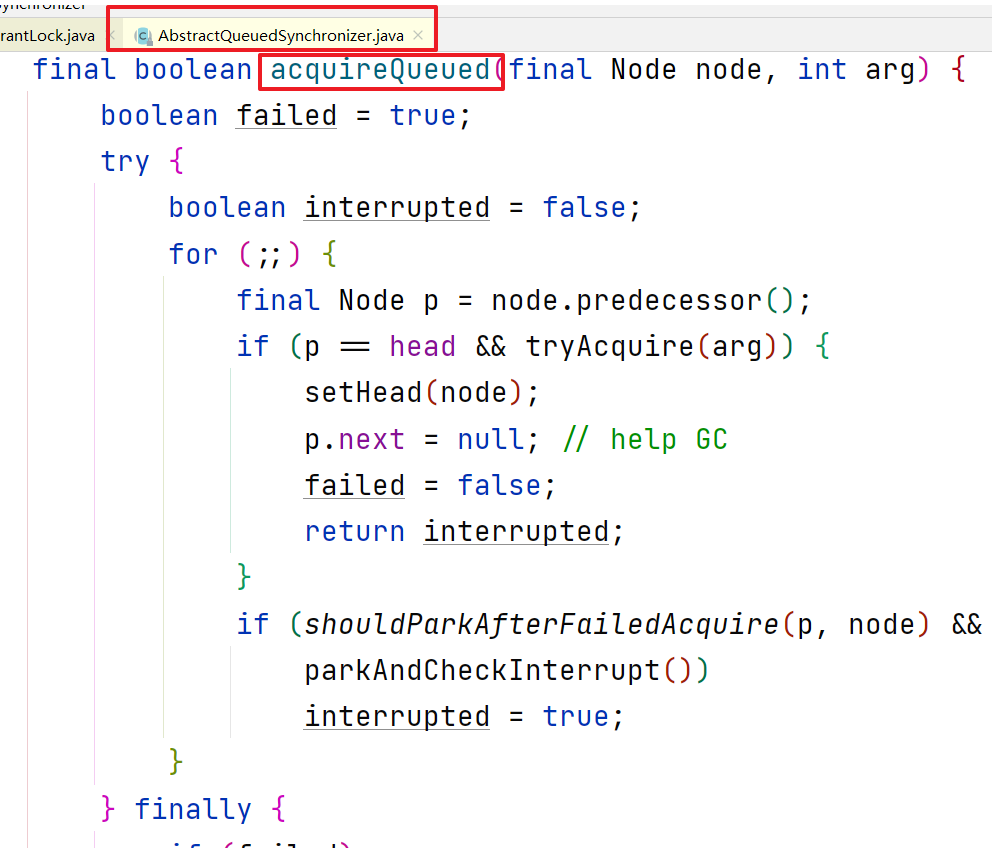
final Node p = node.predecessor();p成为包含t2线程的Node节点的前一个节点,此时是Thread为null的头节点if (p == head && tryAcquire(arg))第一个条件满足,第二个条件和之前分析的类似,尝试自旋一次获取锁,假设此时获取失败- 可以看出,只有第二个节点才会去自旋,第三个节点就不会自旋了
进入第二个if块,调用
shouldParkAfterFailedAcquire,第一个参数表示头节点,第二个参数表示尾节点(包含t2线程的Node节点)private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {int ws = pred.waitStatus; //头节点的status值为int型默认值0if (ws == Node.SIGNAL) return true; //不进入,SIGNAL值为-1if (ws > 0) { //不进入do {node.prev = pred = pred.prev;} while (pred.waitStatus > 0);pred.next = node;} else { //进入//将node的前一个节点(头节点)的status修改为-1,表示等待状态//注意不是修改t2线程node节点的statuscompareAndSetWaitStatus(pred, ws, Node.SIGNAL);}return false; //返回false}
源码退回上一层,继续进入循环
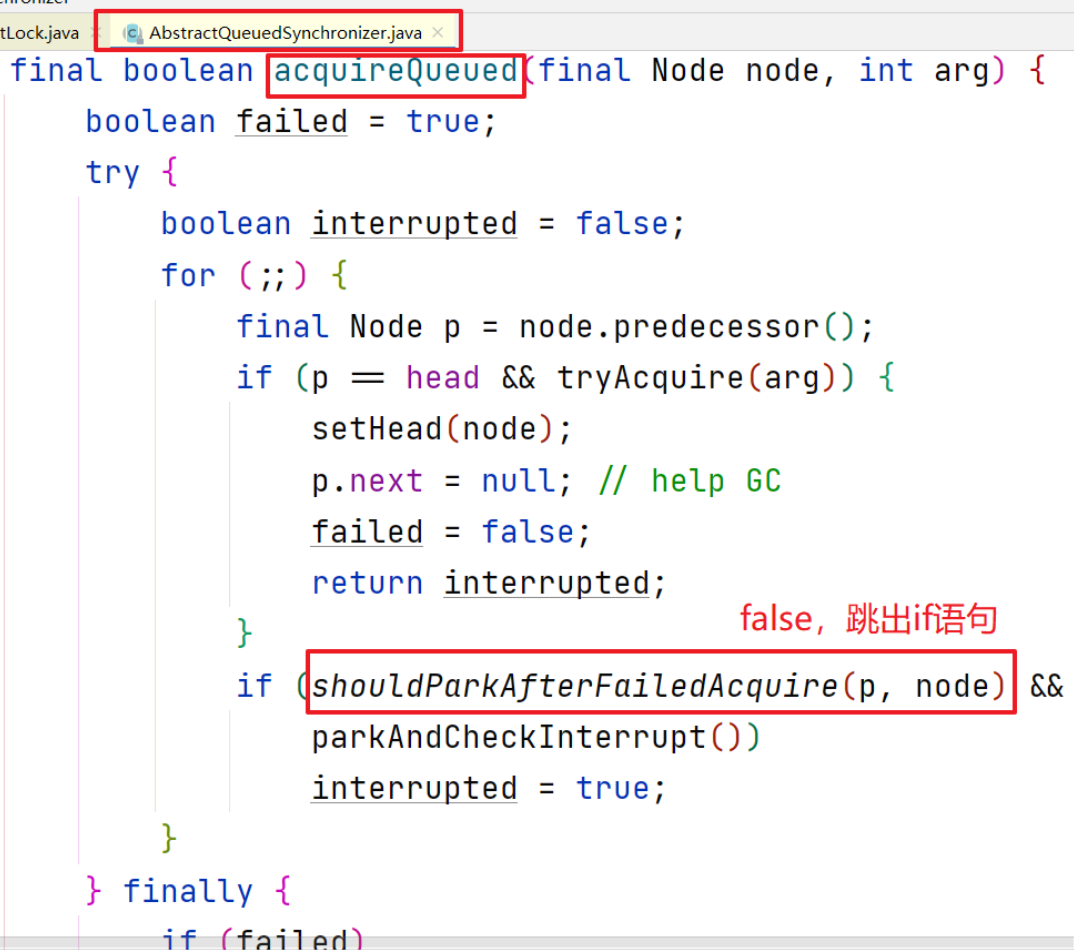
第二次循环时,假设if块中,又一次自旋尝试获取锁时还是没有得到锁,又进入
shouldParkAfterFailedAcquire方法private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {int ws = pred.waitStatus; //头节点的status此时值为-1if (ws == Node.SIGNAL) return true; //进入,返回true//省略其余.....}
- 此时有一个小问题,为什么第一次进入
shouldParkAfterFailedAcquire方法时,不直接ws==0就返回true,非要多赋值一次(修改为-1)呢?(查看三、2解答) 进入
parkAndCheckInterrupt方法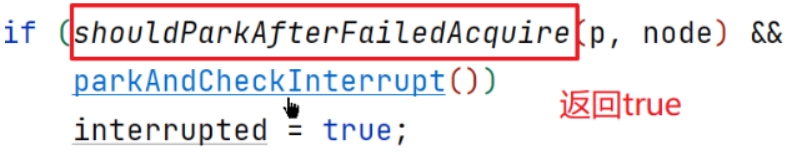
parkAndCheckInterrupt方法,调用park方法将t2线程阻塞private final boolean parkAndCheckInterrupt() {LockSupport.park(this); //阻塞t2线程//以下的代码无法执行,直到别的线程执行unpark方法唤醒t2,才会向下执行return语句return Thread.interrupted();}
- 假设此时持锁线程释放了锁,并唤醒了t2,t2执行
return Thread.interrupted();返回fasle parkAndCheckInterrupt方法返回false,继续进入循环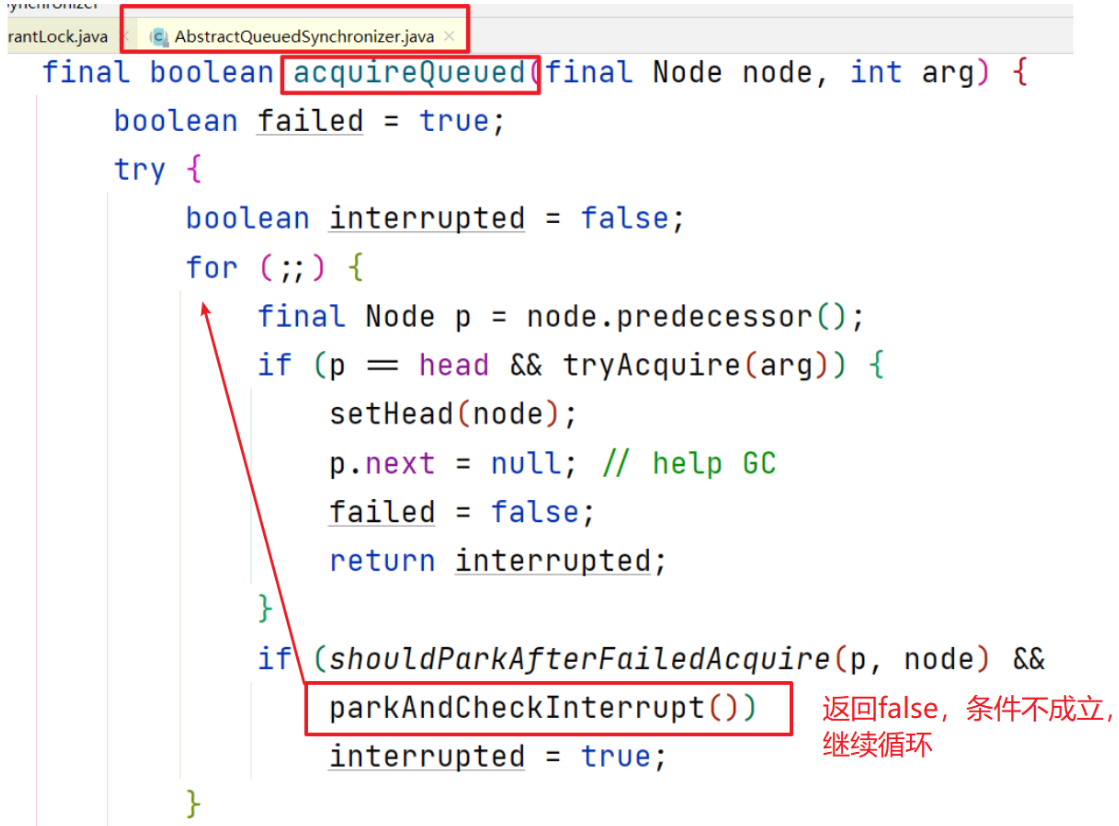
- 执行到第一个if语句,尝试获取锁成功,进入setHead方法
setHead方法分析

- 将第二个节点作为头节点
- 第二个节点中的Thread被置为null(t2现在持有锁,持有锁的线程一定不会在队列中)
第二个节点指向第一个节点的指针变为null,如图:
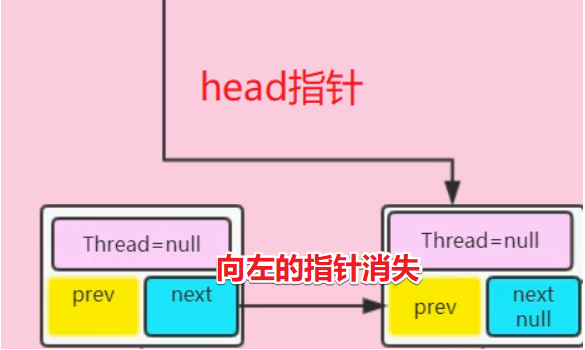
跳出setHead方法,返回上层,继续向下执行

- 将第一个节点指向第二个节点的指针修改为null,第一个节点此时没有任何指向,被GC垃圾回收
renturn false,t2获取了锁,代码持续返回,直到lock方法,继续向下执行
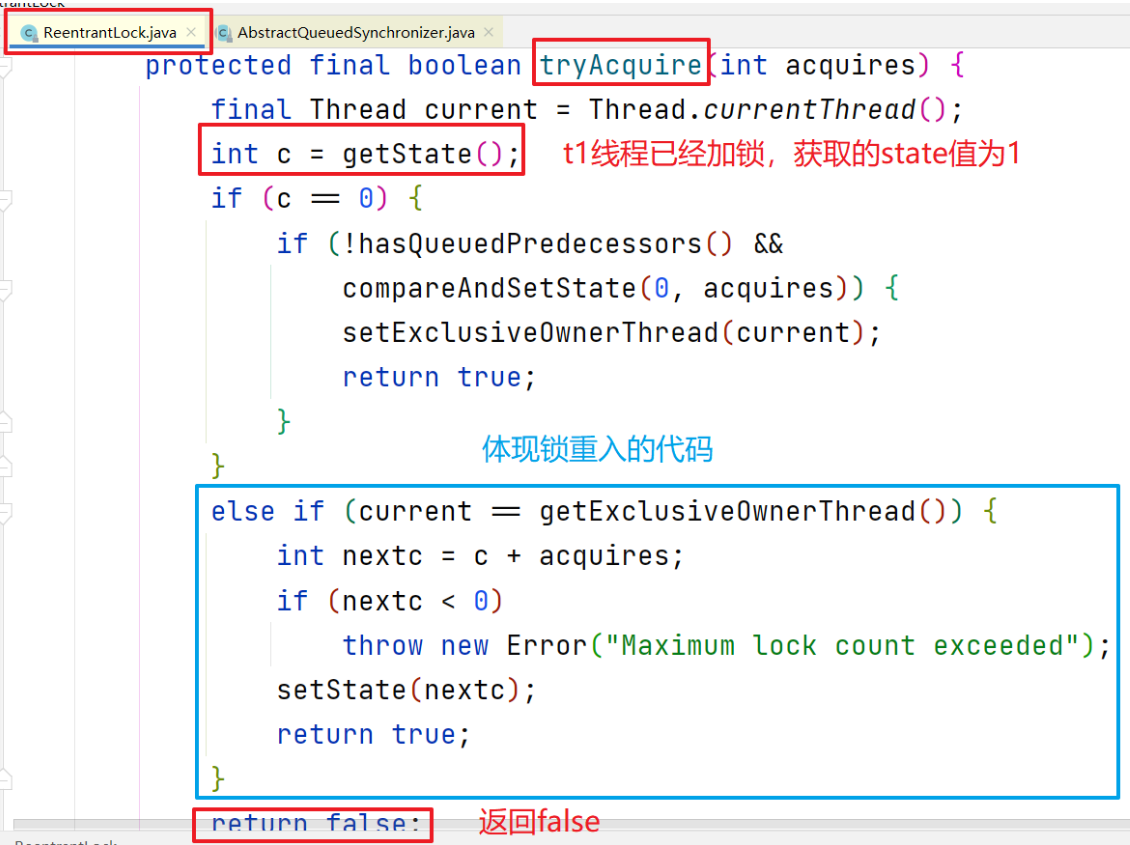
3.1 锁重入的体现
- 当某个线程执行至tryAcquire方法时,有一个if条件判断,尝试获取锁的线程和持有锁的线程进行比较,如果一致,则对state执行加一的操作,表示锁重入
3.2 为什么要修改两次waitStatus的值?
为什么第一次进入
shouldParkAfterFailedAcquire方法时,不直接ws==0就返回true去阻塞,非要多赋值一次呢?为了多自旋一次(第二个节点自旋了两次)
- 延迟调用park的时间,park会涉及到操作系统层面的接口调用,属于重量级锁,消耗资源
- state的每个值都对应着不同的状态
3.3 线程阻塞时的中断情况
如果t2线程如下图1框内容所示,调用park方法阻塞后,又被别的线程中断,那么此方法会向下继续执行,返回true,运行流程如下图所示:
中断后返回true的原因,可以参考博主的另一篇文章,传送地址:interrupt、interrupted 、isInterrupted 区别
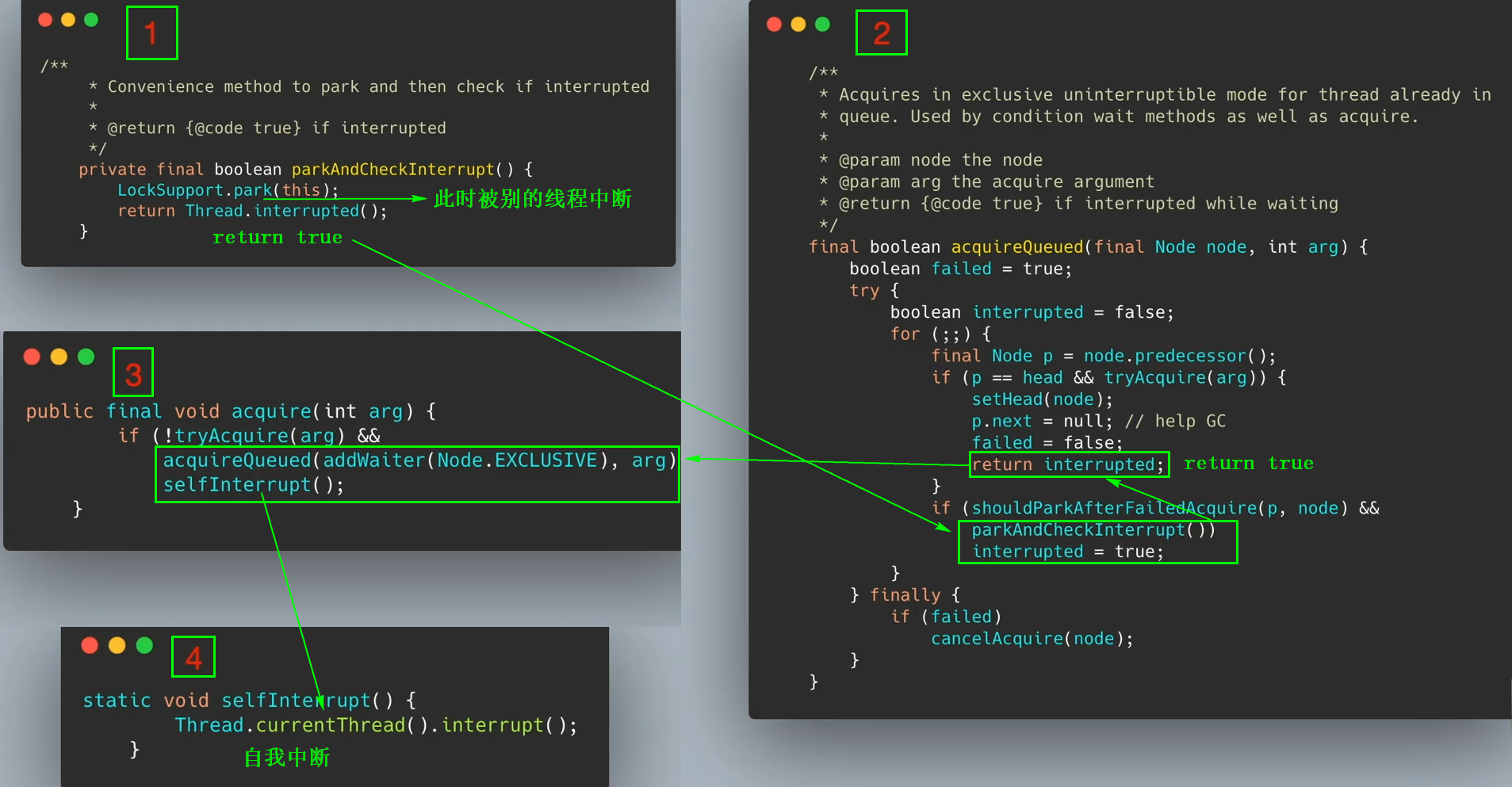
可以发现,当线程处于等待队列时,是无法处理外部中断请求的(线程在上图的4框中又自行中断),只有线程拿到锁之后,才能处理外部请求。
3.4 第三个线程入队的情况
t3线程加入队列之后的情况如下图
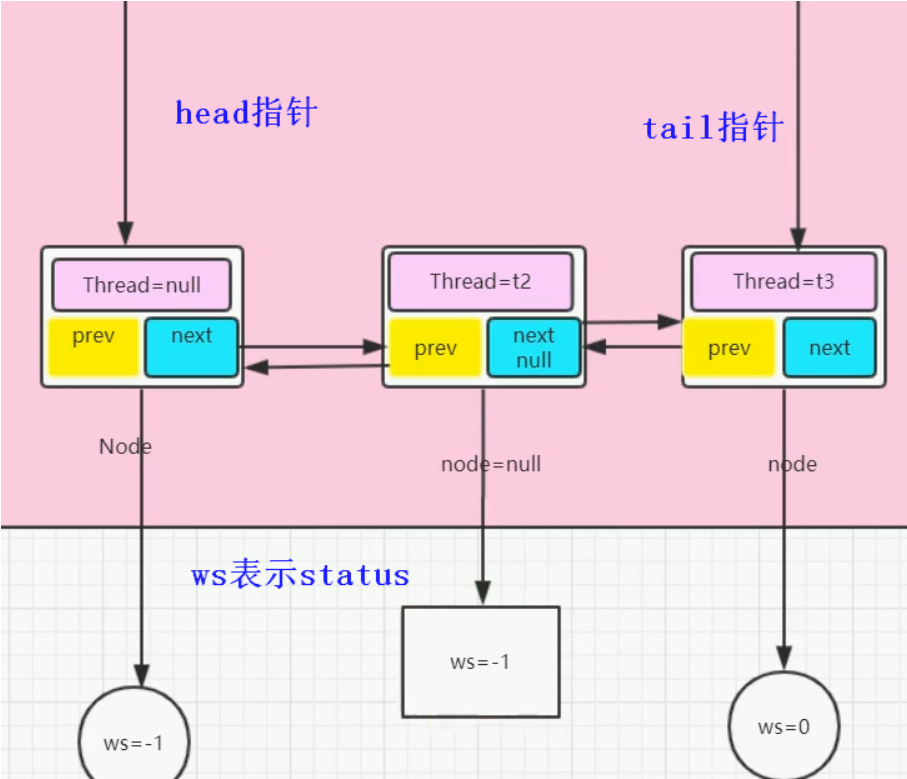
结合之前的源码可以发现,每个线程加入队列之后的status值都为0,status的值会被后一个加入队列的线程修改为-1,而不是自己将status的值修改为-1,原因:
- 在调用park之前,就没有修改status的值,park之后,线程阻塞,自然无法自己修改status的值
- 如果在park之前就自己修改了status的值,如果出现了异常,可能会导致park执行失败,无法阻塞
四、解锁源码分析
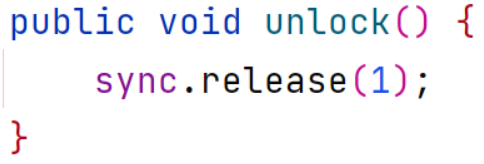
进入:

进入:
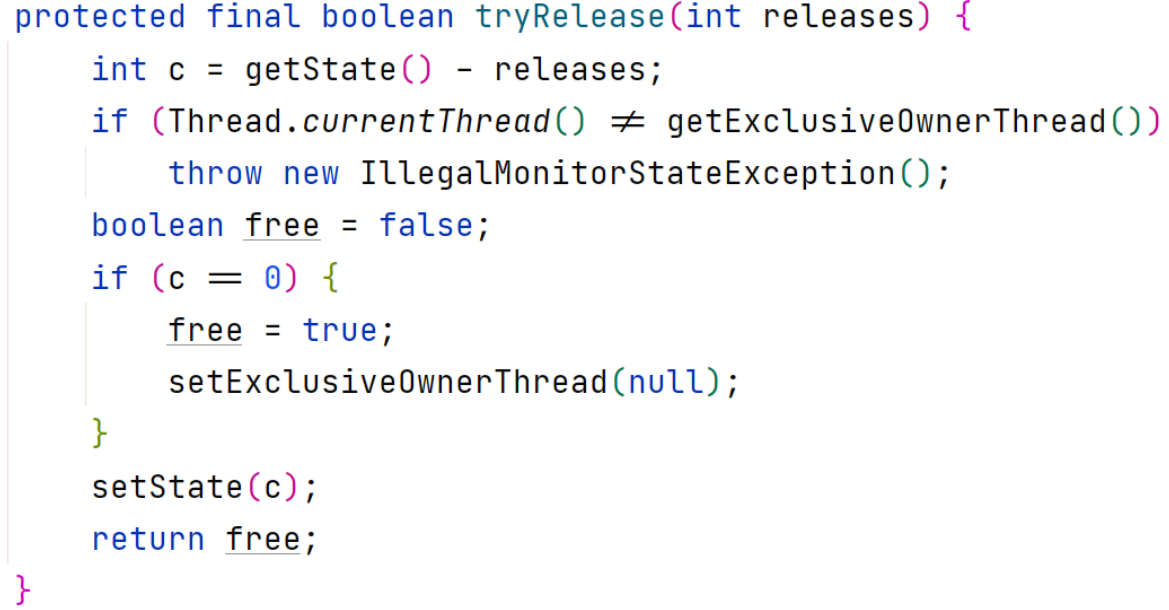
回退,如果不是锁重入则 tryRelease 方法返回值为true:

如果头节点的 waitStatus 值不为0,则说明其之后有节点被阻塞,需要被唤醒(头节点中waitStatus的值如果为-1,他就需要唤醒后一个节点):
//参数node表示头节点,该方法是为了唤醒head的后一个节点,让其自旋的获得锁private void unparkSuccessor(Node node) {//此时head的使命已经完成,只是一个占位的虚节点,需要将其的status置为0,才不会影响其他函数的判断int ws = node.waitStatus;if (ws < 0)compareAndSetWaitStatus(node, ws, 0);Node s = node.next;if (s == null || s.waitStatus > 0) {s = null;//从队列的尾节点开始向前搜索,找到除head节点之外最靠前的且waitStatus值小于等于0dfor (Node t = tail; t != null && t != node; t = t.prev)if (t.waitStatus <= 0)s = t;}//唤醒后一个被阻塞的节点去自旋获得锁if (s != null)LockSupport.unpark(s.thread);}
4.1 为什么从后向前寻找节点?
解锁时有一个方法是为了唤醒 head 的后一个节点,让其自旋的获得锁,即 unparkSuccessor 方法。这个方法的唤醒过程中,是从队列的尾节点开始向前搜索,为什么不是从头开始向后搜索呢?
解答:
在竞争锁的过程中,会执行一个 enq() 方法,这个方法创建队列的头尾节点,将参数节点设置为尾节点,并与头节点组成双向链表:
在执行 if(compareAndSetTail(t, node)) 时,cas 是原子操作, cas 成功后,tail 指向头节点(tail 的prev 指针在 cas 操作之前已经建立),还没有形成双向链表。
当执行 if 代码块里的内容时,不是原子操作,此时若其他线程调用了 unpark 方法(还没有将头节点的 next 指向 tail),从头开始找就无法遍历完整的队列,而从后往前找就可以。


































还没有评论,来说两句吧...