【算法】KMP算法
【fishing-pan:https://blog.csdn.net/u013921430转载请注明出处】
前言
字符串匹配是一个很经典的匹配问题,它的应用非常广泛,比如在DNA序列中查找特定的序列段,在网络搜索引擎中查找某一网址。
常见的字符串匹配方法有一下几种
朴素字符串匹配算法
Rabin-Karp算法
利用有限自动机的匹配方法
KMP方法;
在这篇博客中,主要为大家介绍KMP算法,该算法非常的巧妙,但是在《算法导论》一书中,编者绕来绕去,让人难以理解。在这里,笔者根据自己的理解,用简单易懂的语言来为大家讲讲KMP算法到底说了些什么。
字符串匹配
什么是字符串匹配呢?
这个问题并不复杂,例如,有一个主串T=“abacbcabababbbcbc”,又有一个模式串P=“abababbb”,需要找到模式串P在主串T中的位置。类似于这样的问题就属于字符串匹配的问题。
朴素字符串匹配算法
该算法也称为Brute-Force算法,其基本思想是从主串中的第一个字符起,与模式串的第一个字符相比较,若相等,则继续逐对字符进行后续比较,否则从主串第二个字符起与模式串的第一个字符重新比较,直到模式串中所有字符依次和主串中一个连续的字串序列相等为止,此时称为匹配成功。
时间复杂度
假设主串长度为N,模式串的长度为M,那么设从主串的第i个位置开始与模式串匹配成功,在前i趟匹配中成功的概率相同。那么在最好的情况下每次第一个就不相同,前i次对比了i次,在第i+1次(即主串的第i个位置)进行对比M次,有以下公式可以得出最好的情况下的时间复杂度;
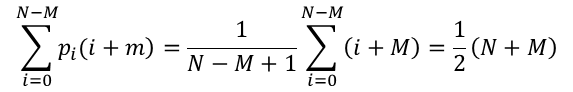
时间复杂度为O(M+N)。
在最坏的情况下,前i次都进行到了模式串的最后一个字符才对比失败,那么前面每次都对比了M次,则有以下公式可以得出最坏的情况下的时间复杂度;
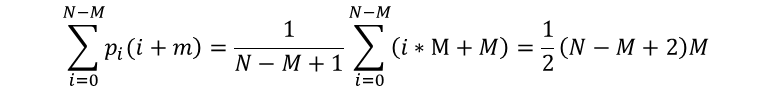
时间复杂度为O(M*N)。
KMP算法
算法概述
KMP算法的全称是Knuth-Morris-Pratt算法,它由Knuth、Morris、Pratt三人设计得出。
刚刚已经介绍过了朴素字符串匹配算法,朴素的方法是非常“笨重”、“死板”的,因为它是逐字符进行对比的,而KMP方法正是在这一基础上做出了改进;
改进之处在于:每当匹配出现了字符不相等时,不需要回溯到主串的下一字符,而是利用已经得到的“部分匹配”结果将模式串向右“移动”尽量远的距离,再继续比较。如下图所示;

当对比到第5位时,出现不匹配,这时候移动模式串,移动的距离不再是1,而是2;如下图所示;

为什么是2呢?这是根据模式串自身的性质得到的。前面的对比已经说明了主串的第2、3、4位分别是a、b、a,这与模式串的第0、1、2位相同。所以直接移动2位,将模式串P的第3位与主串的第5位进行对比。
在此引入三个概念,前缀与后缀。
前缀:串A的长度小于等于串B;且串A与串B前j个字符完全相同,则串A是串B的前缀。例如串A为“ab”,串B为“ababaca”,那么A是B的前缀。
后缀:串A的长度小于等于串B;且串A与串B后j个字符完全相同,则串A是串B的后缀。例如串A为“aca”,串B为“ababaca”,那么A是B的后缀。
最长前后缀:串A、C、D为串B的前缀,同时也是串B的后缀,则串A、C、D中最长的一个串称为串B的最长前后缀。以下为了书写方便,称为前后缀,例如串B=“ababa”,串A=“a”,C=“ab”,D=“aba”,A、C、D同时是B的前缀和后缀,串D是B的最长前后缀。
那么,已知模式串P与主串在第i位出现匹配失败,即第0位到第i-1位匹配正确,如何知道该移动多少步呢?
第0到第i-1位共i位,前i位形成了一个子串,我们称之为Q;
我们需要对Q进行检查,因为Q已经与主串进行了对比,能够为移动步长提供有效信息;我们需要寻找的是Q中所有后缀对应的最长前缀。
例如,Q为“aba”,那么对应的前后缀是第0位的“a”与第2位的“a”;Q为“ababa”,那么对应的最长前后缀是第0至2位的“aba”与第2至4的“aba”;
根据这种匹配关系可以得出下面的表;
j | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
P[j] | a | b | a | b | a | c | a |
前后缀长度 | 0 | 0 | 1 | 2 | 3 | 0 |
|
根据前后缀的关系,可以看出,在匹配失败时,将模式串前缀的位置挪动到与后缀对应的主串的位置即可,并比较前缀的下一位。
那么Next数组表示的是,当模式串的第j位与主串的第i位出现匹配失败后,回溯到模式串的第Next[j]位与主串的第i开始对比。也就是前缀串的下一个位点。
第j位匹配失败,那么0至j-1位匹配成功,这j个字符形成一个子串,子串中有对应的前后缀,我们要做的,是把前缀的位置移到后缀对应的主串的字符位置,然后比较,前缀的后一位与主串中的第i位。假设子串的前后缀长度为k,也就是说模式串的P[0,k-1]位已经成功配对,接下来要对比P[k]位。
如上面图中所示,经过移动后,将前缀的后一位P[3]与T[5]进行比较。
则可以得出下表;
j | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
P[j] | a | b | a | b | a | c | a |
前后缀长度 | 0 | 0 | 1 | 2 | 3 | 0 |
|
Next[j] | 0 | 0 | 0 | 1 | 2 | 3 | 0 |
注:表中Next数组的第j位指出现匹配失败的位置为第j位;那么当0位也匹配失败时,应该将主串序号+1,然后进行比较;
观察可以看出,Next数组其实是将前后缀那一行往后移动的一位,这并不是偶然。举例来说,表中第3位出现匹配失败,说明模式串中序号我0至2的前3位匹配成功,那么前3位构成的字串的前后缀长度为1,也就是说P[0]是已经成功匹配的,接下来需要对比P[1]。
计算移动步长数组Next
其实这个Next数组应该是前后缀长度的数组。Next数组如何求得呢?经过上面的分析,想必大家已经清楚,求Next数组其实就是求前后缀。
首先Next[0],即有零个字符匹配成功,Next[0]=0;同理,Next[1] =0;
假设我们从左到右依次计算next数组,在某一时刻,已经得到了next[0]~next[i],现在要计算next[i+1],设j=next[i],由于知道了next[i],所以我们知道T[0,j-1]=T[i-j,i-1],现在比较T[j]和T[i],如果相等,由next数组的定义,可以直接得出next[i+1]=j+1。
如果不相等,那么我们要将j减小到一个合适的位置s,使s满足 T[0,s]=T[i-s,i];
首先,令next[i]=k,如果P[k]与P[i]不相等,则令k= next[k],再比较P[k]与P[i],如此循环,直到找到位置s为止。
实现代码如下;
void Get_Next(string str, int *next){int len = str.length();next[0] = next[1] = 0;for (int i = 1; i < len; i++){int k = next[i];while (k && str[k] != str[i]){k = next[k];}next[i + 1] = str[i] == str[k] ? k + 1 : 0;}cout << "next数组输出为" << endl;for (int i = 0; i < len; i++){cout <<i<<" "<< next[i] << endl;}}
利用Next数组进行匹配
当第一个字符就出现匹配失败,则应该将主串位点+1,再从模式串第0位开始匹配;
当某一位点匹配成功,则将两个串的位点序号各+1;
当第j+1个字符匹配失败,也就是第j位匹配失败,则利用Next[j]求出前缀串的下一个位点,再进行比对;
代码如下;
int Kmp(string str1,string str2){int slen = str1.length();int plen = str2.length();int *next = new int[plen];Get_Next(str2, next);int i = 0;while ( i < (slen-plen) ){int shift = 0;int j = 0;while (j<=plen){if (j == (plen)) //如果j到达了子串尾部,则输出i的起始位置{return (i - j);}if (str2[j] == str1[i]) //对应位置比较,如果匹配成功,匹配位点各+1;{j++;i++;}else //出现匹配失败{if (j == 0) //如果j=0,比对主串下一个位置;{i++;}else{j = next[j]; //当出现不等时,求出滑行距离}cout << i << " ";}}}return -1;}
算法时间复杂度分析
KMP的算法流程:
假设主串T匹配到 i 位置,模式串P匹配到 j 位置
如果j = -1,或者当前字符匹配成功(即T[i] == P[j]),都令i++,j++,继续匹配下一个字符;
如果j != -1,且当前字符匹配失败(即T[i] != P[j]),则令 i 不变,j = next[j]。其实相当于,模式串P相对于主串T向右移动了j - next [j] 位。”
如果某个字符匹配成功,模式串首字符的位置保持不动,仅仅是i++、j++;如果匹配失配,i 不变,模式串会跳过匹配过的next [j]个字符。整个算法最坏的情况是,当模式串首字符位于i - j的位置时才匹配成功,算法结束。
所以,如果主串的长度为n,模式串的长度为m,那么匹配过程的时间复杂度为O(n),算上计算next的O(m)时间,KMP的整体时间复杂度为O(m + n),是线性的时间复杂度。
完整代码
#include <iostream>#include <string>using namespace std;void Get_Next(string str, int *next){int len = str.length();next[0] = next[1] = 0;for (int i = 1; i < len; i++){int k = next[i];while (k && str[k] != str[i]){k = next[k];}next[i + 1] = str[i] == str[k] ? k + 1 : 0;}cout << "next数组输出为" << endl;for (int i = 0; i < len; i++){cout <<i<<" "<< next[i] << endl;}}int Kmp(string str1,string str2){int slen = str1.length();int plen = str2.length();int *next = new int[plen];Get_Next(str2, next);int i = 0;cout << "主串中的位置为:";while ( i < (slen-plen) ){int shift = 0;int j = 0;while (j<=plen){if (j == (plen)) //如果j到达了子串尾部,则输出i的起始位置{return (i - j);}if (str2[j] == str1[i]) //对应位置比较,如果匹配成功,匹配位点各+1;{j++;i++;}else //出现匹配失败{if (j == 0) //如果j=0,比对主串下一个位置;{i++;}else{j = next[j]; //当出现不等时,求出滑行距离}cout << i << " ";}}}return -1;}int main(){//char *str = "bacbababadababacambabacaddababacasdsd";char *str = "bbabaaabababacabcbc";//char *str = "ababaccababacbababacaa";char *ptr = "ababaca";int *next = new int[8];//Get_Next(ptr, next);int a = Kmp(str, ptr);cout << a << endl;system("pause");return 0;}
#
运行结果

运行结果分析
从运行结果中可以看到next数组的值与表格中的值,是一致的;
而在匹配的过程中的过程如下;
将模式串P的第0位与主串的第0位进行对比,模式串为”a”,主串为“b”;匹配失败,此时j=0;则将i+1;
将模式串P的第0位与主串的第1位进行对比,模式串为”a”,主串为“b”;匹配失败,此时j=0;则将i+1;
将模式串P的第0位与主串的第2位进行对比,模式串为”a”,主串为“a”;匹配成功,此时j+1、i+1;
匹配至模式串的第3位,主串的第5为出现匹配失败,此时查询Next[3]=1;则对比P[1]与T[5];匹配依然失败,查询Next[1]=0;对比对比P[0]与T[5],匹配成功,此时j+1=1,i+1=6;
对比P[1]与T[6],匹配失败,查询Next[1]=0;对比对比P[0]与T[6],匹配成功,此时j+1=1,i+1=7;依次比较到第P[5]与T[11],匹配失败。查询Next[5]=3,比较P[3]与T[11],匹配成功,一直匹配到T[14],匹配成功,返回首位8。
后续
其实大家可以看到KMP算法还可以进行优化,至于如何优化,下次有时间再写给大家,最近事情太多,写这么多已经很不容易了;


































还没有评论,来说两句吧...