使用JSOUP爬取国家统计局的地理位置数据
最近因工作需要,我需要爬取国家统计局的最新统计数据。因此参照网上的例子使用JSOUP爬取了国家统计局的省、市、县、镇、村的数据。因为要爬取的数据较多,因此在里面使用了多线程的相关技术。下面首先讲解下多线程相关的东西。
首先理解下什么是线程池?
因为创建和销毁线程是一件非常耗费时间的工作,因此,如果线程可以再一定程度上复用,那么肯定可以再节省不少的时间。线程池的作用可以类比MYSQL中的连接池理解。
参考文章:Java常用四大线程池用法以及ThreadPoolExecutor详解
其次是多线程中的Future模式。
因为爬取的省份较多,因此需要多个线程并发执行,但是必须保证在IO操作的写操作执行前,所有的数据都已经爬取完毕。因此,必须使用多线程的Future模式,Future模式可以保证多个线程并发执行,并且可以通过future.get()方法在适当的地方进行线程堵塞,保证在结果输出前各个子线程已经执行结束。因为在调用到某个子线程的future.get()方法之前,各个子线程会继续并发执行,因此,调用future.get()方法阻塞主线程消耗的时间会非常的少,因此可以再一定的程度上节省时间开销。
/** * 等待所有的子线程执行完毕 */for (Future future : futureList) {future.get();}
Future模式的参考文章:Java多线程 - Future模式
最后讲述下说说Runnable与Callable的区别:
二者的实际异同为以下几点:
相同点:
1、 两者都是接口;(废话)
2、两者都可用来编写多线程程序;
3、两者都需要调用Thread.start()启动线程;
不同点:
1、两者最大的不同点是:实现Callable接口的任务线程能返回执行结果;而实现Runnable接口的任务线程不能返回结果;
2、Callable接口的call()方法允许抛出异常;而Runnable接口的run()方法的异常只能在内部消化,不能继续上抛;
注意点:
Callable接口支持返回执行结果,此时需要调用FutureTask.get()方法实现,此方法会阻塞主线程直到获取‘将来’结果;当不调用此方法时,主线程不会阻塞!
参考文章:说说Runnable与Callable
下面是使用Jsoup爬取国家统计局数据的具体代码: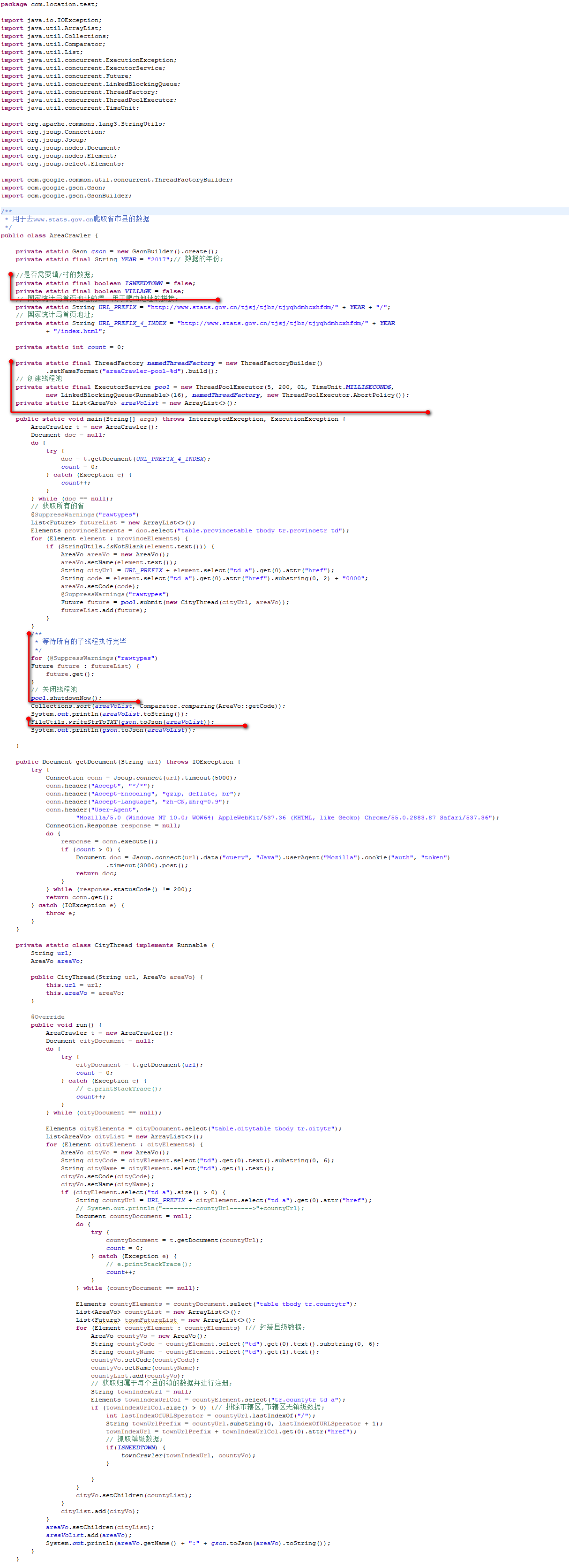
源码:Jsoup爬取国家统计局的数据


























拓扑排序")

")





还没有评论,来说两句吧...