Python 抓取知乎图片(selenium的示例)
搭建Selenium运行环境
安装selenium
pip install selenium
安装ChromeDriver
注:笔者使用的是Chrome浏览器,需要安装对应版本的 ChromeDriver。
先在Chrome浏览器输入,查看浏览器版本(chrome://version/),再下载对应版本的ChromeDriver
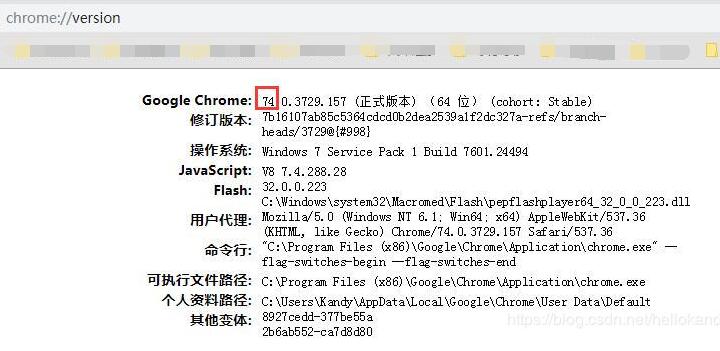
下载地址(以下两个都可以):
https://sites.google.com/a/chromium.org/chromedriver/downloads
http://chromedriver.storage.googleapis.com/index.html
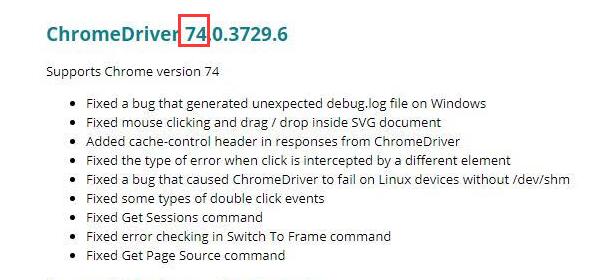
选择对应版本下载:
示例代码
测试,运行以下脚本,最终打开百度网址,证明运行成功。
import reimport timeimport urllib.requestfrom selenium import webdriverchrome_driver = 'G:\\software_develop_tools\\chromedriver.exe'driver = webdriver.Chrome(executable_path = chrome_driver)driver.maximize_window()driver.get("https://www.baidu.com")# 通过get()方法,打开一个url站点
小试牛刀,抓取知乎上的图片:
#-*- coding: utf-8 -*-import reimport timeimport urllib.requestfrom selenium import webdriverchrome_driver = 'G:\\software_develop_tools\\chromedriver.exe'driver = webdriver.Chrome(executable_path = chrome_driver)#driver = webdriver.Chrome()#driver = webdriver.Firefox()driver.maximize_window()driver.get("https://www.zhihu.com/question/29134042")i = 0while i < 10:driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")time.sleep(2)try:driver.find_element_by_css_selector('button.QuestionMainAction').click()print("page" + str(i))time.sleep(1)except:breakresult_raw = driver.page_source #网页源代码content_list = re.findall("img src=\"(.+?)\" ", str(result_raw))n = 0while n < len(content_list):print( 'content_list[%d] : %s' % (n, content_list[n]) )_time = time.time()_file = ('C:\\Users\\Kandy\\Desktop\\zhihu\\%s.jpg' % (str(_time)))urllib.request.urlretrieve(content_list[n], _file)n = n + 1

























——管道符")
——通配符与其他特殊符号")


地图制作")




还没有评论,来说两句吧...