Scrapy Selenium实战:Selenium登录知乎保存cookies后访问需要登录页面
Scrapy Selenium实战:Selenium登录知乎保存cookies后访问需要登录页面
- 安装
- chromedriver
- 新建爬虫
- zhihu.py
- 获取浏览器真实的User-Agent
- 执行验证
selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
安装
#进入虚拟目录cd /data/code/python/venv/venv_Scrapy/tutorial#升级安装../bin/pip3 install -U selenium
chromedriver
我们这里用 Chrome 浏览器来做自动化,我自己本身Chrome版本是
所以我们对应到 http://chromedriver.storage.googleapis.com/index.html 网址下载对应版本的chromedriver
新建爬虫
#进入虚拟目录cd /data/code/python/venv/venv_Scrapy/tutorial#新建爬虫../bin/python3 ../bin/scrapy genspider -t basic zhihu www.zhihu.com
这里我们可以把下载下来的chromedriver放在/data/code/python/venv/venv_Scrapy/tutorial目录下
zhihu.py
# -*- coding: utf-8 -*-import scrapyimport jsonfrom selenium import webdriverimport timefrom pathlib import Pathclass ZhihuSpider(scrapy.Spider):name = 'zhihu'allowed_domains = ['www.zhihu.com']start_urls = ['http://www.zhihu.com/']# 模拟请求的headers,非常重要,不设置也可能知乎不让你访问请求headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36","HOST": "www.zhihu.com"}# scrapy请求的开始时start_requestdef start_requests(self):zhihu_findUrl = 'https://www.zhihu.com/notifications'if not Path('zhihuCookies.json').exists():__class__.loginZhihu() # 先执行login,保存cookies之后便可以免登录操作# 毕竟每次执行都要登录还是挺麻烦的,我们要充分利用cookies的作用# 从文件中获取保存的cookieswith open('zhihuCookies.json', 'r', encoding='utf-8') as f:listcookies = json.loads(f.read()) # 获取cookies# 把获取的cookies处理成dict类型cookies_dict = dict()for cookie in listcookies:# 在保存成dict时,我们其实只要cookies中的name和value,而domain等其他都可以不要cookies_dict[cookie['name']] = cookie['value']# Scrapy发起其他页面请求时,带上cookies=cookies_dict即可,同时记得带上header值,yield scrapy.Request(url=zhihu_findUrl, cookies=cookies_dict, callback=self.parse, headers=__class__.headers)#使用selenium登录知乎并获取登录后的cookies,后续需要登录的操作都可以利用cookies@staticmethoddef loginZhihu():# 登录网址loginurl = 'https://www.zhihu.com/signin'# 加载webdriver驱动,用于获取登录页面标签属性driver = webdriver.Chrome('/data/code/python/venv/venv_Scrapy/tutorial/chromedriver')#加载页面driver.get(loginurl)time.sleep(3) # 执行休眠3s等待浏览器的加载# 方式1 通过填充用户名和密码# driver.find_element_by_name('username').clear() # 获取用户名框# driver.find_element_by_name('username').send_keys(u'username') # 填充用户名# driver.find_element_by_name('password').clear() # 获取密码框# driver.find_element_by_name('password').send_keys(u'password') # 填充密码# input("检查网页是否有验证码要输入,有就在网页输入验证码,输入完后,控制台回车;如果无验证码,则直接回车")# # 点击登录按钮,有时候知乎会在输入密码后弹出验证码,这一步之后人工校验# driver.find_element_by_css_selector("button[class='Button SignFlow-submitButton Button--primary Button--blue']").click()## input_no = input("检查网页是否有验证码要输入,有就在网页输入验证码,输入完后,控制台输入1回车;如果无验证码,则直接回车")# if int(input_no) == 1:# # 点击登录按钮# driver.find_element_by_css_selector(# "button[class='Button SignFlow-submitButton Button--primary Button--blue']").click()# 方式2 直接通过扫描二维码,如果不是要求全自动化,建议用这个,非常直接,毕竟我们这一步只是想保存登录后的cookies,至于用何种方式登录,可以不必过于计较driver.find_element_by_css_selector("button[class='Button Button--plain']").click()input("请扫描页面二维码,并确认登录后,点击回车:") # 点击二维码手机扫描登录time.sleep(3) # 同样休眠3s等待登录完成input("检查网页是否有完成登录跳转,如果完成则直接回车")# 通过上述的方式实现登录后,其实我们的cookies在浏览器中已经有了,我们要做的就是获取cookies = driver.get_cookies() # Selenium为我们提供了get_cookies来获取登录cookiesdriver.close() # 获取cookies便可以关闭浏览器# 然后的关键就是保存cookies,之后请求从文件中读取cookies就可以省去每次都要登录一次的# 当然可以把cookies返回回去,但是之后的每次请求都要先执行一次login没有发挥cookies的作用jsonCookies = json.dumps(cookies) # 通过json将cookies写入文件with open('zhihuCookies.json', 'w') as f:f.write(jsonCookies)print(cookies)def parse(self, response):#这里打印出https://www.zhihu.com/notifications页面中登录者的昵称验证带上cookies登录完成print(response.xpath('//div[@class="top-nav-profile"]/a/span[@class="name"]/text()').extract_first())print("*" * 40)#print("response text: %s" % response.text)print("response headers: %s" % response.headers)print("response meta: %s" % response.meta)print("request headers: %s" % response.request.headers)print("request cookies: %s" % response.request.cookies)print("request meta: %s" % response.request.meta)
代码注释写的很清楚,就不细说了,这里需要注意,建议把User-Agent 设置为真实的User-Agent。
获取浏览器真实的User-Agent
访问 https://www.zhihu.com/signin 查看任意请求的headers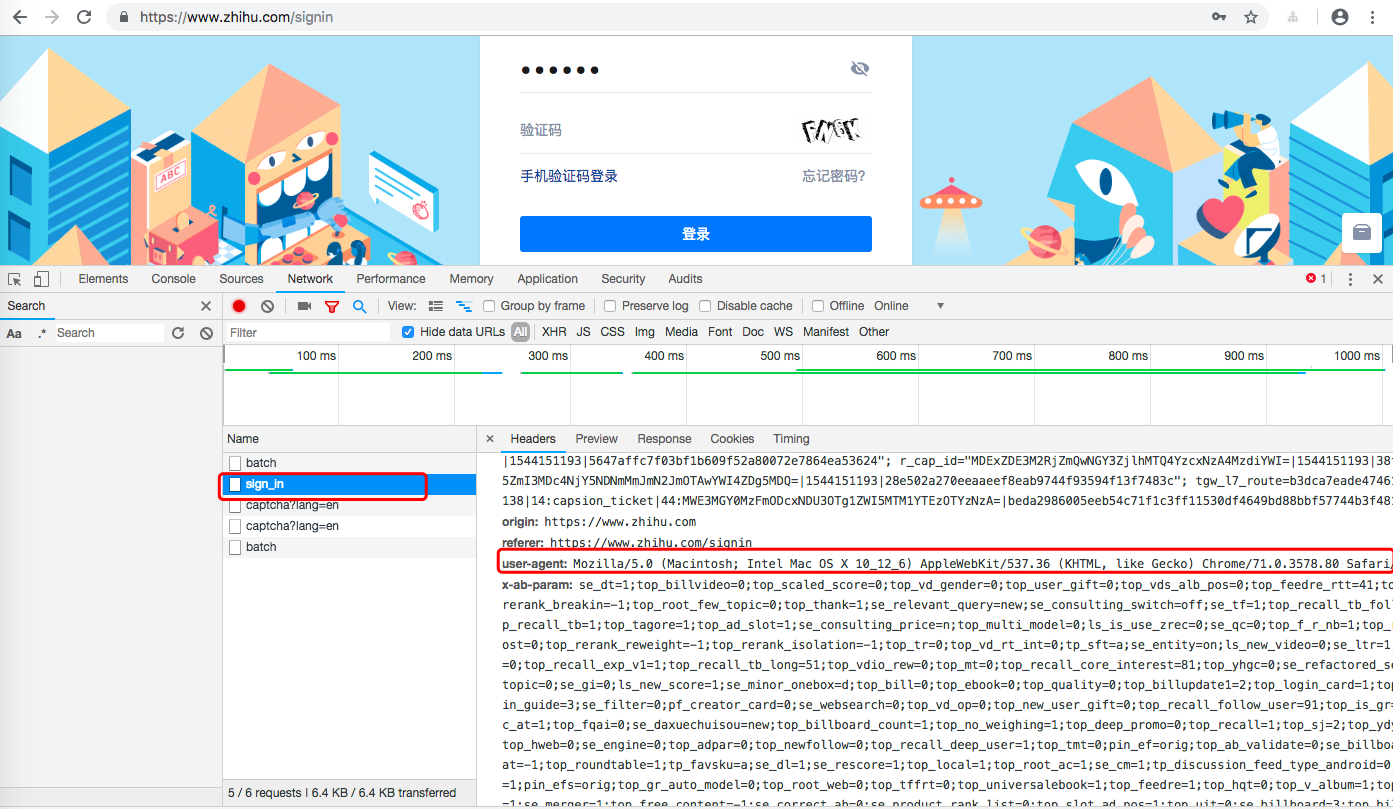
执行验证
我们这里的爬虫很简单,只需要打印出 https://www.zhihu.com/notifications 页面中登录者的昵称
GitHub源代码




























还没有评论,来说两句吧...