进一步学习mysql
在开放中,会员的优化,往往上把频繁用到的信息,优先考虑效率,存储到一张表中,不常用的信息和比较占空间的信息,优先考虑空间占用,存储到辅表中。
一、建表语法:
声明列的过程
create table 表名(
列1声明 列1参数
列2声明 列2参数
… …
列n声明 列n参数
)engine myisam /innodb/bdb charset utf8/gbk/latinl…
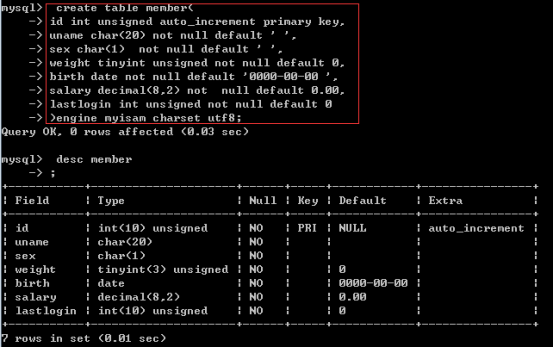
create table member(
id int unsigned auto_increment primary key,
uname char(20) not null default ‘ ‘,
sex char(1) not null default ‘ ‘,
weight tinyint unsigned not null default 0,
birth date not null default ‘0000-00-00 ‘,
salary decimal(8,2) not null default 0.00,
lastlogin int unsigned not null default 0
)engine myisam charset utf8;
①增加新列到表的最后:
alter table 表名 add 列名称 列类型 列参数
②增加新列到表的某列的后面:
alter table 表名 add 列名称 列类型 列参数 after 某列名称
③增加新列到表的最前面:
alter table 表名 add 列名称 列类型 列参数 first
④删除列:
alter table 表名 drop 列名称
⑤修改列类型:
alter table 表名 modify 列名称 新类型 新参数
⑥修改列名和列类型
alter table 表名 change 旧列名称 新列名称 新类型 新参数
⑦查询select的五种句子
(1)Where条件查询
(2)group 分组查询
(3)having 筛选查询
(4)order 排序查询
(5)limit 限制条件查询
比较运算符
| 运算符 | 说明 | 运算符 | 说明 |
| < | 小于 | !=或<> | 不等于 |
| <= | 小于或等于 | >= | 大于或等于 |
| = | 等于 | > | 大于 |
| in | 在某集合内 | between | 在某范围内 |
逻辑运算符
| 运算符 | 说明 |
| NOT 或! | 逻辑非 |
| OR或|| | 逻辑或 |
| AND或&& | 逻辑与 |
1、查询主键为32的商品
select goods_id,goods_name,shop_price from ecs_goods where goods_id=32;
2、查询2不属于第3栏目的商品
select goods_id,cat_id,goods_name,shop_price from ecs_goods where cat_id!=32;
3、本店价格高于3000元的商品
select goods_id,cat_id,goods_name,shop_price from ecs_goods where shop_price>32;
4、本店价格低于或等于100元的商品
select goods_id,cat_id,goods_name,shop_price from ecs_goods where shop_price<=100;
5、取出第4栏目或第11栏目的商品(不可以用or)
select goods_id,cat_id,goods_name,shop_price from ecs_goods where cat_id in (4,11);
6、取出100<=价格<=500的商品(不可以用and)
select goods_id,cat_id,goods_name,shop_price from ecs_goods where shop_price between 100and500;
7、取出不在第3栏目和不在第11栏目的商品(and和not in 分别实现)
select goods_id,cat_id,goods_name,shop_price from ecs_goods where cat_id !=3 and cat_id!=11;
select goods_id,cat_id,goods_name,shop_price from ecs_goods where cat_id not in(3,11);
8、取出价格大于100且小于300,或者大于4000且小于5000的商品。
select goods_id,cat_id,goods_name,shop_price from ecs_goods where (shop_price>100 and shop_price<100) or (shop\_price>4000 and shop_price<5000);
9、取出第3个栏目下面价格在1000到3000之间并且点击量>5“诺基亚”开头的系列商品
select goods_id,cat_id,goods_name,shop_price from ecs_goods where cat_id=3 and (shop_price>1000 and shop_price<3000) and click\_count>5 and goods_name like ‘诺基亚%’;
10、取出第3个栏目下面价格小于1000或大于3000,并且点击量>5“的系列商品。
select goods_id,cat_id,goods_name,shop_price,click_count from ecs_goods where cat_id=3 and (shop_price<1000 or shop\_price>3000) and click_count>5 ;
11、取出第1个栏目下面的商品(注意1栏目下面没有商品,但其子栏目下有)
select goods_id,cat_id,goods_name,shop_price,click_count from ecs_goods where cat_id
in (2,3,4,5);
12、取出名字以“诺基亚”开头的商品(‘like’模糊匹配‘%’表示通配任意字符)
select goods_id,cat_id,goods_name,shop_price from ecs_goods where goods_name like ‘诺基亚%’;
13、取出名字为“诺基亚Nxx”的商品
select goods_id,cat_id,goods_name,shop_price from ecs_goods where goods_name like ‘诺基亚Nxx__’;(__是由两个下划线组成,一个下划线表示匹配一个任意字符)
14、把num处于[20,29]之间的值改为20,处于[30,39]之间的值改为30。
Update main set num=floor(num/10)*10 where num>=20 and num<=39;
15、floor(X)返回不大于X的最答整数值如:floor(1.23)—>1,floor(-1.23)—> -2
substr(str,pos,len)函数:不带有len参数的格式,从字符串str返回一个子字符串,起始于位置pos。带有len参数格式的,从字符串str返回一个长度和len一样的子字符串,起始于位置pos。Pos是负值时起始于末尾字符。
如substr(‘sahdhdja’,3)—>hdhdja;substr(‘sahdhdja’,4,3)—>dhd;substr(‘sahdhdja’,-3)—>dja;
substr(‘sahdhdja’,-6,3)—>hdh;
二、分组查询
1、查询出最贵的商品的价格
selsct max(shop_price ) from ecs_goods;
2、查询出最大(最新)的商品的编号
selsct max(goods_id ) from ecs_goods;
3、查询出最便宜的商品的价格
selsct min(shop_price ) from ecs_goods;
4、查询出最小(最旧)的商品的编号
selsct min(goods_id ) from ecs_goods;
5、查看商店一工有多少件商品
selsct sum(goods_number ) from ecs_goods;
6、查看商店里所有商品的平均价格
selsct avg(goods_price ) from ecs_goods;
7、查看商店里一共有多少种商品
selsct count(* ) from ecs_goods;
select count(*) from 表名 查询的是绝对的行数,哪怕某行所以字段全为null,也计算在内。
select count(列名) from表名 查询的是该列不为null的所有行数。
8、用select count(*) from 表名和select count(1) from 表名哪个更好?
对于myisamy 引擎表没有区别,它内部有一个计算器在维护着行数;但对于innodb引擎的表用select count(*) from 表名效率较低,因为它真的要去数一遍。
9、上面五个统计函数单独使用意义不大,要和分组配合起来使用才突出他们的价值。
(1)统计第三个栏目下所有商品的库存量之和。
selsct sum(goods_number ) from ecs_goods where cat_id=3;
(2)一次计算完,每个栏目下的库存量之和。
select goods_id,sum(good_number) from ecs_goods group by cat_id;
(3)用having进行过滤数据
比如查询本店价比市场价省的钱,并且要求省钱200以上的取出来
select goods_id,market_price,shop_price,(market_price-shop_price)as discount from ecs_goods where 1 having discount>200;
(4)Having与group综合运用
(a)、查询该店的商品比市场价所省的价格
select goods_id,market_price,shop_price,(market_price-shop_price)as discount from ecs_goods;
(b)、查询每种商品所积压的货款(提示:库存*单价)
select goods_id,goods_name,goods_number*shop_price from ecs_goods;
(c)、查询该店积压的总货款
select sum(goods_number*shop_price) from ecs_goods;
(d)、查询该店每个栏目下积压的货款
select cat_id, sum(goods_number*shop_price) as k from ecs_goods group by cat_id ;
(e)、查询比市场价省钱大于200元的商品及该商品所省的钱(where和having分别实现)
select goods_id,market_price,shop_price,(market_price-shop_price)as discount from ecs_goods where (market_price-shop_price)>200;
select goods_id,market_price,shop_price,(market_price-shop_price)as discount from ecs_goods having discount >200;
(f)、查询积压货款超过2w元的栏目,以及该栏目积压的货款
select cat_id,sum(goods_number*shop_price)as discount from ecs_goods group by cat_id having discount >20000;
(g)、查询学生挂科数大于等于2门课的学生的平均分数
select name,avg(score),sum(score<60)as gks from result group by name having gks >=2;
10、Order by shop_price desc 按shop_price字段从高排到低(降序排)
Order by shop_price asc是升序排
针对结果集进行排序
多段字符段排序:order by 列1 desc/ asc,列2 desc/ asc,列3 desc/ asc…
Limit 在语句的最后,起到限制条目的作用。
(1)查询出本店最高的,第3名到第5名的商品
select goods_id,goods_name,shop_price from ecs_goods order by shop_price desc limit 2,3 ;
(2)取出价格最高的那一种商品
select goods_id,goods_name,shop_price from ecs_goods order by shop_price desc limit 0,1 ;
offset为0时,可以不写即:
select goods_id,goods_name,shop_price from ecs_goods order by shop_price desc limit 1 ;
11、子查询
1、查询出本商店最新(goods_id最大)的一条商品
select goods_id,goods_name,shop_price from ecs_goods order by goods_id desc limit 1;
2、查询出本商店最新(goods_id最大)的一条商品,要求不能使用排序。
(以后凡是需要查询最新的商品,先用max()查出最大的goods_id,再根据goods_id查询商品)
select goods_id,goods_name from ecs_goods where goods_id=(select max( goods_id) from ecs_goods);
①Where 型子查询:指把内层查询的结果作为外层查询的条件
如果 where 列=(内层sql),则内层sql返回的必是单行单列,单个值。
select goods_id,goods_name from ecs_goods where goods_id in (select max( goods_id) from ecs_goods group by cat_id);
如果 where 列in(内层sql),则内层sql只返回单列,可以多行。
②from型子查询
把内层sql的查询结果作为一张临时表,供外层sql再此查询。
select * from (select goods_id,cat_id,goods_name from ecs_goods order by cat_id asc,order by goods_id desc ) as tmp group by cat_id;
③exists 型子查询(要有2张表)
是指把外层sql的结果,拿到内层aql去测试,如果内层sql成立,则该行取出。
select cat_id,cat_name from category where exists (select * from ecs_goods where ecs_goods.cat_id =category.cat_id) ;
12、为什么建表是加 not null default ‘’/default 0
答:为了不让表中出现null值。(①不好比较。nul比较需要用is null和is not nulll,用其他的运算符比较,全部返回NULL②效率低。影响提供索引效果)
13、左连接:
假设A表在左,不动,B表在A表的右边滑动,A表与B表通过一个关系来筛选B表。
A left join B on 条件(当条件为真时,将取出B表对应的值)
把goods left join category on goods.cat_id =category.cat_id看作c表
select goods_id,goods_name,goods_number,shop_price,cat_name from goods left join category on goods.cat_id =category.cat_id;
A left join B on 条件相当于B right join A on 条件
14、内连接,A表和B表匹配时才取出数据,而左右连接不匹配时没有数据的显示NULL。
A inner B on 条件
Union(连接查询)合并两个结果集,不区分来于哪张表
Sql1 union sql2
例如:select goods_id,goods_number ,shop_price from goods where shop_price<30
union select goods_id,goods_number ,shop_price from goods where shop_price>4000
取自两张表通过“别名”让2个结果集的列一致,那么,如果取出的结果集、列名不一样,则取出的最终列名以第一条语句为准。
select user_name,msg_content ,msg_time from feedback where msg_status=1
union select user_name,content as msg_content ,msg_time as msg_time from content where status=1
只要两个结果集列数量一致就可以用union
union合并两个结果集之后还可以排序(针对最终结果集进行再排序)。
select goods_id,cat_id,goods_name ,shop_price from goods where cat_id=3
union select goods_id,cat_id,goods_name ,shop_price from goods where cat_id=5
order by shop_price asc;
外层order by要对结果集进行排序,则内层order by排序就没意义了,(内层的order by单独使用,不会影响结果集,仅影响排序时,在执行期间被mysql的代码分析器给优化掉了
内层order by 必须能够影响结果集时,才有意义,比如配合limit使用。)
union合并两个结果集默认会去重。不想去重:用union all
将两表中相同数据进行相加
ta表:
| id | num |
| a | 5 |
| b | 10 |
| c | 15 |
| d | 10 |
tb表
| id | num |
| b | 5 |
| c | 15 |
| d | 20 |
| e | 99 |
查出以下效果:
| id | sum(num) |
| a | 5 |
| b | 15 |
| c | 30 |
| d | 30 |
| e | 99 |
select id,sum(num) from(select * from ta union all select * from tb) as tmp group by id ;
三、Msql常见函数
1、数学函数
ABS(x) 返回x的绝对值
BIN(x) 返回x的二进制(OCT返回八进制,HEX返回十六进制)
CEILING(x) 返回大于x的最小整数值
EXP(x) 返回值e(自然对数的底)的x次方
FLOOR(x) 返回小于x的最大整数值
GREATEST(x1,x2,…,xn)返回集合中最大的值
LEAST(x1,x2,…,xn) 返回集合中最小的值
LN(x) 返回x的自然对数
LOG(x,y)返回x的以y为底的对数
MOD(x,y) 返回x/y的模(余数)
PI()返回pi的值(圆周率)
RAND()返回0到1内的随机值,可以通过提供一个参数(种子)使RAND()随机数生成器生成一个指定的值。
ROUND(x,y)返回参数x的四舍五入的有y位小数的值
SIGN(x) 返回代表数字x的符号的值
SQRT(x) 返回一个数的平方根
TRUNCATE(x,y) 返回数字x截短为y位小数的结果
2、聚合函数(常用于GROUP BY从句的SELECT查询中)
AVG(col)返回指定列的平均值
COUNT(col)返回指定列中非NULL值的个数
MIN(col)返回指定列的最小值
MAX(col)返回指定列的最大值
SUM(col)返回指定列的所有值之和
GROUP_CONCAT(col) 返回由属于一组的列值连接组合而成的结果
3、字符串函数
ASCII(char)返回字符的ASCII码值
BIT_LENGTH(str)返回字符串的比特长度
CONCAT(s1,s2…,sn)将s1,s2…,sn连接成字符串
CONCAT_WS(sep,s1,s2…,sn)将s1,s2…,sn连接成字符串,并用sep字符间隔
INSERT(str,x,y,instr) 将字符串str从第x位置开始,y个字符长的子串替换为字符串instr,返回结果
FIND_IN_SET(str,list)分析逗号分隔的list列表,如果发现str,返回str在list中的位置
LCASE(str)或LOWER(str) 返回将字符串str中所有字符改变为小写后的结果
LEFT(str,x)返回字符串str中最左边的x个字符
LENGTH(s)返回字符串str中的字符数
LTRIM(str) 从字符串str中切掉开头的空格
POSITION(substr,str) 返回子串substr在字符串str中第一次出现的位置
QUOTE(str) 用反斜杠转义str中的单引号
REPEAT(str,srchstr,rplcstr)返回字符串str重复x次的结果
REVERSE(str) 返回颠倒字符串str的结果
RIGHT(str,x) 返回字符串str中最右边的x个字符
RTRIM(str) 返回字符串str尾部的空格
STRCMP(s1,s2)比较字符串s1和s2
TRIM(str)去除字符串首部和尾部的所有空格
UCASE(str)或UPPER(str) 返回将字符串str中所有字符转变为大写后的结果
4、日期和时间函数
CURDATE()或CURRENT_DATE() 返回当前的日期
CURTIME()或CURRENT_TIME() 返回当前的时间
TIMESTAMPDIFF(part, date1,date2) 返回date1到date2之间相隔的part值,part是用于指定的相隔的年或月或日等
DATE_ADD(date,INTERVAL int keyword)返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE_ADD(CURRENT_DATE,INTERVAL 6 MONTH);
DATE_FORMAT(date,fmt) 依照指定的fmt格式格式化日期date值
DATE_SUB(date,INTERVAL int keyword)返回日期date加上间隔时间int的结果(int必须按照关键字进行格式化),如:SELECTDATE_SUB(CURRENT_DATE,INTERVAL 6 MONTH);
DAYOFWEEK(date) 返回date所代表的一星期中的第几天(1~7)
DAYOFMONTH(date) 返回date是一个月的第几天(1~31)
DAYOFYEAR(date) 返回date是一年的第几天(1~366)
DAYNAME(date) 返回date的星期名,如:SELECT DAYNAME(CURRENT_DATE);
FROM_UNIXTIME(ts,fmt) 根据指定的fmt格式,格式化UNIX时间戳ts
HOUR(time) 返回time的小时值(0~23)
MINUTE(time) 返回time的分钟值(0~59)
MONTH(date) 返回date的月份值(1~12)
MONTHNAME(date) 返回date的月份名,如:SELECT MONTHNAME(CURRENT_DATE);
NOW() 返回当前的日期和时间
QUARTER(date) 返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT_DATE);
WEEK(date) 返回日期date为一年中第几周(0~53)
YEAR(date) 返回日期date的年份(1000~9999)
一些示例:
获取当前系统时间:SELECT FROM_UNIXTIME(UNIX_TIMESTAMP());
SELECT EXTRACT(YEAR_MONTH FROM CURRENT_DATE);
SELECT EXTRACT(DAY_SECOND FROM CURRENT_DATE);
SELECT EXTRACT(HOUR_MINUTE FROM CURRENT_DATE);
返回两个日期值之间的差值(月数):SELECT PERIOD_DIFF(200302,199802);
在Mysql中计算年龄:
SELECT DATE_FORMAT(FROM_DAYS(TO_DAYS(NOW())-TO_DAYS(birthday)),’%Y’)+0 AS age FROM employee;
这样,如果Brithday是未来的年月日的话,计算结果为0。
下面的SQL语句计算员工的绝对年龄,即当Birthday是未来的日期时,将得到负值。
SELECT DATE_FORMAT(NOW(), ‘%Y’) - DATE_FORMAT(birthday, ‘%Y’) -(DATE_FORMAT(NOW(), ‘00-%m-%d’) <DATE_FORMAT(birthday, ‘00-%m-%d’)) AS age from employee
5、加密函数
AES_ENCRYPT(str,key) 返回用密钥key对字符串str利用高级加密标准算法加密后的结果,调用AES_ENCRYPT的结果是一个二进制字符串,以BLOB类型存储
AES_DECRYPT(str,key) 返回用密钥key对字符串str利用高级加密标准算法解密后的结果
DECODE(str,key) 使用key作为密钥解密加密字符串str
ENCRYPT(str,salt) 使用UNIXcrypt()函数,用关键词salt(一个可以惟一确定口令的字符串,就像钥匙一样)加密字符串str
ENCODE(str,key) 使用key作为密钥加密字符串str,调用ENCODE()的结果是一个二进制字符串,它以BLOB类型存储
MD5() 计算字符串str的MD5校验和
PASSWORD(str) 返回字符串str的加密版本,这个加密过程是不可逆转的,和UNIX密码加密过程使用不同的算法。
SHA() 计算字符串str的安全散列算法(SHA)校验和
示例:
SELECT ENCRYPT(‘root’,’salt’);
SELECT ENCODE(‘xufeng’,’key’);
SELECT DECODE(ENCODE(‘xufeng’,’key’),’key’);#加解密放在一起
SELECT AES_ENCRYPT(‘root’,’key’);
SELECT AES_DECRYPT(AES_ENCRYPT(‘root’,’key’),’key’);
SELECT MD5(‘123456’);
SELECT SHA(‘123456’);
6、控制流函数
MySQL有4个函数是用来进行条件操作的,这些函数可以实现SQL的条件逻辑,允许开发者将一些应用程序业务逻辑转换到数据库后台。
MySQL控制流函数:
CASE WHEN[test1] THEN [result1]…ELSE [default] END如果testN是真,则返回resultN,否则返回default
CASE [test] WHEN[val1] THEN [result]…ELSE [default]END 如果test和valN相等,则返回resultN,否则返回default
IF(test,t,f) 如果test是真,返回t;否则返回f
IFNULL(arg1,arg2) 如果arg1不是空,返回arg1,否则返回arg2
NULLIF(arg1,arg2) 如果arg1=arg2返回NULL;否则返回arg1
这些函数的第一个是IFNULL(),它有两个参数,并且对第一个参数进行判断。如果第一个参数不是NULL,函数就会向调用者返回第一个参数;如果是NULL,将返回第二个参数。
如:SELECT IFNULL(1,2), IFNULL(NULL,10),IFNULL(4*NULL,’false’);
NULLIF()函数将会检验提供的两个参数是否相等,如果相等,则返回NULL,如果不相等,就返回第一个参数。
如:SELECT NULLIF(1,1),NULLIF(‘A’,’B’),NULLIF(2+3,4+1);
和许多脚本语言提供的IF()函数一样,MySQL的IF()函数也可以建立一个简单的条件测试,这个函数有三个参数,第一个是要被判断的表达式,如果表达式为真,IF()将会返回第二个参数,如果为假,IF()将会返回第三个参数。
如:SELECTIF(1<10,2,3),IF(56>100,’true’,’false’);
IF()函数在只有两种可能结果时才适合使用。然而,在现实世界中,我们可能发现在条件测试中会需要多个分支。在这种情况下,MySQL提供了CASE函数,它和PHP及Perl语言的switch-case条件例程一样。
CASE函数的格式有些复杂,通常如下所示:
CASE [expression to be evaluated]
WHEN [val 1] THEN [result 1]
WHEN [val 2] THEN [result 2]
WHEN [val 3] THEN [result 3]
……
WHEN [val n] THEN [result n]
ELSE [default result]
END
这里,第一个参数是要被判断的值或表达式,接下来的是一系列的WHEN-THEN块,每一块的第一个参数指定要比较的值,如果为真,就返回结果。所有的WHEN-THEN块将以ELSE块结束,当END结束了所有外部的CASE块时,如果前面的每一个块都不匹配就会返回ELSE块指定的默认结果。如果没有指定ELSE块,而且所有的WHEN-THEN比较都不是真,MySQL将会返回NULL。
CASE函数还有另外一种句法,有时使用起来非常方便,如下:
CASE
WHEN [conditional test 1] THEN [result 1]
WHEN [conditional test 2] THEN [result 2]
ELSE [default result]
END
这种条件下,返回的结果取决于相应的条件测试是否为真。
示例:
mysql>SELECT CASE ‘green’
WHEN ‘red’ THEN ‘stop’
WHEN ‘green’ THEN ‘go’ END;
SELECT CASE 9 WHEN 1 THEN ‘a’ WHEN 2 THEN ‘b’ ELSE ‘N/A’ END;
SELECT CASE WHEN (2+2)=4 THEN ‘OK’ WHEN(2+2)<>4 THEN ‘not OK’ END ASSTATUS;
SELECT Name,IF((IsActive = 1),’已激活’,’未激活’) AS RESULT FROMUserLoginInfo;
SELECT fname,lname,(math+sci+lit) AS total,
CASE WHEN (math+sci+lit) < 50 THEN ‘D’
WHEN (math+sci+lit) BETWEEN 50 AND 150 THEN ‘C’
WHEN (math+sci+lit) BETWEEN 151 AND 250 THEN ‘B’
ELSE ‘A’ END
AS grade FROM marks;
SELECT IF(ENCRYPT(‘sue’,’ts’)=upass,’allow’,’deny’) AS LoginResultFROM users WHERE uname = ‘sue’;#一个登陆验证
7、格式化函数
DATE_FORMAT(date,fmt) 依照字符串fmt格式化日期date值
FORMAT(x,y) 把x格式化为以逗号隔开的数字序列,y是结果的小数位数
INET_ATON(ip) 返回IP地址的数字表示
INET_NTOA(num) 返回数字所代表的IP地址
TIME_FORMAT(time,fmt) 依照字符串fmt格式化时间time值
其中最简单的是FORMAT()函数,它可以把大的数值格式化为以逗号间隔的易读的序列。
示例:
SELECT FORMAT(34234.34323432,3);
SELECT DATE_FORMAT(NOW(),’%W,%D %M %Y %r’);
SELECT DATE_FORMAT(NOW(),’%Y-%m-%d’);
SELECT DATE_FORMAT(19990330,’%Y-%m-%d’);
SELECT DATE_FORMAT(NOW(),’%h:%i %p’);
SELECT INET_ATON(‘10.122.89.47’);
SELECT INET_NTOA(175790383);
8、类型转化函数
为了进行数据类型转化,MySQL提供了CAST()函数,它可以把一个值转化为指定的数据类型。类型有:BINARY,CHAR,DATE,TIME,DATETIME,SIGNED,UNSIGNED
示例:
SELECT CAST(NOW() AS SIGNED INTEGER),CURDATE()+0;
SELECT ‘f’=BINARY ‘F’,’f’=CAST(‘F’ AS BINARY);
9、系统信息函数
DATABASE() 返回当前数据库名
BENCHMARK(count,expr) 将表达式expr重复运行count次
CONNECTION_ID() 返回当前客户的连接ID
FOUND_ROWS() 返回最后一个SELECT查询进行检索的总行数
USER()或SYSTEM_USER() 返回当前登陆用户名
VERSION() 返回MySQL服务器的版本
示例:
SELECT DATABASE(),VERSION(),USER();
SELECTBENCHMARK(9999999,LOG(RAND()*PI()));#该例中,MySQL计算LOG(RAND()*PI())表达式9999999次。
四、
1、通过字符串函数取出后缀
right (email ,length(email)-position(‘@’ in email))
2、按周进行查询:
Select sum(num),week(dt) as wk from jiaban group by wk;
3、加密函数md5;
如果mysql函数和php函数都实现某个功能,先使用哪个?
①mysql函数会影响查询速度的,应该在建表时通过合理的表结构减少函数的使用,比如email,按@前后拆分。
②如果确实要用函数,比如时间的格式化,在mysql里用date_format,在php;里可以用date实现,优先放在业务逻辑层,即php层处理。
③在查询时使用了函数,最大一个坏处会导致某列无法使用索引,以date_format(A),则A列的索引将无法使用。
如果你针对某列查询,而此列用上了函数来判断,则此列将不再使用索引。
例如: select name ,email from table where right(position(email))=’qq.com’
email列是有索引的,可以加快查询速度的,但是因为使用的并不是email列,而是函数处理后的email的返回值。
所以,email列的查询就非常缓慢了。
总结:where条件中,对某列使用了函数,所以此列的索引不发挥作用。
4、View视图的学习:
视图view可以看作一张虚拟的表,是通过某种运算得到的一个投影。创建视图时我们不需要指定视图的列名,与类型。视图只是表的某种查询的投影,所以主要步骤在于查询表上,查询的结果命名为视图就可以了。
5、创建视图的语法:
create view as select 语句
6、视图有什么用?
①可以简化我们的查询;比如,在进行复杂的统计时,先用视图生成一个中间结果,再查询视图。②更精细的权限控制。比如2个网站合作,一方向另一方开放用户表的查询权限,用view可以开放你想让对方获取到的字段信息。③数据多,分表时可以用到。(方便分表查询)比如,小说站,article表,1000多万篇。分成article1,article2,article3…article5,这五张表,每张表放200万条,查询小说时,不知在哪张表。
create view as article select title from article1 union article2 union article3 union article4 union article5;
7、表与视图,数据变化时的相互影响问题。
表数据变化,会影响的视图的变化。
视图某种情况下也可以修改的。要求:视图的数据和表的数据一一对应,就像函数的映射
表->推出视图对应的数据
视图->推出表对应的数据
视图的定义一直存在的,它不会占用空间。
8、删除视图和删表一样:drop view 视图名
order by limit 得到的结果与表不是一 一对应关系的。
一 一对应是指根据select关系,从表中取出的行,只能计算出视图中确定的一行,反之,视图中任意一行,能够反推出表中确定的一行。
9、视图的algorithm
algorithm=merge/temptable/undefined
(1)merge 当引用视图时,引用视图的语句与定义视图的语句合并。
(2)temptable 当引用视图时,根据视图的创建语句建立一个临时表
(3)undefined 未定义,自动,让系统帮我们选。
create algorithm=merge/temptable/undefined view g as select 语句
10、merge意味着视图只是一个语法规则,当查询视图时,把查询视图的语句(比如where那些)与创建时的语句where子句等合并,分析,形成一条select语句。
例如:创建视图的语句
create view g as select goods_id,cat_id,goods_name,shop_price from goods where shop_price >200;
11、查询视图的语句:select * from g where shop_price <3000;
最终执行的语句:select goods_id,cat_id,goods_name,shop_price from goods where shop_price >200 and shop_price <3000;
12、为什么会出现乱码?
①编码和解码不一致(可以修复)②转码过程中字节丢失了(不可以修复)。
(1)告诉客户端使用gbk。set character_set_client=gbk;(2)再告诉连接器使用utf8。set character_set_connection=utf8k;(3)再告诉返回值,请返回GBK的结果。set character_set_results=gbk;
13、牵涉到数据库,想不出现乱码。
(1)正确指定客户端的编码;(2)合理选择连接器的编码;(3)正确指定返回值的编码。(网页本身的编码,meta信息,client/connection/results的指定)
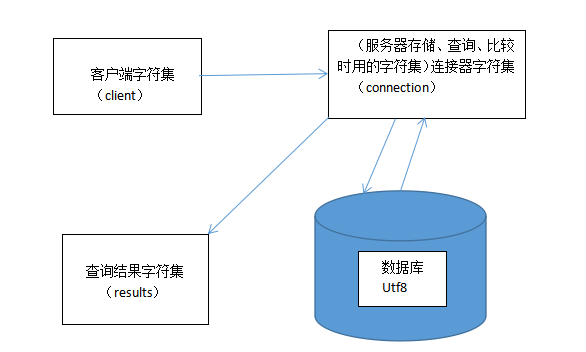
服务器>=connection>=client
results、connection、client都是gbk时可以简写为set names gbk;
Engine引擎就是mysql存储数据的不同方式。
14、事务:原子性,隔离性,持久性,一致性。
原子性:一步,2步或者n步要么都成功,要么都失败。比如转账问题。
(1)start transaction 开启事务
(2)commit 提交事务
(3)rollback 回滚
隔离性:事务结束前,每一步的操作带来的影响,别人看不见。
持久性:事务一旦完成,无法撤销。
一致性:指的是逻辑上的一致性,即所有操作是符合现实当中的期望的。事务结束前后保持一致。比如转账前A和B一共有5000元,不管A和B之间进行多少次转账转多少钱,事务结束后·,他们一共还是5000元。




























还没有评论,来说两句吧...