【ElasticSearch】搜索结果处理:排序、分页、高亮
文章目录
- 1、排序
- 2、分页
- 3、高亮
1、排序
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
# 数值、keyword、日期等类型排序的语法GET /indexName/_search{"query": {"match_all": {}},"sort": [{"FIELD": "desc" // 排序字段和排序方式ASC、DESC}]}
地理类型坐标排序的语法:
GET /indexName/_search{"query": {"match_all": {}},"sort": [{"_geo_distance" : {"FIELD" : "纬度,经度", //经纬度位置字段FIELD,你的位置"纬度、经度""order" : "asc","unit" : "km" //最后显示为哪个单位,距离你5KM}}]}
案例一:对酒店数据按照用户评价降序排序,评价相同的按照价格升序排序
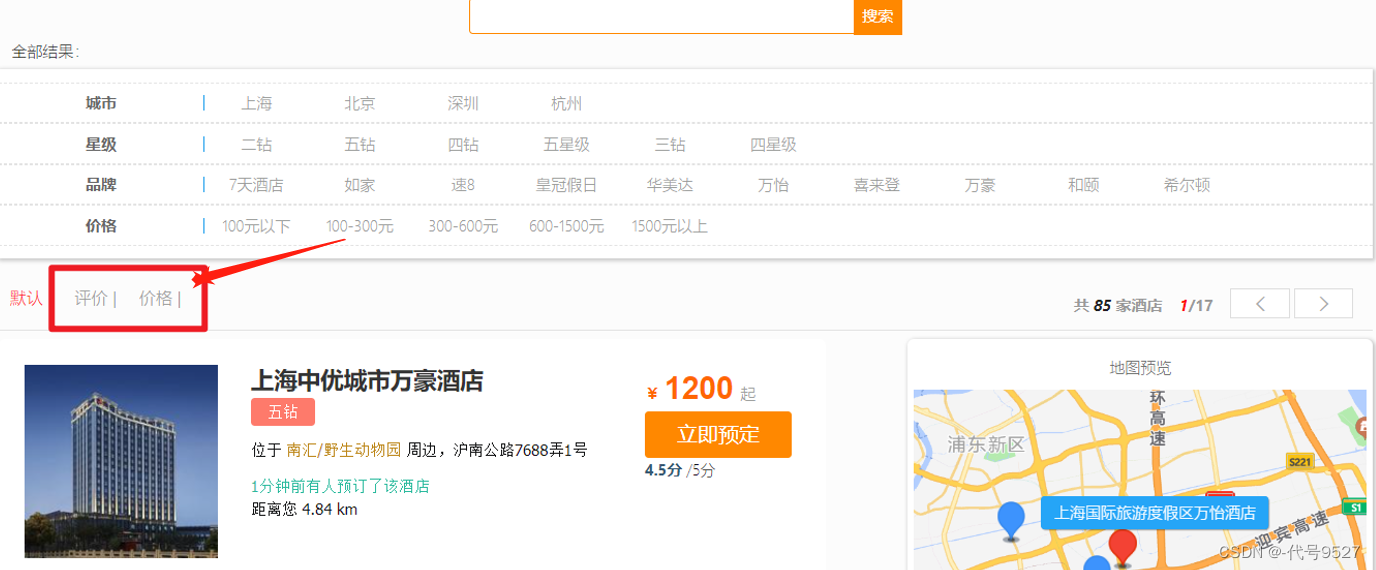
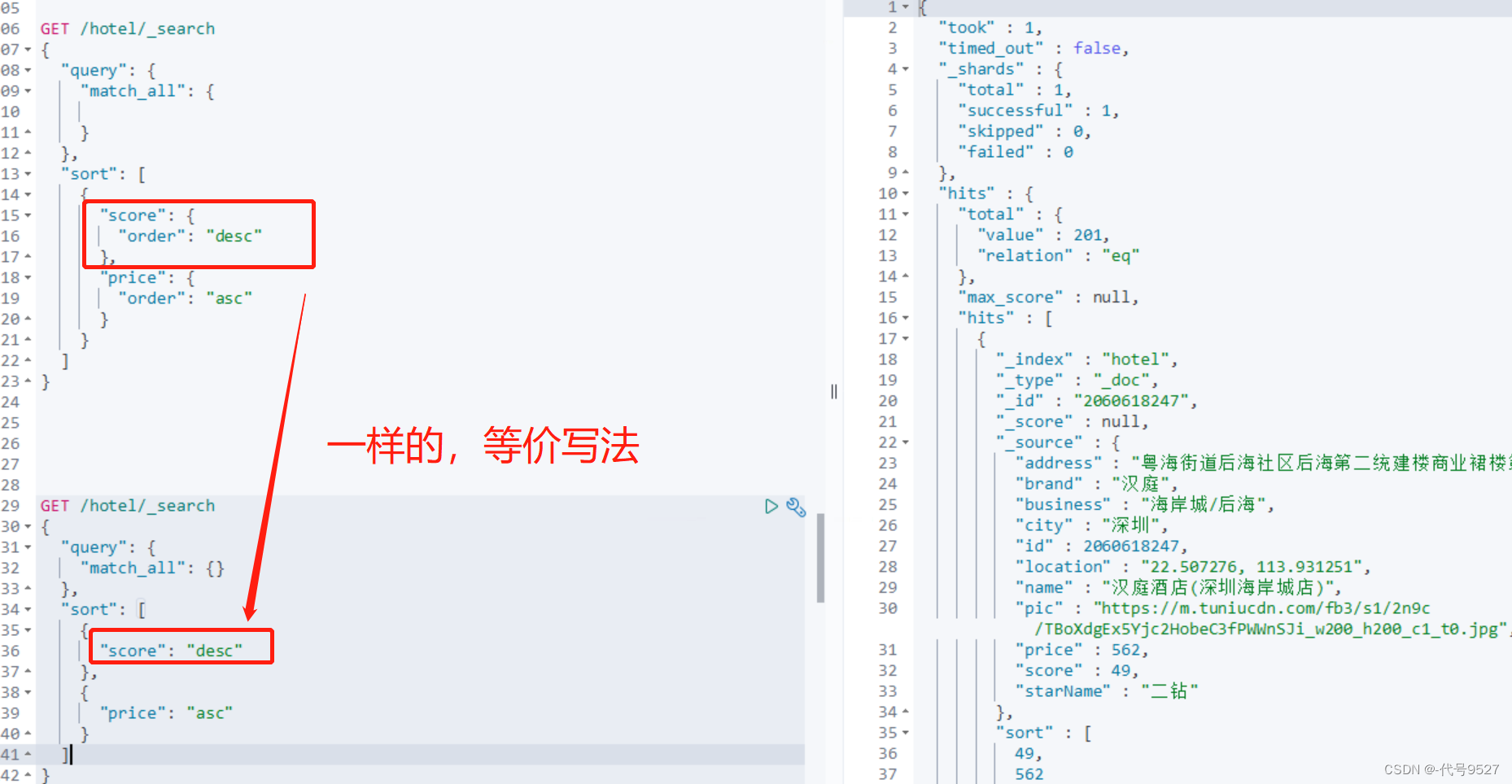
GET /hotel/_search{"query": {"match_all": {}},"sort": [{"score": "desc"},{"price": "asc"}]}
案例二:实现对酒店数据按照到你的位置坐标的距离升序排序
获取经纬度的方式:https://lbs.amap.com/demo/jsapi-v2/example/map/click-to-get-lnglat/
这个案例在实际场景中即是:
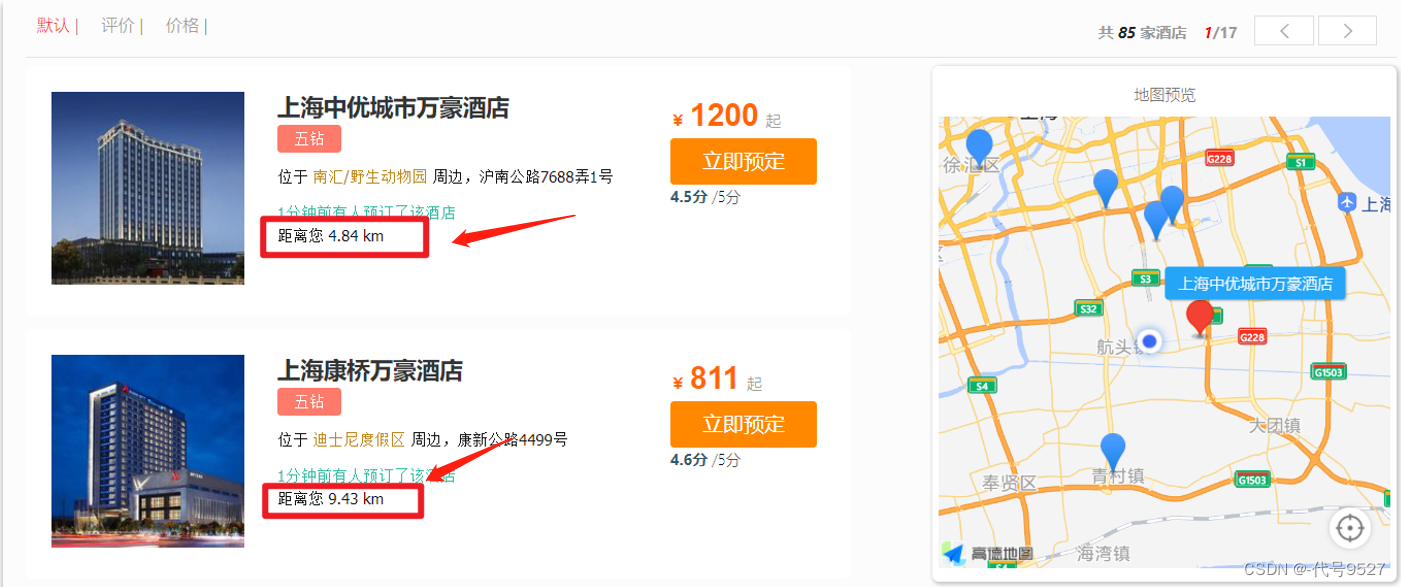
GET /hotel/_search{"query": {"match_all": {}},"sort": [{"_geo_distance" : {"location" : "31.0,121.6","order" : "asc","unit" : "km"}}]}
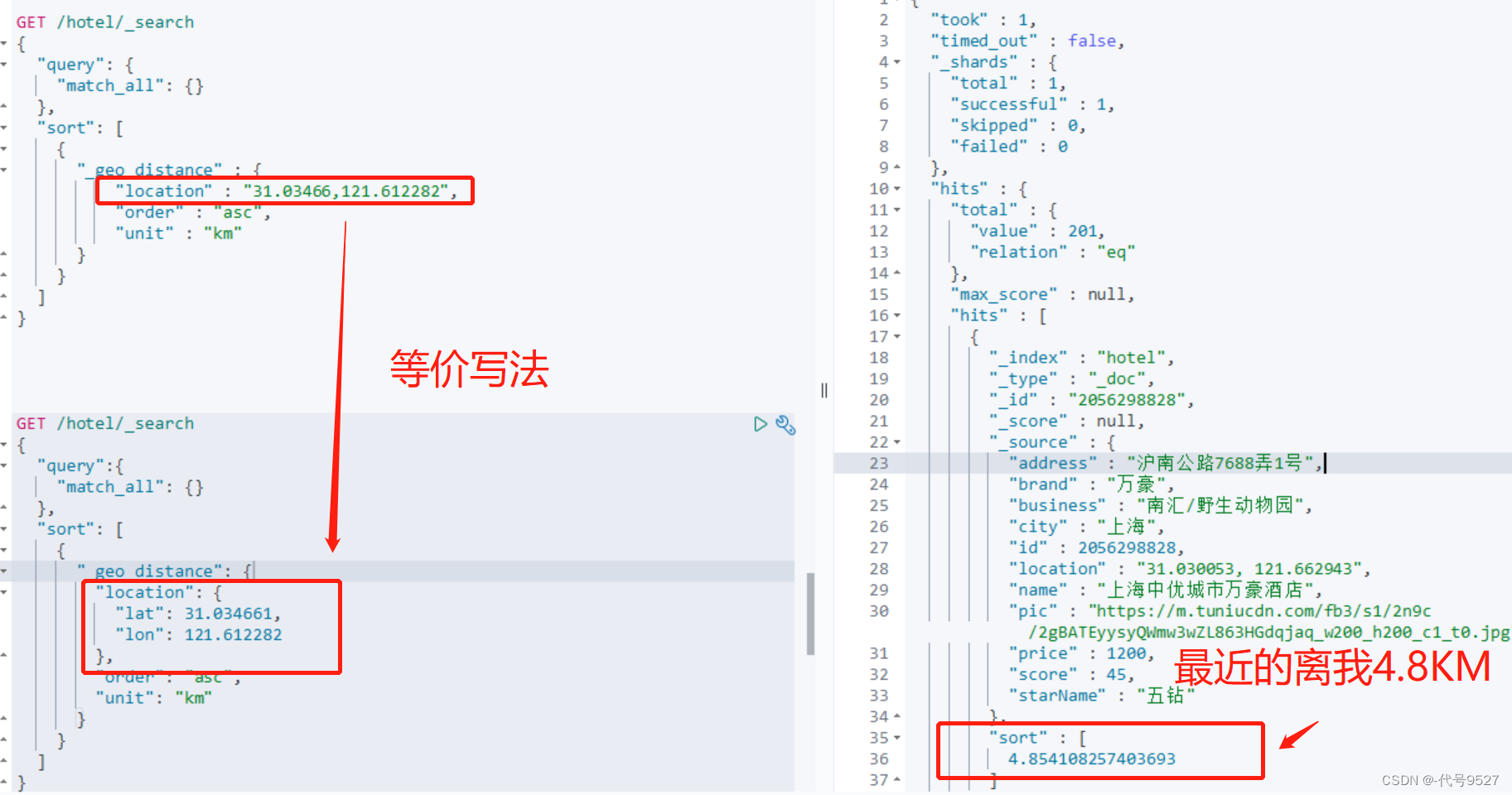
以上两个案例中,指定排序字段后,可以看到返回结果中_score为null,即指定排序字段,ES就不用打分了,这样对查询性能也有一定提升。
2、分页
ES底层有默认的分页参数,因此默认情况下只返回top10的数据,可通过修改from、size参数来控制要返回的分页结果:
{"query": {"match_all": {}},"from": 990, // 分页开始的位置,默认为0"size": 10, // 期望获取的文档总数"sort": [{"price": "asc"}]}//有点像MySQL的LIMIT,第一个参数从哪儿开始,第二参数为行数
举例:

比如from值为990,size为10,不同于MySQL的正排索引,ES的倒排索引只能先查出前1000条,再截取990-1000条的文档:
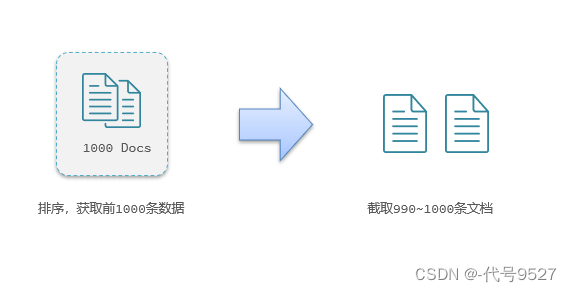
这一点在分布式的ES集群中,就产生了深度分页问题。
例如按price排序后,获取from = 990,size =10的数据:
- 首先在每个数据分片上都排序并查询前1000条文档
- 然后将所有节点的
结果聚合,在内存中重新排序选出前1000条文档 - 最后从这1000条中,选取从990开始的10条文档
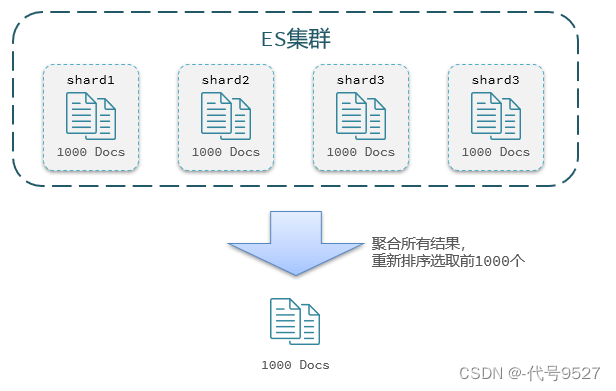
此时,如果搜索页数过深,或者结果集(from + size)越大,对内存和CPU的消耗也越高。因此ES设定结果集查询的上限是10000

如果真有这个超10000的需求,ES官方提供两种解决方案:
search after:
分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式
scroll:
原理将排序数据形成快照,保存在内存。官方已经不推荐使用
小结:

3、高亮
即在搜索结果中把搜索关键字突出显示,实现原理是:
- 将搜索结果中的关键字用标签标记出来
在页面中给这个标签添加css样式,如color:red
GET /hotel/_search
{“query”: {
"match": {"FIELD": "TEXT" //这自然不能用match_all了,不然关键字都没了,何谈高亮}
},
“highlight”: {"fields": {// 指定要高亮的字段"FIELD": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}
}
}
F12看下:
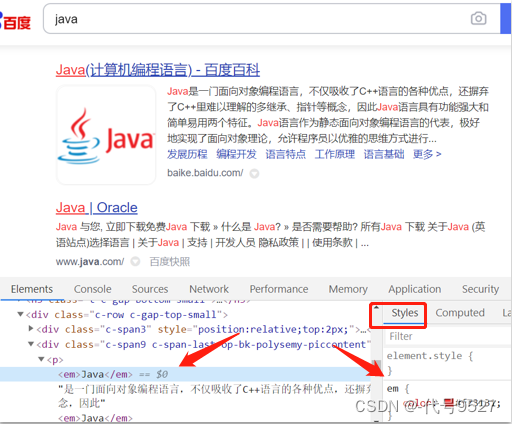
举例:
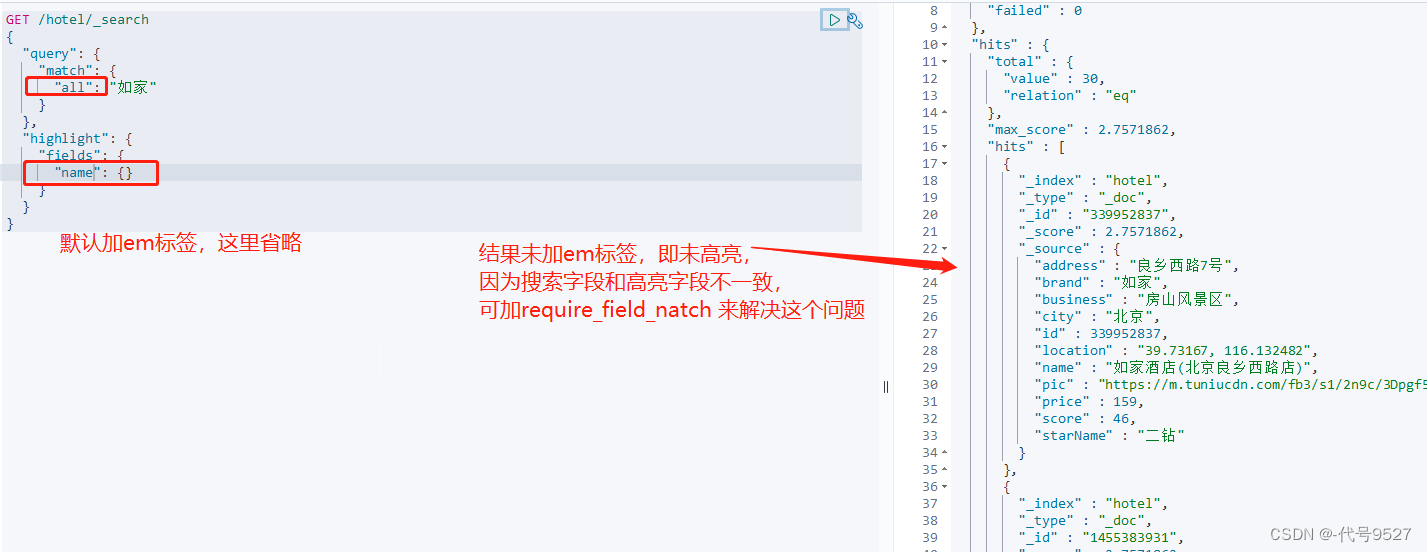
改require_field_match为false:
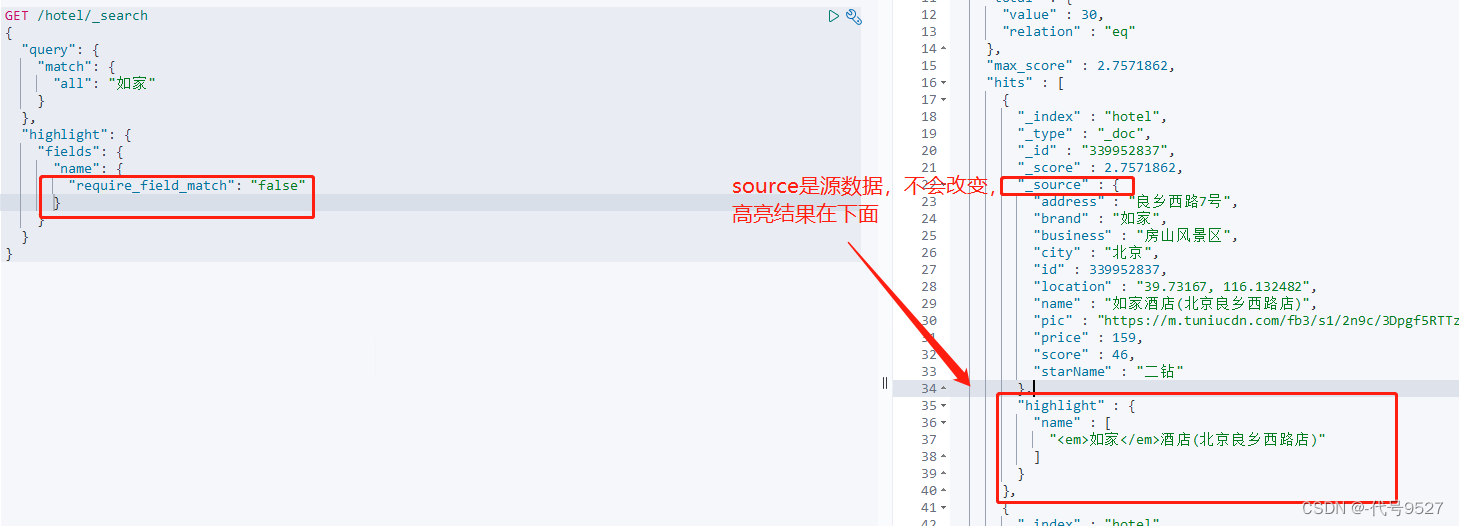
到此,搜索基本结束,综合起来如下:
GET /hotel/_search{"query": {"match": {"name": "如家"}},"from": 0, // 分页开始的位置"size": 20, // 期望获取的文档总数"sort": [{"price": "asc" }, // 普通排序{"_geo_distance" : {// 距离排序"location" : "31.040699,121.618075","order" : "asc","unit" : "km"}}],"highlight": {"fields": {// 高亮字段"name": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}}


































还没有评论,来说两句吧...