Solr+java实现索引库增删改查
1 了解solr的配置文件
1.1 solr的核心配置文件:solrConfig.xml
solrconfig.xml 配置文件主要定义了 solr 的一些处理规则,包括索引数据的存放 位置,更新,删除,查询的一些规则配置。 一般此文件不需要进行修改, 采取默认即可。
(1) field标签
主要是用来指定字段名称的, Lucene中是有用户在程序中指定, solr中需要提前在配置文件中指定
<field name="text" type="text_general" indexed="true" stored="false" multiValued="true"/>
name: 字段的名称
type: 字段的类型
indexed: 是否索引
stored: 是否保存
multiValued: 是否多值, 这个字段, 类似存储一个数组
这里有两个不允许删除的: 一个是 version_ 一个是 root_ 这两个是solr内部需要使用的字段
有一个字段的名称必须为id,其类型都不允许进行修改 原因是id字段已经被主键使用uniqueKey
其余的是一些初始化好的字段
(2)dynamicField标签 ,被称为是动态字段
<dynamicField name="*_is" type="int" indexed="true" stored="true" multiValued="true"/>
此种标签是为程序的扩展所使用的, 因为我们不可能把所有的字段全部定义好, 所以就需要动态域来进行动态扩展。
(3)uniqueKey标签
必要标签, 表名文档的唯一属性, 一般默认为id
<uniqueKey>id</uniqueKey>

(4)copyField标签
<copyField source="cat" dest="text"/><copyField source="dog" dest="text"/>
source: 表名要复制那个字段的值
dest: 复制到那个字段上
此种标签主要是为了查询所使用的, 例如, 当查询Text字段的时候, 实质上相当于查询title和name两个字段
(5)fieldType标签
字段类型定义标签,此种标签是用来定义字段的类型的,可以指定此字段使用何种分词器进行分词。
<fieldType name="text_ik" class="solr.TextField"><analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/></fieldType>

1.2 solrConfig.xml 模板
<?xml version="1.0" encoding="UTF-8" ?><schema name="example" version="1.5"><!-- 这个标签不能删除--><field name="_version_" type="long" indexed="true" stored="true"/><field name="_root_" type="string" indexed="true" stored="false"/><!--不能删除--><!--field: 指定solr的默认字段的, lucene中字段手动的定义,solr中提前定义好name : 字段的名称type : 字段的类型indexed : 是否索引(是否分词)stored : 是否保存required : 是否是必须的multiValued : 是否是多值(当前这个字段的类似是数组)id字段: id字段是文档的唯一标识, lucene中, 文档的唯一字段由lucene自己进行维护solr中, id字段需要由程序员自己进行维护, 保证id唯一, 如果不唯一, 就会将原有的数据给覆盖掉--><field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /><field name="name" type="text_ik" indexed="true" stored="true"/><field name="title" type="text_ik" indexed="true" stored="true" multiValued="false"/><field name="url" type="string" indexed="true" stored="true"/><field name="content" type="text_ik" indexed="true" stored="true" multiValued="false"/><field name="time" type="date" indexed="true" stored="true" multiValued="false"/><field name="text" type="text_ik" indexed="true" stored="false" multiValued="true"/><!--dynamicField: 动态(域)字段 , 动态域只要的目的是为了扩展新的字段而产生的--><dynamicField name="*_i" type="text_ik" indexed="true" stored="true"/><dynamicField name="*_is" type="text_ik" indexed="true" stored="true" multiValued="true"/><!--uniqueKey: 指定文档的唯一字段是那个: 默认是id,建议使用id一旦这个字段被定义成了唯一字段, 那么这个字段必须是required=true--><uniqueKey>id</uniqueKey><!--copyField : 复制域(字段) , 复制域主要是用来做查询会将多个字段的数据, 复制到某一个字段上, 当用户进行查询的时候, 如果查询的复制域的字段,那么就相当于查询了多个字段source: 来源(从哪里来)dest : 目的(到哪里去)复制域必须是一个多值的字段--><copyField source="title" dest="text"/><copyField source="name" dest="text"/><!--fieldType: 字段的类型: 定义这个类型使用哪种分词器, 使用哪种格式--><fieldType name="string" class="solr.StrField" sortMissingLast="true" /><fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/><fieldType name="int" class="solr.TrieIntField" precisionStep="0" positionIncrementGap="0"/><fieldType name="float" class="solr.TrieFloatField" precisionStep="0" positionIncrementGap="0"/><fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/><fieldType name="double" class="solr.TrieDoubleField" precisionStep="0" positionIncrementGap="0"/><fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/><!--配置ik分词器--><fieldType name="text_ik" class="solr.TextField"><analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/></fieldType></schema>
2 引入ik分词器
2.1 导入ik相关的依赖包
放置在tomcat>webapps>solr>WEB-INF>lib下
导入ik相关的配置文件(ik配置文件, 扩展词典和停止词典)
将三个文件放置在tomcat>webapps>solr>WEB-INF>classes下
https://blog.csdn.net/weixin\_44784673/article/details/101168148
2.2 修改schema.xml配置文件
<fieldType name="text_ik" class="solr.TextField"><analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/></fieldType>
2.3 为对应的字段设置为text_ik类型
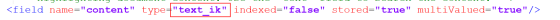
3 Idea操作solr
3.1 导入相关的jar包
<dependency><groupId>org.apache.solr</groupId><artifactId>solr-solrj</artifactId><version>4.10.2</version></dependency><!--日志的包, solrj执行需要一个日志包--><dependency><groupId>commons-logging</groupId><artifactId>commons-logging-api</artifactId><version>1.1</version></dependency>
3.2 写入/修改索引库(字段名必须存在在schema.xml配置文件中)
有三种方式
//方式一:原生方式@Testpublic void InputSorl1() throws Exception{//1. 创建solr的服务对象(发送请求, 获取数据)SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr/collection1");//2. 添加索引/*name的字段名必须存在,配置在schema.xml*/List<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();SolrInputDocument doc = new SolrInputDocument();doc.addField("id","2");doc.addField("title","双十一来了");doc.addField("content","又到了卖肾的季节了");docs.add(doc);SolrInputDocument doc1 = new SolrInputDocument();doc1.addField("id","3");doc1.addField("title","剁手节来了");doc1.addField("content","今天你剁手了吗?");docs.add(doc1);solrServer.add(docs);//3. 提交数据solrServer.commit();}//方式二:一次写入多条索引@Testpublic void InputSorl2() throws Exception {//1. 创建solrServer对象SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr/collection1");//2.1 设置多条数据List<SolrInputDocument> docs = new ArrayList<>();for(int i=0 ; i<10 ; i++){//2.1.1 创建一个documentSolrInputDocument document = new SolrInputDocument();document.addField("id",i);document.addField("content","solr是一个独立的企业级搜索应用服务器, 可以通过http请求访问这个服务器, 获取或者写入对应的内容, 其底层是Lucene "+i);document.addField("title","solr的简介");//2.1.2 将document添加到集合中docs.add(document);}//2. 写入索引solrServer.add(docs);//3. 提交索引solrServer.commit();}//方式三:使用javaBean来添加索引数据@Testpublic void InputSorl3() throws Exception {//1. 创建 solr的服务对象SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr/collection1");//2. 添加文档数据News news = new News("3","Ella老公被曝呛声片场工作人员:我有的是钱","就怕因此拍摄不顺或当机,赖斯翔虽听从规劝,却也反呛","http://ent.163.com/18/1107/10/E00KM09000038FO9.html");solrServer.addBean(news);// 使用addBeans来添加多条数据//3. 提交数据solrServer.commit();}
3.3 删除索引库
@Testpublic void delIndex() throws Exception {//1. 创建 solr的服务对象SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr/collection1");//2. 执行删除//solrServer.deleteByQuery("*:*"); //删除全部的数据solrServer.deleteById("1");//3. 提交数据solrServer.commit();}
3.4 查询索引库
1. 基本查询
//查询全部@Testpublic void indexSearcherSolrTest01() throws Exception {//1. 创建 solrServer对象SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr/collection1");//2. 执行查询//SolrQuery : solr的查询对象SolrQuery solrQuery = new SolrQuery("*:*");QueryResponse response = solrServer.query(solrQuery);//3. 获取数据SolrDocumentList documentList = response.getResults();for (SolrDocument document : documentList) {String id = (String) document.get("id");String title = (String) document.get("title");String content = (String) document.get("content");String url = (String) document.get("url");System.out.println("id "+id+" title"+title+" content"+content+" url"+url);}}//查询对象@Testpublic void indexSearcherSolrTest02() throws Exception {//1. 创建 solrServer对象SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr/collection1");//2. 执行查询//SolrQuery : solr的查询对象SolrQuery solrQuery = new SolrQuery("*:*");QueryResponse response = solrServer.query(solrQuery);//3. 获取数据 : 此处有可能会出现转换类型异常的错误:List<News> newsList = response.getBeans(News.class);for (News news : newsList) {System.out.println(news.getId()+" "+news.getTitle());}}
2. 复杂查询
//服务对象public void query(SolrQuery query) throws Exception{//创建SolrServer服务对象SolrServer server = new HttpSolrServer("http://localhost:8080/solr/collection1");//创建Solr的查询对象QueryResponse response = server.query(query);//文档的集合SolrDocumentList documentList = response.getResults();for (SolrDocument document : documentList) {String id = document.get("id").toString();String title = document.get("title").toString();System.out.println("id:"+id+";title:"+title);}}//词条查询@Testpublic void testTerm() throws Exception{/** 字段名:关键字* 在查询时,会对关键字进行分词** */SolrQuery query = new SolrQuery("title:钱");query(query);}//通配符查询@Testpublic void testWildCard() throws Exception{/** *:匹配0到多个字符* ?:匹配1个字符** */SolrQuery query = new SolrQuery("title:selin*");query(query);}//模糊查询@Testpublic void testFuzzy() throws Exception{/** 在关键字之后添加~,表示进行模糊查询** 最大编辑次数:通过新增,修改,删除可以匹配正确的词条的次数,默认为2** ~后的数据,表示最大的编辑次数* */SolrQuery query = new SolrQuery("title:selinaq~1");query(query);}//范围查找查询@Testpublic void testRange() throws Exception{/**** *///SolrQuery query = new SolrQuery("id:[20 TO 50]");SolrQuery query = new SolrQuery("publishTime:{2001-01-01T12:00:00Z TO 2019-01-01T12:00:00Z}");query(query);}//组合@Testpublic void testBoolean() throws Exception{/** AND* OR* NOT** *///SolrQuery query = new SolrQuery("id:[20 TO 50]");SolrQuery query = new SolrQuery(" title:xxx or inrot:xxx");query(query);}
4 solr的高级使用
4.1 solr的排序
@Testpublic void sortTest() throws Exception {SolrQuery solrQuery = new SolrQuery("*:*");solrQuery.setSort("id", SolrQuery.ORDER.asc);publicSearch(solrQuery);}
4.2 solr的分页
@Testpublic void limitTest() throws Exception {int page = 2; //当前页int pageSize = 3 ;// 每页条数SolrQuery solrQuery = new SolrQuery("*:*");// 排序solrQuery.setSort("id", SolrQuery.ORDER.asc);//分页solrQuery.setStart((page-1)*pageSize);solrQuery.setRows(pageSize);publicSearch(solrQuery);}
4.3 solr 的高亮
@Testpublic void highlighterTest() throws Exception {//1. 创建solr的服务对象SolrServer solrServer = new HttpSolrServer("http://localhost:8080/solr/collection1");int page = 1; //当前页int pageSize = 3 ;// 每页条数SolrQuery solrQuery = new SolrQuery("content:lucene");// 排序solrQuery.setSort("id", SolrQuery.ORDER.asc);//分页solrQuery.setStart((page-1)*pageSize);solrQuery.setRows(pageSize);//高亮:solrQuery.setHighlight(true); //开启了高亮solrQuery.addHighlightField("content"); //使用add方法来设置高亮字段, 说明高亮字段可以有多个solrQuery.addHighlightField("title");solrQuery.setHighlightSimplePre("<font color='red'>");solrQuery.setHighlightSimplePost("</font>");//2. 执行查询QueryResponse response = solrServer.query(solrQuery);/*最外层的map:key: 文档的idvalue: 文档的高亮内容内层的map:key: 高亮的字段value: 这个字段的高亮内容list集合: 高亮内容, 而且集合中一般只有一个数据, 除非高亮的字段是一个多值的字段,并且设置高亮的最大分片数大于1*/Map<String, Map<String, List<String>>> map = response.getHighlighting();for (String docId : map.keySet()) {Map<String, List<String>> listMap = map.get(docId);for (String filed : listMap.keySet()) {List<String> list = listMap.get(filed);System.out.println(list.get(0)+" "+list.size());}}}



























jdk7字符串常量池详解")
![[C语言]内存操作的库函数实现及原理解释](https://image.dandelioncloud.cn/images/20221022/c2776a88b59341dda759fca78d99daa8.png "[C语言]内存操作的库函数实现及原理解释")





还没有评论,来说两句吧...