MySQL 我们来聊聊 count(*) 语句的优化方式有哪些?
志在巅峰的攀登者,不会陶醉在沿途的某个脚印之中,在码农的世界里,优美的应用体验,来源于程序员对细节的处理以及自我要求的境界,年轻人也是忙忙碌碌的码农中一员,每天、每周,都会留下一些脚印,就是这些创作的内容,有一种执着,就是不知为什么,如果你迷茫,不妨来瞅瞅码农的轨迹。
- 优美的音乐节奏带你浏览这个效果的编码过程
- 坚持每一天,是每个有理想青年的追求
- 追寻年轻人的脚步,也许你的答案就在这里
- 如果你迷茫 不妨来瞅瞅这里
在实际业务开发中,可能会经常需要计算一个表的行数,于是你可能会使用的查询语句
select count(*) from question_extracting
如下图所示: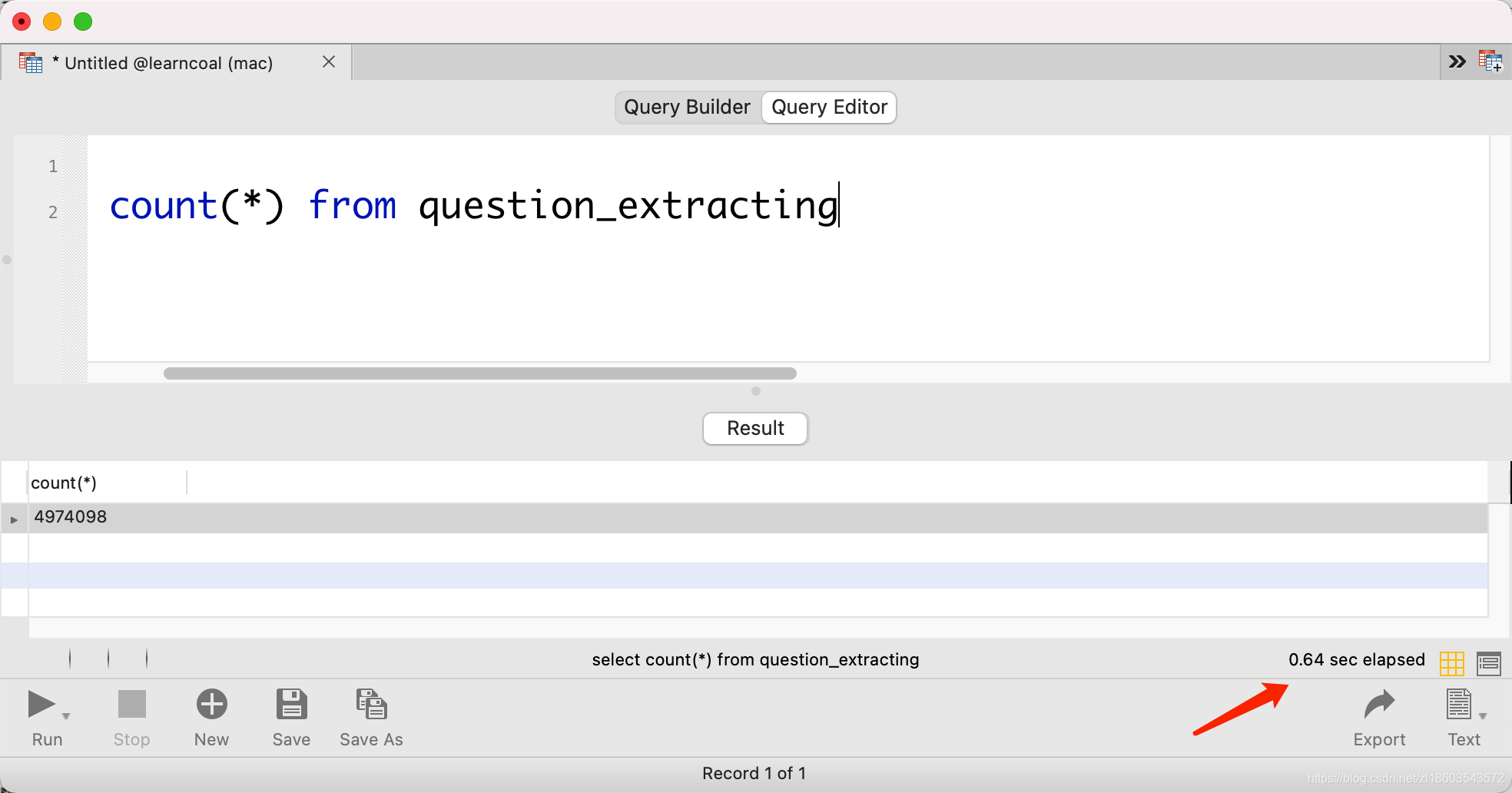
上述查询这个数量尽然花了640 ms ,我们不妨再添加个筛选条件
SELECTcount(*)FROMquestion_extractingWHEREcreate_time BETWEEN '2019-01-05'AND '2019-06-05'
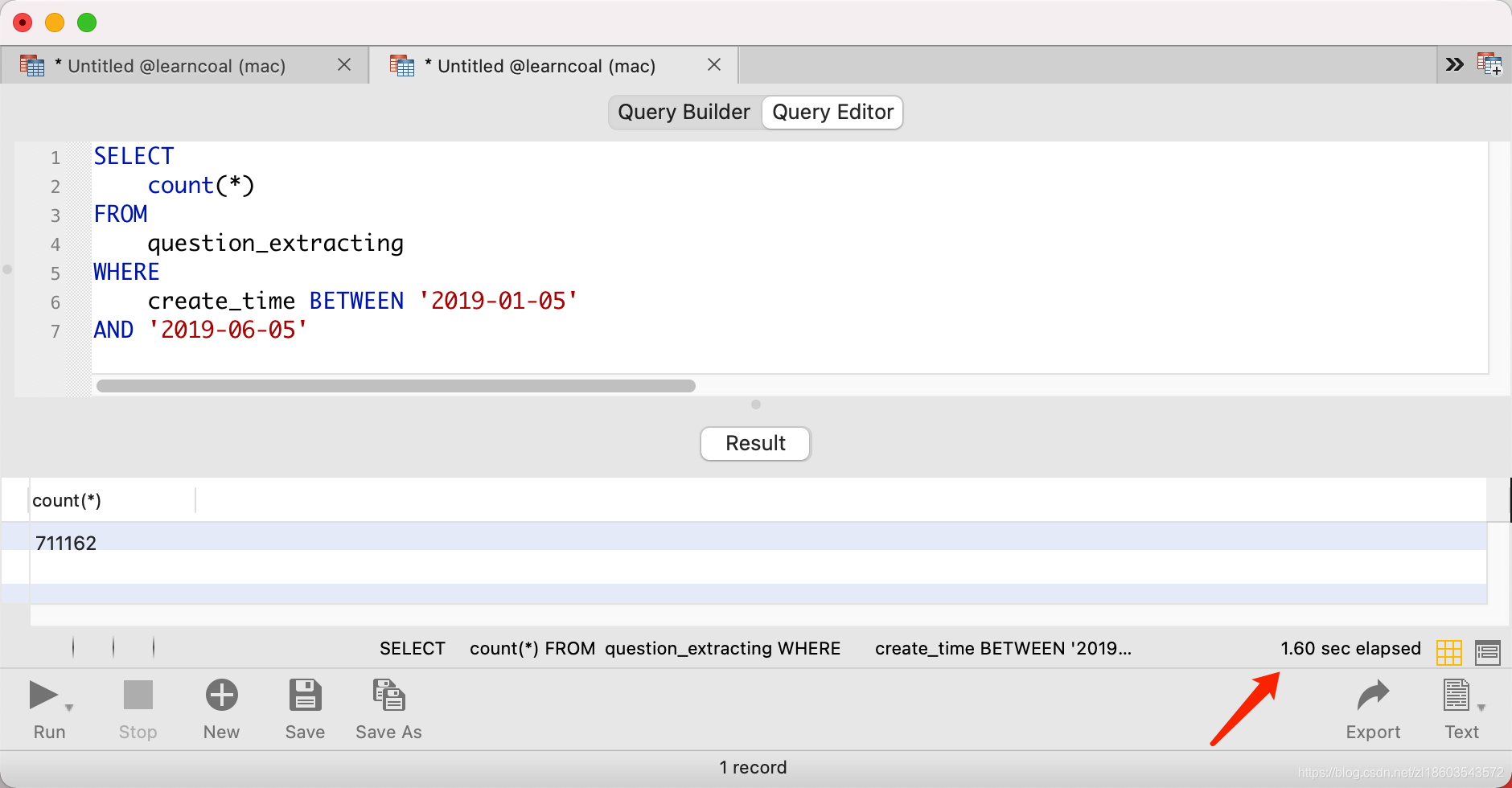 尽然花了1.6 秒,这是不可忍的,你知道发生了什么吗 ?
尽然花了1.6 秒,这是不可忍的,你知道发生了什么吗 ?
1 MySQL count(*) 的实现原理
一句话描述就是 InnoDB 引擎在执行 count(*) 的时候,上把数据一行一行地从引擎里面读出来,然后累积计数。
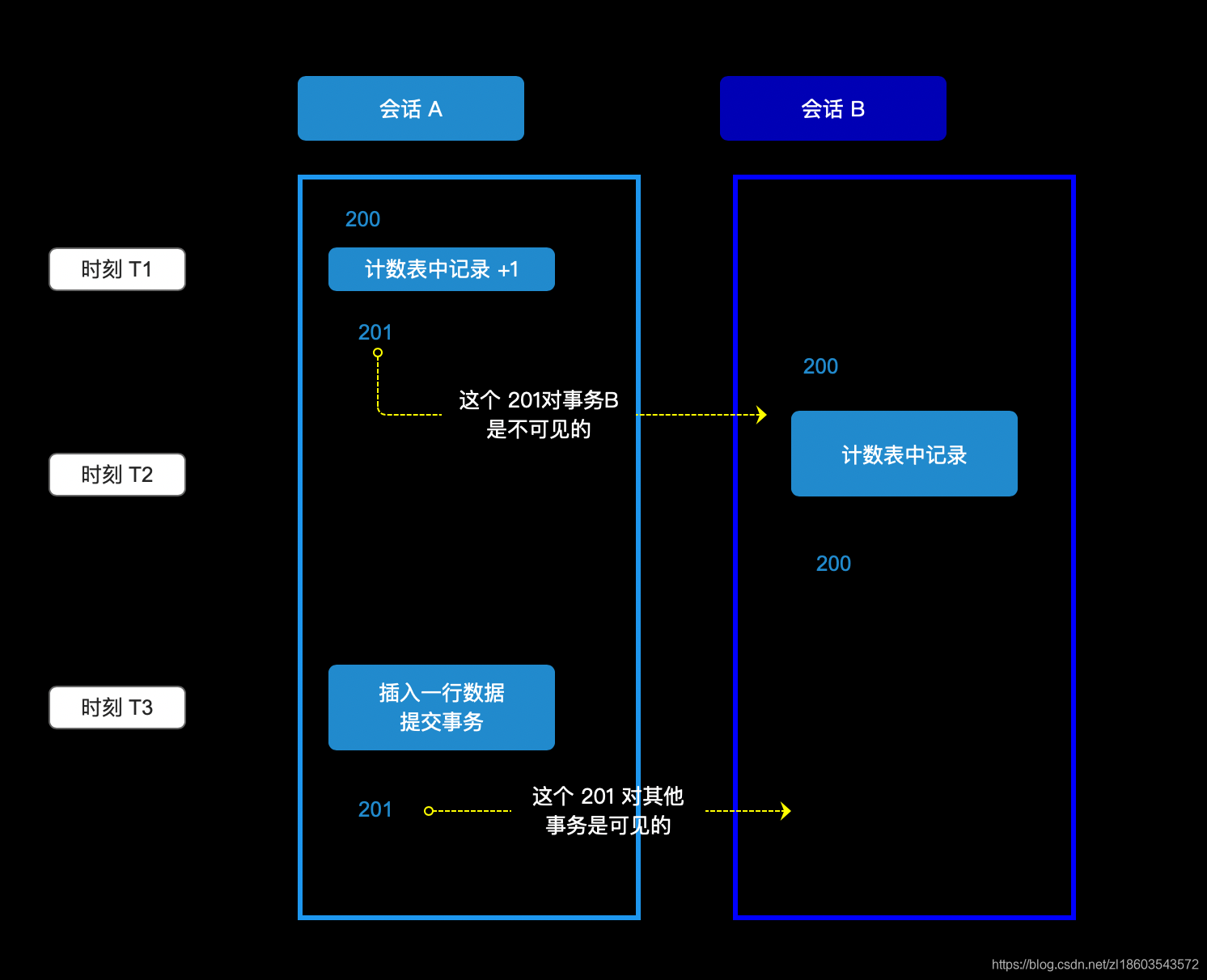
InnoDB 的事务设计中,可重复读是它默认的隔离级别,InnoDB在计算表中记录数据时,每一行记录都要判断这一条记录是否对本次的查询可见,只有可见的行才能够用于计算“基于这个查询”的表的总行数。
所在使用 MySQL count(*) 来查询表的总行数,性能上会有很大的问题。
2 将计数保存在缓存系统中?
Redis 是一个不错的选择,可以用一个 Redis 服务来保存表的总行数,然后表每被插入一行 Redis 计数就加 1,每被删除一行 Redis 计数就减 1。
但是当 Redis 异常重启以后,你的数据就有可能丢失,所以解决方式就是 当 Redis 异常重启以后 ,再到数据库里面单独执行一次 count(*) 获取真实的行数保存。
在并发的情况下,这种缓存的计算方式就极度不精确了,原因是:如查询的是 200行
- 查到的 200 行结果里面有最新插入记录,而 Redis 的计数里还没加 1
- 查到的 200 行结果里没有最新插入的记录,而 Redis 的计数里已经加了 1
3 将计数 数据库保存
用缓存系统保存计数有丢失数据和计数不精确的问题,所以我们可以考虑将计数结果保存在单独的表中,就可以解决计数的问题了。
4 count(主键 id) ?
在 InnoDB 引擎中,我们可以通过 count(*)、count(主键 id)、count(字段) 和 count(1) 等不同的方式来查询计数。
count() 是一个聚合函数,对于返回的结果集,一 行行地判断进行计算。
count(*)、count(主键 id) 和 count(1) 都表示返回满足条件的结果集的总行数。
count(字段),则表示返回满足条件(参数“字段”不为 NULL 的)的数据行的总个数。
4.1 count(主键 id)
InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层,然后在server 层中判断按行累加。
4.2 count(1)
InnoDB 引擎遍历整张表,但不取值,server 层对于返回的每一行, 放一个数字“1”进去,按行累加,所以 count(1) 要比 count(*) 快。
4.3 count(字段)
如果这个“字段”是定义为 not null,那么InnoDB 引擎会一行行地从记录里面读出这个字段,server 层判断不能为 null,按行累加;
如果这个“字段”定义允许为 null,那么InnoDB 引擎会一行行地从记录里面读出这个字段,然后把值取出来再判断一下,不是 null 才累加。
4.4 count(*)
MySQL 对 count(*)进行了优化, count(*)直接扫描主键索引记录,并不会把全部字段取出来,直接按行累加。
按照效率排序的话,count(字段)<count(主键 id)<count(1)≈count(*)
完毕
不局限于思维,不局限语言限制,才是编程的最高境界。
以小编的性格,肯定是要录制一套视频的,随后会上传
有兴趣 你可以关注一下 西瓜视频 — 早起的年轻人



























及SPRO的使用技巧")







还没有评论,来说两句吧...