机器学习的特征归一化Normalization
文章目录
- 为什么需要做归一化?
- 两种常用的归一化方法
- 批归⼀化(Batch Normalization)
- 局部响应归⼀化
- 批归⼀化(Batch Normalization)
- 批归一化的适用场景及优点
为什么需要做归一化?
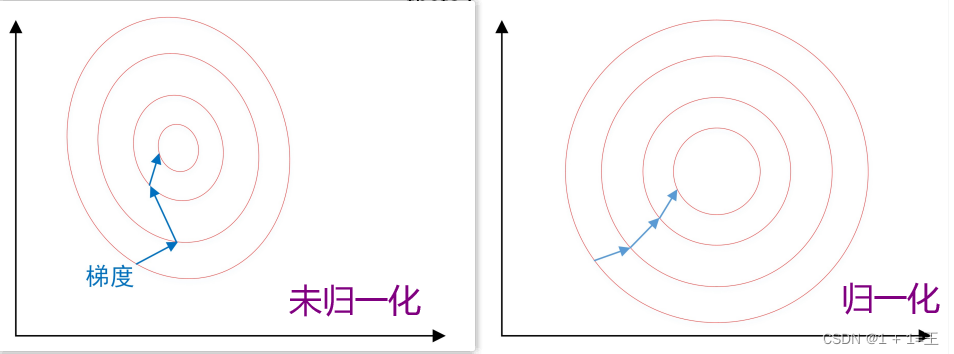
为了消除数据特征之间的量纲影响,就需要对特征进行归一化处理,使得不同指标之间具有可比性。对特征归一化可以将所有特征都统一到一个大致相同的数值区间内。
- 为了后⾯数据处理的⽅便,归⼀化可以避免⼀些不必要的数值问题。
- 为了程序运⾏时收敛加快。
- 统一量纲。
- 保证输出数据中数值⼩的不被吞⾷。
- 避免神经元饱和。
两种常用的归一化方法
- 线性归⼀化(最大最小归一化,Min-Max Scaling)
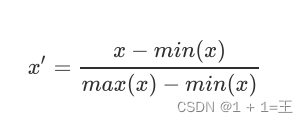
- 标准差标准化(零均值归一化,Z-Score Scaling)
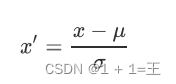
经过处理的数据符合标准正态分布,即均值为 0,标准差为 1。
批归⼀化(Batch Normalization)
局部响应归⼀化
局部响应归⼀化(Local Response Normalization ,LRN)是AlexNet中首次引入的归一化方法。
使用LRN的原因是为了鼓励横向抑制。
横向抑制:这是神经生物学中的一个概念,是指神经元减少其邻居活动的能力。在深度神经网络中,这种横向抑制的目的是进行局部对比度增强,以便使局部最大像素值用作下一层的激励。
批归⼀化(Batch Normalization)
以前在神经⽹络训练中,只是对输⼊层数据进⾏归⼀化处理,却没有在中间层进⾏归⼀化处理。要知道,虽然我们对输⼊数据进⾏了归⼀化处理,但是输⼊数据运算之后,其数据分布很可能被改变,⽽随着深度⽹络的多层运算之后,数据分布的变化将越来越⼤。
这种在神经⽹络中间层也进行归⼀化处理,使训练效果更好的方法,就是批归⼀化。
批归一化的算法流程:
输⼊:上⼀层输出结果X = {x1, x2, …, xm}
- 计算上⼀层输出数据的均值:
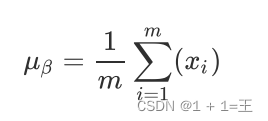
- 计算上⼀层输出数据的标准差
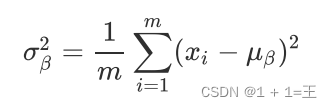
- 归一化
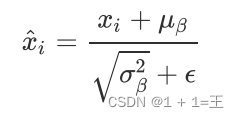
- 重构
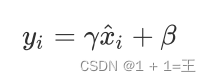 γ和β为可学习的参数。
γ和β为可学习的参数。
批归一化的适用场景及优点
在CNN中,批归一化应作⽤在⾮线性映射前。在神经⽹络训练时遇到收敛速度很慢,或梯度爆炸等⽆法训练的状况时可以尝试BN来解决。
当BatchSize比较大,数据分布比较接近,并在训练前对数据充分shuffle。
批归一化不适⽤于动态的⽹络结构和RNN⽹络。
使用批归一化具有以下优点:
- 减少了人为选择参数。
- 减少了对学习率的要求。
- 破坏原来的数据分布,⼀定程度上缓解过拟合。
- 减少梯度消失,加快收敛速度,提⾼训练精度。




























还没有评论,来说两句吧...