Java通过HttpClient从外部url下载文件到本地
目标
1.将外网文件通过url转化成本地文件
如百度logo图片,右键复制图片链接https://www.baidu.com/img/flexible/logo/pc/result.png
通过代码将图片下载到本地
2.解决图片防盗链问题

防盗链如上图展示,那什么是盗链,什么是防盗链?
盗链
盗链是指在自己的网站页面上展示一些并不在自己服务器上的内容。
大白话就是自己的网站上的资源,如图片,视频等链接在别人的网址中出现,则流量和服务器压力都是走的我们自己的电脑,造成服务器压力和流量流失。
防盗链
防止别人通过一些技术手段绕过本站的资源展示页面,盗用本站的资源,让从非本站资源展示页面的资源链接失效,保证流量没必要流失。
大白话就是通过Referer或者签名来保证访问的资源都是统一站点,保证来源一致。
上代码
package com.haier.healthroom.kefu.utils;import org.apache.commons.lang3.StringUtils;import org.apache.http.*;import org.apache.http.client.HttpClient;import org.apache.http.client.methods.HttpGet;import org.apache.http.impl.client.HttpClients;import java.io.File;import java.io.FileOutputStream;import java.io.InputStream;import java.util.HashMap;import java.util.Map;import java.util.regex.Matcher;import java.util.regex.Pattern;/*** 一个低端小气没档次的程序狗 JavaDog* blog.javadog.net** @BelongsProject: healthroom* @BelongsPackage: com.haier.healthroom.kefu.utils* @Author: hdx* @CreateTime: 2021-06-04 10:10* @Description: HttpDownload*/public class HttpDownloadUtil {public static final int cache = 10 * 1024;public static void main(String[] args) {String url = "https://www.baidu.com/img/flexible/logo/pc/result.png";String targetUrl = "E:\\demo\\";HttpDownloadUtil.download(url,targetUrl);}/*** 根据url下载文件,保存到filepath中** @param url* @param diskUrl* @return*/public static String download(String url, String diskUrl) {String filepath = "";String filename = "";try {HttpClient client = HttpClients.createDefault();HttpGet httpget = new HttpGet(url);// 加入Referer,防止防盗链httpget.setHeader("Referer", url);HttpResponse response = client.execute(httpget);HttpEntity entity = response.getEntity();InputStream is = entity.getContent();if (StringUtils.isBlank(filepath)){Map<String,String> map = getFilePath(response,url,diskUrl);filepath = map.get("filepath");filename = map.get("filename");}File file = new File(filepath);file.getParentFile().mkdirs();FileOutputStream fileout = new FileOutputStream(file);byte[] buffer = new byte[cache];int ch = 0;while ((ch = is.read(buffer)) != -1) {fileout.write(buffer, 0, ch);}is.close();fileout.flush();fileout.close();} catch (Exception e) {e.printStackTrace();}return filename;}/*** 根据contentType 获取对应的后缀 (列出常用的ContentType对应的后缀)** @param contentType* @return*/static String getContentType(String contentType){HashMap<String, String> map = new HashMap<String, String>() {{put("application/msword", ".doc");put("image/jpeg", ".jpeg");put("application/x-jpg", ".jpg");put("video/mpeg4", ".mp4");put("application/pdf", ".pdf");put("application/x-png", ".png");put("application/x-ppt", ".ppt");put("application/postscript", ".ps");put("application/vnd.android.package-archive", ".apk");put("video/avi", ".avi");put("text/html", ".htm");put("image/png", ".png");put("application/x-png", ".png");put("image/gif", ".gif");}};return map.get(contentType);}/*** 获取response要下载的文件的默认路径** @param response* @return*/public static Map<String,String> getFilePath(HttpResponse response, String url, String diskUrl) {Map<String,String> map = new HashMap<>();String filepath = diskUrl;String filename = getFileName(response, url);String contentType = response.getEntity().getContentType().getValue();if(StringUtils.isNotEmpty(contentType)){// 获取后缀String suffix = getContentType(contentType);String regEx = ".+(.+)$";Pattern p = Pattern.compile(regEx);Matcher m = p.matcher(filename);if (!m.find()) {// 如果正则匹配后没有后缀,则需要通过response中的ContentType的值进行匹配if(StringUtils.isNoneBlank(suffix)){filename = filename + suffix;}}else{if(filename.length()>20){filename = getRandomFileName() + suffix;}}}if (filename != null) {filepath += filename;} else {filepath += getRandomFileName();}map.put("filename", filename);map.put("filepath", filepath);return map;}/*** 获取response header中Content-Disposition中的filename值* @param response* @param url* @return*/public static String getFileName(HttpResponse response,String url) {Header contentHeader = response.getFirstHeader("Content-Disposition");String filename = null;if (contentHeader != null) {// 如果contentHeader存在HeaderElement[] values = contentHeader.getElements();if (values.length == 1) {NameValuePair param = values[0].getParameterByName("filename");if (param != null) {try {filename = param.getValue();} catch (Exception e) {e.printStackTrace();}}}}else{// 正则匹配后缀filename = getSuffix(url);}return filename;}/*** 获取随机文件名** @return*/public static String getRandomFileName() {return String.valueOf(System.currentTimeMillis());}/*** 获取文件名后缀* @param url* @return*/public static String getSuffix(String url) {// 正则表达式“.+/(.+)$”的含义就是:被匹配的字符串以任意字符序列开始,后边紧跟着字符“/”,// 最后以任意字符序列结尾,“()”代表分组操作,这里就是把文件名做为分组,匹配完毕我们就可以通过Matcher// 类的group方法取到我们所定义的分组了。需要注意的这里的分组的索引值是从1开始的,所以取第一个分组的方法是m.group(1)而不是m.group(0)。String regEx = ".+/(.+)$";Pattern p = Pattern.compile(regEx);Matcher m = p.matcher(url);if (!m.find()) {// 格式错误,则随机生成个文件名return String.valueOf(System.currentTimeMillis());}return m.group(1);}}
测试
运行main方法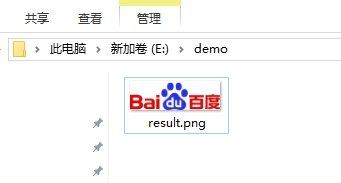




























洞悉linux下的Netfilter&iptables:iptables命令行工具源码解析【上】")
洞悉linux下的Netfilter&iptables:为防火墙增添功能模块【实战】")
洞悉linux下的Netfilter&iptables:开发一个match模块【实战】")


还没有评论,来说两句吧...