pandas根据索引删除dataframe列
如何根据索引删除dataframe的多个列呢?
核心代码逻辑:
# 要删除的列,注意索引是从0开始的x = [0, 2, 8, 9, 10, 11, 12]df.drop(df.columns[x], axis=1, inplace=True)
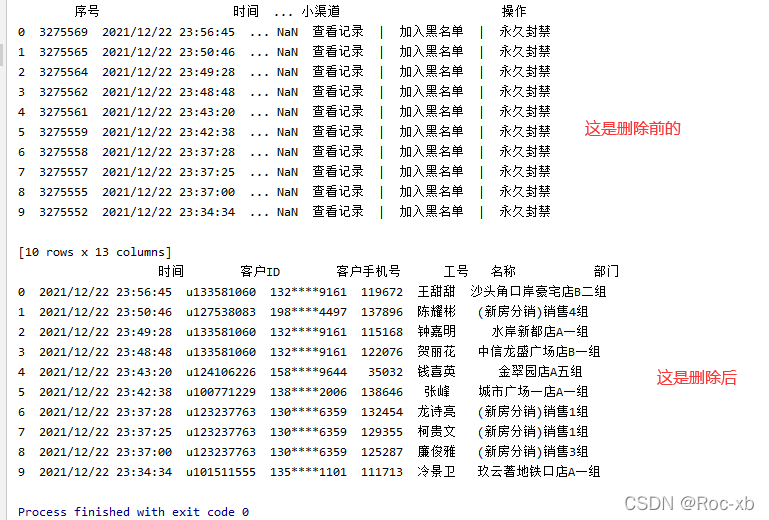
如何根据索引删除dataframe的多个列呢?
核心代码逻辑:
# 要删除的列,注意索引是从0开始的x = [0, 2, 8, 9, 10, 11, 12]df.drop(df.columns[x], axis=1, inplace=True)
*输入数据: ** import pandas as pd data = { '证券名称': ['格力电器', '视觉中国',...
使用pandas删除dataframe中缺失值的列 在pandas中,我们可以使用dropna函数来删除dataframe中的缺失值。如果我们想要删除所有数据均为缺失值的列,
1.删除/选取某列含有特殊数值的行 import pandas as pd import numpy as np a=np.array(\[\[1,2,3\],\[4
> 如何根据索引删除dataframe的多个列呢? 核心代码逻辑: 要删除的列,注意索引是从0开始的 x = [0, 2, 8, 9, 10, 1
1. 选取等于某个特定值的行记录,用 == df.loc[df['column_name'] == some_value] 2. 选取等于某些的数值的行记录,用
1. 删除 / 选取某列含有特殊数值的行 import pandas as pd import numpy as np a=np.a
平时在用DataFrame时候,删除操作用的不太多。原数据包含的信息过多,或者生成了新的无用信息行/列,需要从DataFrame中筛选数据,组成一个新的DataFrame再继续
我正在从网上阅读一些自动天气数据 . 观察每5分钟发生一次,并编译成每个气象站的月度文件 . 一旦我完成了解析文件,DataFrame看起来像这样: Sta Precip1h
Python:3.8.5 pandas:1.1.3 [][Link 1]按行遍历DataFrame: [pandas.DataFrame.i
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 参数说明:

























——管道符")
——通配符与其他特殊符号")


地图制作")




还没有评论,来说两句吧...