《Lucid Data Dreaming for Video Object Segmentation》论文笔记
参考代码:LucidDataDreaming
1. 概述
导读:文章针对在运动场景下需要高质量表现模型(VOS)的训练过程进行了探究,一般来讲训练这些模型到较高的性能,需要较多样的数据,这就需要较多的数据量,而这篇文章中比较有意思的点是提出了一种数据合成方法lucid data dreaming,文章使用这样的数据增广方式可以将需要的数据量减少20~1000倍,但是取得的效果能够与采用原始方法进行训练得到的结果近似,是一种和具有实用价值的数据增广技术。
这篇文章的方法嵌入到视频分割算法的训练流中,其流程见下图所示: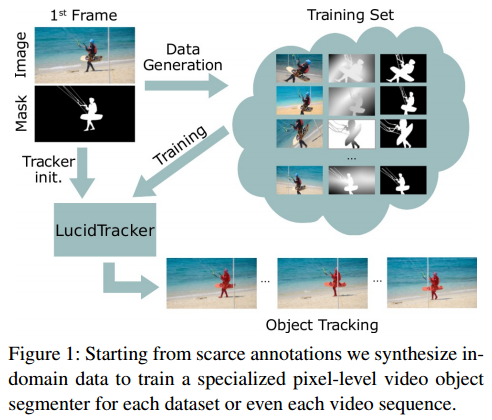
2. 方法设计
2.1 视频分割网络
文章中使用的视频分割方法利用了原始的图像数据 I t I_t It,前一帧的分割结果 M t − 1 M_{t-1} Mt−1,视频当前帧的光流梯度(使用FlowNet2) F t = h ( I t − 1 , I t ) F_t=h(I_{t-1},I{t}) Ft=h(It−1,It),因而将上面的信息可以得到2个stream的视频分割网络结构(一个stream输入为RGB图像,一个维光流梯度),之后把这两个stream的输出经过平均输出,则对应的输出为:
M t = 0.5 ∗ f I ( I t , … ) + 0.5 ∗ f F ( ∣ ∣ F t ∣ ∣ , … ) M_t=0.5*f_I(I_t,\dots)+0.5*f_F(||F_t||,\dots) Mt=0.5∗fI(It,…)+0.5∗fF(∣∣Ft∣∣,…)
其结构是对应的图3(a)图所示,但是文章将RGB与光流在channel上结合得到只有一个stream的网络,经过实际测试发现它们其实并没有太大的性能区别,见图3(b),其对应的输出表达为:
M t = f I + F ( I t , ∣ ∣ F t ∣ ∣ , w ( M t − 1 , F t ) ) M_t=f_{I+F}(I_t,||F_t||,w(M_{t-1},F_t)) Mt=fI+F(It,∣∣Ft∣∣,w(Mt−1,Ft))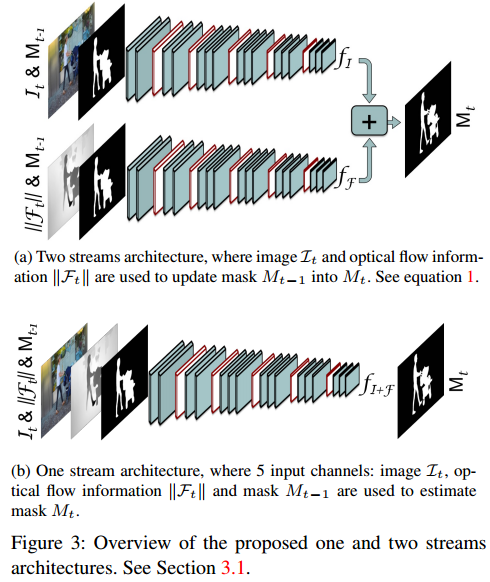
两种网络结构带来的性能比较: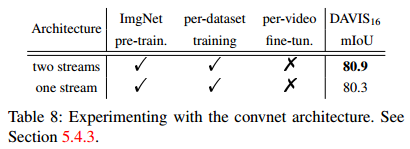
实现多类分割
在文章现有的网络结构下是能够实现多类的目标分割的,而这篇文章是将不同类别的目标拆分为不同的channel作为整个网络的输入,因而网络的输入就便成为了 3 + N 3+N 3+N,代表的是RGB通道数据与对应的 N N N个分割目标,则结合前一帧的分割结果 S S S,则整个的输出可以描述为:
M t = f I + F + S ( I t , ∣ ∣ F t ∣ ∣ , S t , w ( M t − 1 1 , F t ) , … , w ( M t − 1 N , F t ) ) M_t=f_{I+F+S}(I_t,||F_t||,S_t,w(M_{t-1}^1,F_t),\dots,w(M_{t-1}^N,F_t)) Mt=fI+F+S(It,∣∣Ft∣∣,St,w(Mt−11,Ft),…,w(Mt−1N,Ft))
其对应的网络结构见图4所示: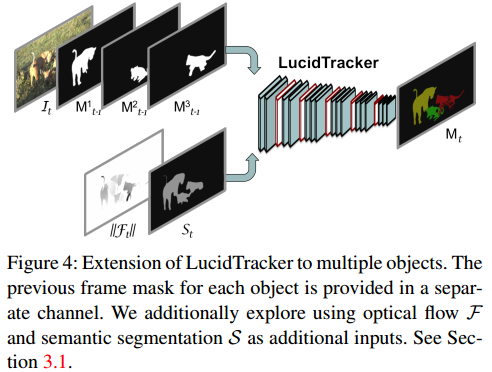
时序上的相关性
在前面的式子中会将前一帧的分割结果与当前帧的光流梯度进行整合 w ( M t − 1 , F t ) w(M_{t-1},F_t) w(Mt−1,Ft),但从这个表达上看当前结果只与前一帧的结果相关而不与 t − 2 t-2 t−2帧的结果相关,文章在测试阶段从减少累积误差的角度将 t − 1 t-1 t−1与 t − 2 t-2 t−2帧的结果融合,既是只保留两帧结果相重合的部分,得到 M t − 1 ^ \hat{M_{t-1}} Mt−1^,之后再与光流结合 w ( M t − 1 ^ , F t ) w(\hat{M_{t-1}},F_t) w(Mt−1^,Ft)。
2.2 Lucid data dreaming
由于真实的数据较难以获取,因而在现有的数据上进行增广就显得尤为重要,这也是这篇文章着力表现的一点,除了包含光照变化、形变、平移、遮挡之外,还会进行动态的背景变化,也就是把前景抠出来替变化之前的背景,实现数据增广。在处理过程中会随机的选择两组参数得到两个变化后的图像 ( I τ − 1 , I τ ) (I_{\tau-1},I_{\tau}) (Iτ−1,Iτ),对应的标签是 ( M τ − 1 , M τ ) (M_{\tau-1},M_{\tau}) (Mτ−1,Mτ),光流 F τ F_{\tau} Fτ,图像中的目标区域会被统一采样,这是为了减少相邻两帧之间的变化,具体的变化方法如下:
- 1)光照变化,就是在HSV空间上对S与V分量进行非线性映射;
- 2)背景分离与替换:将图像中的前景区域抠出之后使用别的背景填充;
- 3)目标移动:这通过全局的affine(平移正负10%,旋转正负30%,缩放正负15%)与non-grid(thin-plate正负10%变形)变化去模拟目标的移动与变形;
- 4)相机运动模拟:在背景上使用affine变化去模拟相机的视场变化;
- 5)前景背景融合:将经过扰动的前景与背景信息通过Poisson matting融合得到 ( I τ − 1 , I τ ) (I_{\tau-1},I_{\tau}) (Iτ−1,Iτ),至于对应的分割标注与光流也是按照响应的参数进行变化;
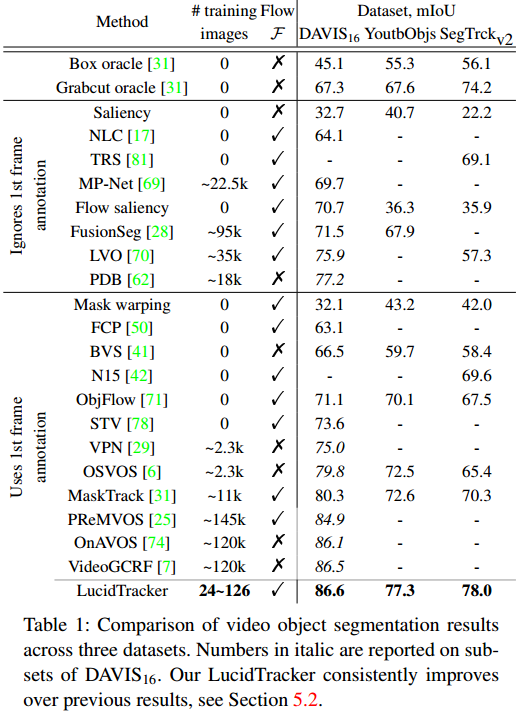
3. 实验结果




























还没有评论,来说两句吧...