《VPS:Video Panoptic Segmentation》论文笔记
参考代码:vps
1. 概述
导读:文章的这篇文章整合了全景分割(实例分割+语义分割)和视频分割算法,从而得到在视频场景下的全景分割算法。其算法是构建在Mask RCNN/ MaskTrack RCNN/ UPSNet的基础之上,但是在这个基础之上文章还强调了视频时序中信息的萃取(spatial-temporal attention),从而增加了视频中实例的分割性能鲁棒性(也就是文章中提到的pixel level fusion)。针对文章的任务,作者在全景分割的基础上提出了视频场景下的性能评价指标VPQ(video panoptic quality)。此外,还提供了两个视频全景分割的数据集VIPER和Cityscapes-VPS。
与一般的视频分割/跟踪方法一致,给定一帧参考帧,之后在后续的帧上建立与第一帧的关系,在这个过程中文章使用了基于光流的特征图对齐/spatial attention block/实例相似性矩阵方法,构建了一个较为鲁棒的视频全景分割算法,该算法在文章给出的两个数据集上的表现见下图所示:
视频全景分割评价指标(VPQ):
对于一个给定的视频段: I t : t + k = { I t , I t + 1 , … , I t + k } I^{t:t+k}=\{I^t,I^{t+1},\dots,I^{t+k}\} It:t+k={ It,It+1,…,It+k}(其中的参数 k k k是在视频序列上的滑动窗口),其中一帧对应的分割结果描述为: U ^ ( c i , z i ) = { s ^ t , s ^ t + 1 , … , s ^ t + k } \hat{U}(c_i,z_i)=\{\hat{s}^t,\hat{s}^{t+1},\dots,\hat{s}^{t+k}\} U^(ci,zi)={ s^t,s^t+1,…,s^t+k}。其中, c i c_i ci代表的是语义分割的类别, z i z_i zi代表的是在该语义分割类别的基础上各个实例的索引值。那么整个序列的分割预测结果描述为 U ^ t : t + k \hat{U}^{t:t+k} U^t:t+k,真实的标注描述为 U t : t + k U^{t:t+k} Ut:t+k。
在进行性能度量计算之前,文章定义了正样本为 T P = { ( u , u ^ ) ∈ U ∗ U ^ : I o U ( u , u ^ ) > 0.5 } TP=\{(u,\hat{u})\in U*\hat{U}:IoU(u,\hat{u})\gt 0.5\} TP={ (u,u^)∈U∗U^:IoU(u,u^)>0.5},对应的FP和FN以此类推。在窗口序列 { t : t + k } \{t:t+k\} { t:t+k}上,文章还引入了stride参数 λ \lambda λ(也就是在这个窗口里面还要进行跳跃采样。则文章将性能的度量描述为:
V P Q k = 1 N c l a s s e s ∑ c ∑ ( u , u ^ ) ∈ T P c I o U ( u , u ^ ) ∣ T P c ∣ + 1 2 ∣ F P ∣ c + 1 2 ∣ F N ∣ c VPQ^k=\frac{1}{N_{classes}}\sum_c\frac{\sum_{(u,\hat{u})\in TP_c}IoU(u,\hat{u})}{|TP_c|+\frac{1}{2}|FP|_c+\frac{1}{2}|FN|_c} VPQk=Nclasses1c∑∣TPc∣+21∣FP∣c+21∣FN∣c∑(u,u^)∈TPcIoU(u,u^)
对于上面提到的滑动窗口的取值,文章在实际中将其设置为 { 0 , 5 , 10 , 15 } \{0,5,10,15\} { 0,5,10,15},在其为0的时候就等价于单张图像的全景分割。则经过不同大小的滑动窗口其最后的性能度量描述为:
V P Q = 1 K ∑ k V P Q k , K = 4 VPQ=\frac{1}{K}\sum_kVPQ^k,K=4 VPQ=K1k∑VPQk,K=4
不同K值对性能的影响: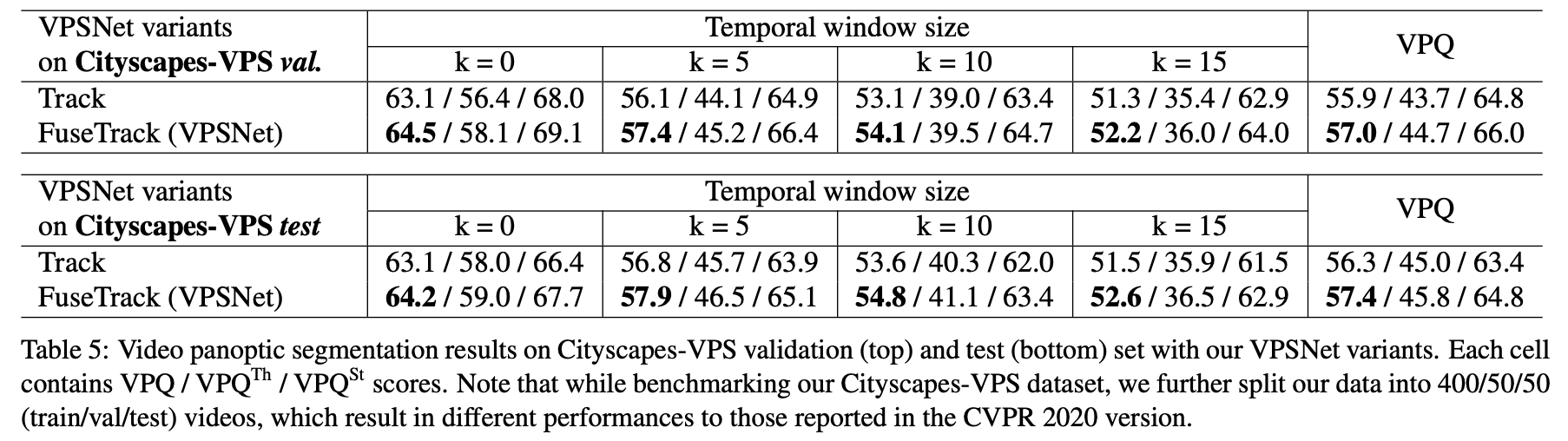
其计算的过程可见下图的描述: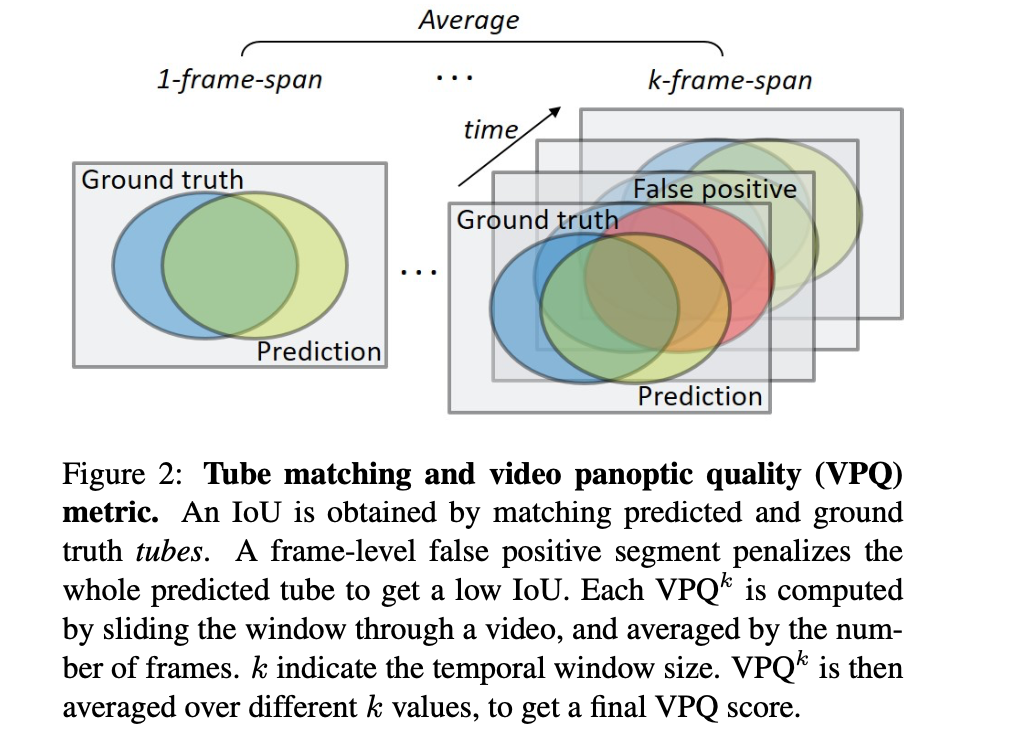
视频全景分割数据集:
文章将其提供的视频全景数据集与其它数据集进行比较,见下表所示: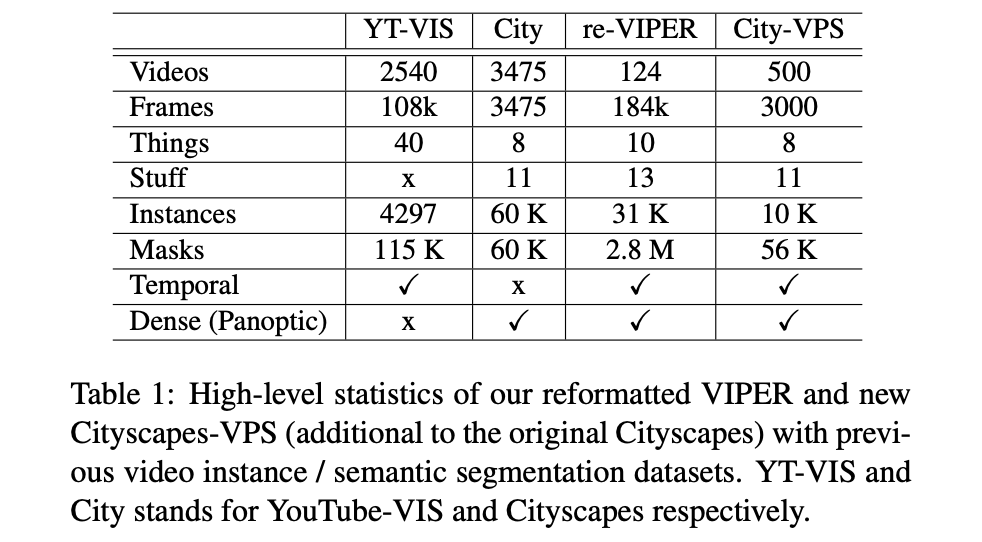
2. 方法设计
2.1 网络结构
文章的整体pipeline见下图所示: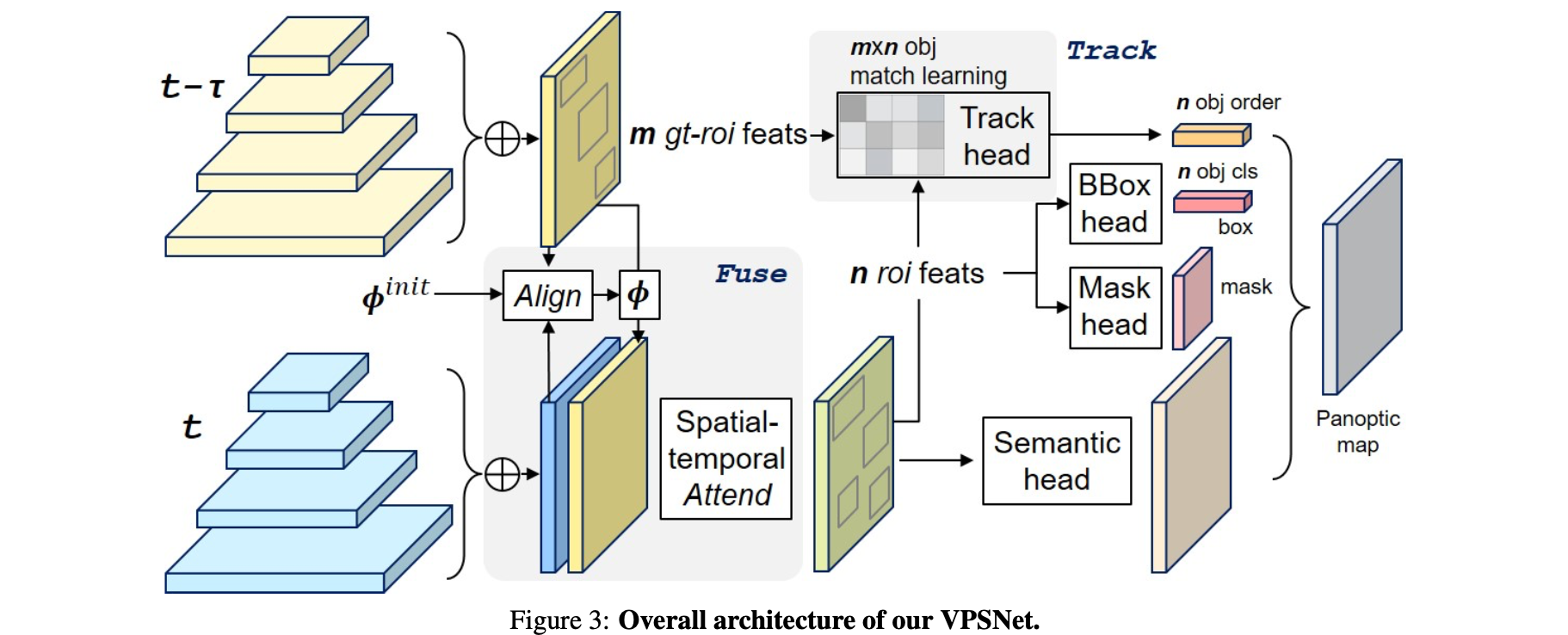
整体上看为了引入更多视频序列的信息,文章使用了多帧的的特征(并没有像VIS那篇文章里面只是使用了instance的特征),其该pipeline中最为关键的是两个模块:
- 1)pixel-wise:其中的Spatial temporal attention模块,它实现的是pixel-wise的fusion操作,起到特征聚合和增强的作用;
- 2)object-wise:instance track(instance相似性度量)模块,起到匹配不同instance的作用,建立起instance之间的关系;
最后文章参考UPSNet的方法引入了该方法中的panoptic预测头,从而得到最后的全景分割结果。
2.2 关键子模块
特征抽取网络部分:
这部分是一般意义上的backbone+FPN的结构,但是对其中的FPN网络使用了Libra-RCNN中的特征增强,也就是先聚合之后经过残差连接(与聚合之前的对应层)redistributed进行输出,其聚合部分(gather)的实现为:
# source: mmdet/models/extra_necks/bfp_tcea.py:96# inputs: FPN不同层级的输出def gather(self, inputs):# gather multi-level features by resize and averagefeats = []gather_size = inputs[self.refine_level].size()[2:]for i in range(self.num_levels):if i < self.refine_level:gathered = F.adaptive_max_pool2d(inputs[i], output_size=gather_size)else:gathered = F.interpolate(inputs[i], size=gather_size, mode='nearest')feats.append(gathered)bsf = sum(feats) / len(feats)return bsf
中间会经过文章的spatial-temporal attention模块进行特征增强,之后在进行redistributed,这部分的实现为:
# source: mmdet/models/extra_necks/bfp_tcea.py:142# Scatter refined features to multi-levels by residual pathouts = []for i in range(self.num_levels):out_size = inputs[i].size()[2:]if i < self.refine_level:residual = F.interpolate(bsf, size=out_size, mode='nearest')else:residual = F.adaptive_max_pool2d(bsf, output_size=out_size)outs.append(residual + inputs[i])
pixel-wise fusion部分:
这里是将参考帧的特征和当前帧的特征进行聚合和增强,从而提升网络的判别能力。对于输入的参考帧和当前帧特征经过上述过程的聚合,之后使用光流方法,将参考帧的特征按照光流信息转换到当前帧下,从而实现特征的对齐。其对应的代码实现为:
# source: mmdet/models/extra_necks/bfp_tcea.py:116bsf = self.gather(inputs) # 当前帧特征图上gatherref_bsf = self.gather(ref_inputs) # 参考帧特征图上gatherB,C,H,W = bsf.size()# 通过估计的光流信息,使用光流作为变换指引实现参考帧到当前帧的对齐warp_bsf = self.flow_warping(ref_bsf, flow_init)flow_fine = self.liteflownet(bsf, warp_bsf, flow_init)warp_bsf = self.flow_warping(warp_bsf, flow_fine)
对齐之后的特征会进行spatial-temporal上的增强,其实现为:
# source: mmdet/models/extra_necks/bfp_tcea.py:134# 使用temporal-spatial attention优化特征bsf = self.tcea_fusion(bsf_stack) # B,2,C,H,W -> B,1,C,H,W
上面的实现是分为temporal和spatial上进行的:
# source: mmdet/models/utils/tcea_modules.py:50def forward(self, aligned_fea):B, N, C, H, W = aligned_fea.size() # N video frames#### temporal attentionemb_ref = self.tAtt_2(aligned_fea[:, self.center, :, :, :].clone())emb = self.tAtt_1(aligned_fea.view(-1, C, H, W)).view(B, N, -1, H, W) # [B, N, C(nf), H, W]cor_l = []for i in range(N):emb_nbr = emb[:, i, :, :, :]cor_tmp = torch.sum(emb_nbr * emb_ref, 1).unsqueeze(1) # B,1,1,H,W --> B, 1, H, Wcor_l.append(cor_tmp)cor_prob = torch.sigmoid(torch.cat(cor_l, dim=1)) # B, N, H, Wcor_prob = cor_prob.unsqueeze(2).repeat(1, 1, C, 1, 1).view(B, -1, H, W)aligned_fea = aligned_fea.view(B, -1, H, W) * cor_prob#### fusionfea = self.lrelu(self.fea_fusion(aligned_fea))#### spatial attentionatt = self.lrelu(self.sAtt_1(aligned_fea))att_max = self.maxpool(att)att_avg = self.avgpool(att)att = self.lrelu(self.sAtt_2(torch.cat([att_max, att_avg], dim=1)))att = self.lrelu(self.sAtt_3(att))att = F.interpolate(att, scale_factor=2, mode='bilinear', align_corners=False)att = self.sAtt_4(att)att_add = self.sAtt_add_2(self.lrelu(self.sAtt_add_1(att)))att = torch.sigmoid(att)fea = fea * att * 2 + att_addreturn fea
增强之后的特征便使用上述提到的redistributed操作进行特征分层。
object-wise跟踪:
这部分是将参考帧与当前帧之间的object相关联起来,可以看作是做了一次ReID。该方法来自于MaskTrack RCNN,构建一个 m ∗ n m*n m∗n的相似性矩阵,从而将当前帧的object: { r 1 , r 2 , … , r n } t \{r_1,r_2,\dots,r_n\}_t { r1,r2,…,rn}t和参考帧object: { r 1 , r 2 , … , r m } t − τ \{r_1,r_2,\dots,r_m\}_{t-\tau} { r1,r2,…,rm}t−τ,对于每一个object pair { r i , t , r j , t − τ } \{r_{i,t},r_{j,t-\tau}\} { ri,t,rj,t−τ}其经过共享参数的全连接层编码之后得到对应的特征对 { e i , t , e j , t − τ } \{e_{i,t},e_{j,t-\tau}\} { ei,t,ej,t−τ},在文章中对于这两个特征之间的距离描述为:
A i , j = c o s i n e ( e i , t , e j , t − τ ) A_{i,j}=cosine(e_{i,t},e_{j,t-\tau}) Ai,j=cosine(ei,t,ej,t−τ)
参与跟踪的特征由于是通过spatial-temporal attention进行特征增强,因而其不仅引入了时许信息,而且变得更加具有区分能力。这部分在训练的时候并没有参与到最后panoptic map的生成,只是在inference的时候参与对应object的关联。
总结上文提到的光流Align/spatial-temporal attention/ 两者fusion/ track对网络性能带来的影响: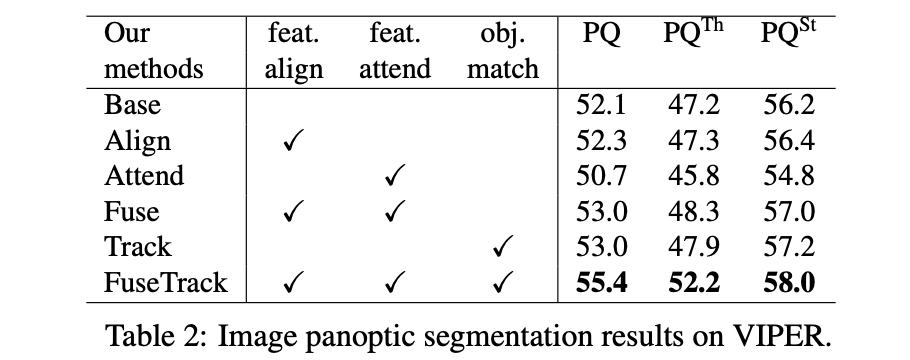
3. 实验结果
文章方法与其它全景分割算法的性能对比: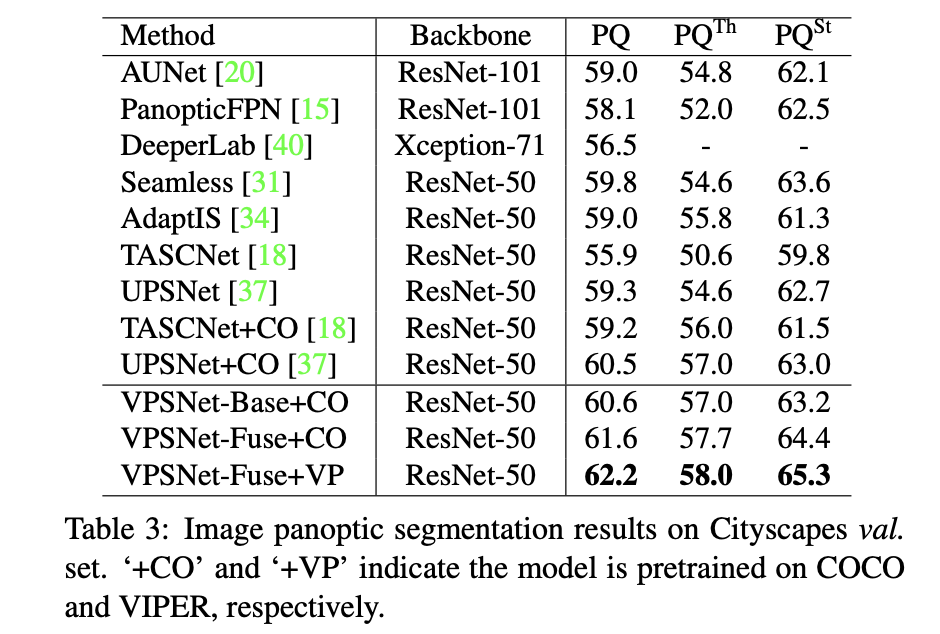

























![[亲测]java.sql.SQLException: Parameter number X is not an OUT parameter](https://image.dandelioncloud.cn/dist/img/NoSlightly.png "[亲测]java.sql.SQLException: Parameter number X is not an OUT parameter")


还没有评论,来说两句吧...