数据清洗处理-常用操作
介绍一些常见的数据处理操作及代码实现
内容包括:
数据内存缩小
重复值处理
缺失值处理
异常值处理
标准化
特征二值化
多项式特征构建
类别特征编码
1.数据转存,缩小内存
def reduce_mem_usage(df):""" iterate through all the columns of a dataframe and modify the data type to reduce memory usage. """start_mem = df.memory_usage().sum()print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))for col in df.columns:col_type = df[col].dtypeif col_type != object:c_min = df[col].min()c_max = df[col].max()if str(col_type)[:3] == 'int':if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:df[col] = df[col].astype(np.int8)elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:df[col] = df[col].astype(np.int16)elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:df[col] = df[col].astype(np.int32)elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:df[col] = df[col].astype(np.int64)else:if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:df[col] = df[col].astype(np.float16)elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:df[col] = df[col].astype(np.float32)else:df[col] = df[col].astype(np.float64)else:df[col] = df[col].astype('category')end_mem = df.memory_usage().sum()print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))return dfsample_feature = reduce_mem_usage(pd.read_csv('data_for_tree.csv'))# 数据清洗常用操作# 重复值处理print('存在' if any(train_data.duplicated()) else '不存在', '重复观测值')train_data.drop_duplicates()#缺失值处理print('存在' if any(train_data.isnull()) else '不存在', '缺失值')train_data.dropna() # 直接删除记录train_data.fillna(method='ffill') # 前向填充train_data.fillna(method='bfill') # 后向填充train_data.fillna(value=2) # 值填充train_data.fillna(value={ 'sepal length (cm)':train_data['sepal length (cm)'].mean()}) # 统计值填充train_data['Fare'] = train_data[['Fare']].fillna(train_data.groupby('Pclass').transform(np.mean))#使用其他特征groupby后的均值进行填充# 缺失值插补x = [[np.nan, '1', '3'], [np.nan, '3', '5']]imputer = preprocessing.Imputer(missing_values='NaN', strategy='mean', axis=1)y = imputer.fit_transform(x)# 异常值处理data1 = train_data['sepal length (cm)']# 标准差监测xmean = data1.mean()xstd = data1.std()print('存在' if any(data1>xmean+2*xstd) else '不存在', '上限异常值')print('存在' if any(data1<xmean-2*xstd) else '不存在', '下限异常值')# 箱线图监测q1 = data1.quantile(0.25)q3 = data1.quantile(0.75)up = q3+1.5*(q3-q1)dw = q1-1.5*(q3-q1)print('存在' if any(data1> up) else '不存在', '上限异常值')print('存在' if any(data1< dw) else '不存在', '下限异常值')data1[data1>up] = data1[data1<up].max()data1[data1<dw] = data1[data1>dw].min()标准化# 0-1标准化X_train_minmax = preprocessing.minmax_scale(train_data, feature_range=(0, 1), axis=0, copy=True) # 直接用标准化函数min_max_scaler = preprocessing.MinMaxScaler() # 也可以用标准化类,然后调用方法X_train_minmax2 = min_max_scaler.fit_transform(train_data)# z-score标准化X_train_zs = preprocessing.scale(train_data, axis=0, with_mean=True, with_std=True, copy=True) # 直接用标准化函数zs_scaler = preprocessing.StandardScaler() # 也可以用标准化类,然后调用方法X_train_zs2 = zs_scaler.fit_transform(train_data)# 归一化处理X_train_norm = preprocessing.normalize(train_data, norm='l2', axis=1) # 直接用标准化函数normalizer = preprocessing.Normalizer() # 也可以用标准化类,然后调用方法X_train_norm2 = normalizer.fit_transform(train_data)# 数据的缩放比例为绝对值最大值,并保留正负号,即在区间[-1, 1]内。#唯一可用于稀疏数据scipy.sparse的标准化X_train_ma = preprocessing.maxabs_scale(X, axis=0, copy=True)# 通过 Interquartile Range(IQR) 标准化数据,即四分之一和四分之三分位点之间X_train_rb = preprocessing.robust_scale(train_data, axis=0,with_centering=True, with_scaling=True, copy=True)# 二值化# 按照阈值threshold将数据转换成成0-1,小于等于threshold为 0X_train_binary = preprocessing.binarize(train_data, threshold=0, copy=True)
特征二值化,
给定特征将特征转化为0/1
binarizer = sklearn.preprocessing.Binarizer(threshold=1.1)binarizer.transform(X)
多项式特征构建:
poly = sklearn.preprocessing.PolynomialFeatures(2)poly.fit_transform(X)
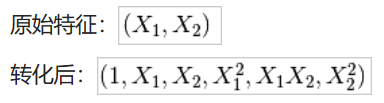
对于类别特征需要进行编码
常见编码方式有LabelEncoder、OneHotEncoder,以及针对高数量类别特征编码— 均值编码
其中:LabelEncoder能够接收不规则的特征列,并将其转化为从到的整数值(假设一共有种不同的类别);OneHotEncoder则能通过哑编码,制作出一个m*n的稀疏矩阵(假设数据一共有m行,具体的输出矩阵格式是否稀疏可以由sparse参数控制)
还有针对高数量类别特征编码— 均值编码
from sklearn.preprocessing import OneHotEncoder, LabelEncoderimport numpy as npimport pandas as pdle = LabelEncoder()data_df['street_address'] = le.fit_transform(data_df['street_address'])ohe = OneHotEncoder(n_values='auto', categorical_features='all',dtype=np.float64, sparse=True, handle_unknown='error')one_hot_matrix = ohe.fit_transform(data_df['street_address'])
对于均值编码实现,可参考https://blog.csdn.net/juzexia/article/details/78581462
#
参考:
https://blog.csdn.net/Trisyp/article/details/89371094
https://blog.csdn.net/RivenDong/article/details/100120333?depth\_1-utm\_source=distribute.pc\_relevant.none-task&utm\_source=distribute.pc\_relevant.none-task




























还没有评论,来说两句吧...