Lucene快速入门第四讲——索引库的维护
这一讲,主要讲索引库的维护,索引库的维护包括对索引库的添加、删除、修改以及查询等部分,也就是通常意义上所说的增删改查,接下来,这些我都会一一介绍到。
索引库的添加
在《Lucene快速入门第二讲——首次使用Lucene,开不开心!》这一讲中,索引库的添加的这一操作,我就已讲过,故在此并不过多赘述。
索引库的删除
索引库的删除包括删除全部索引和根据条件删除(文档),接下来,我会一一介绍这俩操作,先来看看删除全部索引这一波操作。
删除全部索引
删除全部索引指的是将索引目录的索引信息全部删除,直接彻底删除,无法恢复,所以,这一操作一定要慎用!
这一操作的实现代码是啥样的呢?我想一定有人很好奇,这不,下面我就给出了具体的实现代码,而大家真正需要关注的地方就是testAllDelete方法是怎么写出来的。
package com.meimeixia.lucene;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.junit.Test;import org.wltea.analyzer.lucene.IKAnalyzer;/** * 索引维护 * 添加:入门程序讲过了 * 删除 * 修改 * 查询:入门程序讲过了,介绍的是精准查询 * @author liayun * */public class LuceneManager {public IndexWriter getIndexWriter() throws Exception {// 第一步:创建一个java工程,并导入jar包// 第二步:创建一个IndexWriter对象,FSDirectory(file system directory)// 1)指定索引库的存放位置,例如D:\\temp\\index这个目录// 2)指定一个分析器,来对文档内容进行分析,怎么进行分析的,我想你应该知道了!Directory directory = FSDirectory.open(Paths.get("D:\\temp\\index"));//自动创建索引库// 创建一个第三方中文分析器对象Analyzer analyzer = new IKAnalyzer();IndexWriterConfig config = new IndexWriterConfig(analyzer);return new IndexWriter(directory, config);}// 全删除(删除全部索引)@Testpublic void testAllDelete() throws Exception {IndexWriter indexWriter = getIndexWriter();// 删除全部索引indexWriter.deleteAll(); // 注意:此方法一定要慎用!indexWriter.close();}}
根据条件删除(文档)
根据条件删除(文档)这一操作的实现代码具体如下,你主要关注testDelete方法就行。
package com.meimeixia.lucene;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.Term;import org.apache.lucene.search.Query;import org.apache.lucene.search.TermQuery;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.junit.Test;import org.wltea.analyzer.lucene.IKAnalyzer;/** * 索引维护 * 添加:入门程序讲过了 * 删除 * 修改 * 查询:入门程序讲过了,介绍的是精准查询 * @author liayun * */public class LuceneManager {public IndexWriter getIndexWriter() throws Exception {// 第一步:创建一个java工程,并导入jar包// 第二步:创建一个IndexWriter对象,FSDirectory(file system directory)// 1)指定索引库的存放位置,例如D:\\temp\\index这个目录// 2)指定一个分析器,来对文档内容进行分析,怎么进行分析的,我想你应该知道了!Directory directory = FSDirectory.open(Paths.get("D:\\temp\\index"));//自动创建索引库// 创建一个第三方中文分析器对象Analyzer analyzer = new IKAnalyzer();IndexWriterConfig config = new IndexWriterConfig(analyzer);return new IndexWriter(directory, config);}// 全删除(删除全部索引)@Testpublic void testAllDelete() throws Exception {IndexWriter indexWriter = getIndexWriter();// 删除全部索引indexWriter.deleteAll(); // 注意:此方法一定要慎用!indexWriter.close();}// 根据条件删除(文档)@Testpublic void testDelete() throws Exception {IndexWriter indexWriter = getIndexWriter();Query query = new TermQuery(new Term("fileName", "apache"));indexWriter.deleteDocuments(query);indexWriter.close();}}
索引库的修改
这一操作的原理就是先删除后添加,具体的实现代码请参见如下testUpdate方法。
package com.meimeixia.lucene;import java.nio.file.Paths;import org.apache.lucene.analysis.Analyzer;import org.apache.lucene.document.Document;import org.apache.lucene.document.Field.Store;import org.apache.lucene.document.TextField;import org.apache.lucene.index.IndexWriter;import org.apache.lucene.index.IndexWriterConfig;import org.apache.lucene.index.Term;import org.apache.lucene.search.Query;import org.apache.lucene.search.TermQuery;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.junit.Test;import org.wltea.analyzer.lucene.IKAnalyzer;/** * 索引维护 * 添加:入门程序讲过了 * 删除 * 修改 * 查询:入门程序讲过了,介绍的是精准查询 * @author liayun * */public class LuceneManager {public IndexWriter getIndexWriter() throws Exception {// 第一步:创建一个java工程,并导入jar包// 第二步:创建一个IndexWriter对象,FSDirectory(file system directory)// 1)指定索引库的存放位置,例如D:\\temp\\index这个目录// 2)指定一个分析器,来对文档内容进行分析,怎么进行分析的,我想你应该知道了!Directory directory = FSDirectory.open(Paths.get("D:\\temp\\index"));//自动创建索引库// 创建一个第三方中文分析器对象Analyzer analyzer = new IKAnalyzer();IndexWriterConfig config = new IndexWriterConfig(analyzer);return new IndexWriter(directory, config);}// 全删除(删除全部索引)@Testpublic void testAllDelete() throws Exception {IndexWriter indexWriter = getIndexWriter();// 删除全部索引indexWriter.deleteAll(); // 注意:此方法一定要慎用!indexWriter.close();}// 根据条件删除(文档)@Testpublic void testDelete() throws Exception {IndexWriter indexWriter = getIndexWriter();Query query = new TermQuery(new Term("fileName", "apache"));indexWriter.deleteDocuments(query);indexWriter.close();}// 修改(删掉一个,再添加一个,就是修改)@Testpublic void testUpdate() throws Exception {IndexWriter indexWriter = getIndexWriter();// 创建一个Document对象Document doc = new Document();// 向Document对象中添加域,不同的Document对象可以有不同的域,同一个Document对象可以有相同的域doc.add(new TextField("fileN", "测试文件名", Store.YES));doc.add(new TextField("fileC", "测试文件内容", Store.YES)); // 此刻,该文档有6个域// 此时,是先把文件名称中有以lucene为关键字的Doucment对象干掉,再把新创建的Doucment对象添加进去indexWriter.updateDocument(new Term("fileName", "lucene"), doc);indexWriter.close();}}
温馨提示:此时,新创建的Document对象中有6个域,因为在前面创建索引库时,一个Document对象就包含了4个域,分别是文件名称、文件大小、文件路径以及文件内容,再加上新创建的Document对象中的2个域,所以说一共有6个域。
索引库的查询
首先给大家打一个预防针,索引库的查询是索引库的维护中最重要的部分,所以你必须要能熟练查询索引库。
如何查询索引库呢?对要搜索的信息创建Query查询对象,Lucene会根据Query查询对象生成最终的查询语法,类似关系型数据库SQL语法一样,Lucene也有自己的查询语法,比如:”name:lucene”表示查询Field的name为”lucene”的文档信息。并且,大家可通过如下两种方法创建Query查询对象。
如此一来,查询索引库就有两种方法了,一种是使用Query抽象类的子类查询,另外一种是使用QueryParser查询,这种方法主要是使用QueryParser来解析查询表达式,然后使用语法来查询。下面我会分别介绍这两种方法。
使用Query抽象类的子类查询
Query抽象类的子类有很多,例如MatchAllDocsQuery、TermQuery、······,每个子类都有它自己的作用(也可以说成是适用场景),比方说使用MatchAllDocsQuery可以查询索引目录中的所有文档(即查询全部),使用TermQuery可以实现精确查询,······。下面,我就来介绍这一个个子类,知道了每个子类的作用后,你就知道它们应该在什么时候使用了。
查询全部
使用MatchAllDocsQuery可以查询索引目录中的所有文档,代码的具体实现请参见如下testMatchAllDocsQuery方法。
package com.meimeixia.lucene;import java.nio.file.Paths;import org.apache.lucene.document.Document;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.MatchAllDocsQuery;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.junit.Test;/** * 索引维护 * 添加:入门程序讲过了 * 删除 * 修改 * 查询:入门程序讲过了,介绍的是精准查询 * @author liayun * */public class LuceneManager2 {// 获取IndexSearcher对象public IndexSearcher getIndexSearcher() throws Exception {// 第一步:创建一个Directory对象,也就是索引库存放的位置Directory directory = FSDirectory.open(Paths.get("D:\\temp\\index"));//磁盘(硬盘)上的索引库// 第二步:创建一个IndexReader对象,需要指定Directory对象IndexReader indexReader = DirectoryReader.open(directory);// 第三步:创建一个IndexSearcher对象,需要指定IndexReader对象return new IndexSearcher(indexReader);}// 执行查询的结果(或者渲染结果)public void printResult(IndexSearcher indexSearcher, Query query) throws Exception {// 第五步:执行查询TopDocs topDocs = indexSearcher.search(query, 10); // 如果文档很多的话,这里只返回头十个文档// 第六步:返回查询结果,即遍历查询结果并输出ScoreDoc[] scoreDocs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {int doc = scoreDoc.doc; // 获取到文档IDDocument document = indexSearcher.doc(doc);// 文件名称String fileName = document.get("fileName");System.out.println(fileName);// 文件内容String fileContent = document.get("fileContent");System.out.println(fileContent);// 文件路径String fileSize = document.get("fileSize");System.out.println(fileSize);// 文件大小String filePath = document.get("filePath");System.out.println(filePath);System.out.println("---------------------");}}// 查询所有(MatchAllDocsQuery)@Testpublic void testMatchAllDocsQuery() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();Query query = new MatchAllDocsQuery();System.out.println(query); // 其实MatchAllDocsQuery这个子类帮我们构建了里面的查询语法,打印出的查询语法为*:*,其中第一个*是域名,第二个*是值printResult(indexSearcher, query);// 关闭资源,即关闭IndexReaderindexSearcher.getIndexReader().close();}}
温馨提示:其实MatchAllDocsQuery这个子类帮我们构建了里面的查询语法。如果打印Query查询对象,那么你将会发现打印出的查询语法为*:*,其中第一个*是域名,第二个*是值,正如下图所示。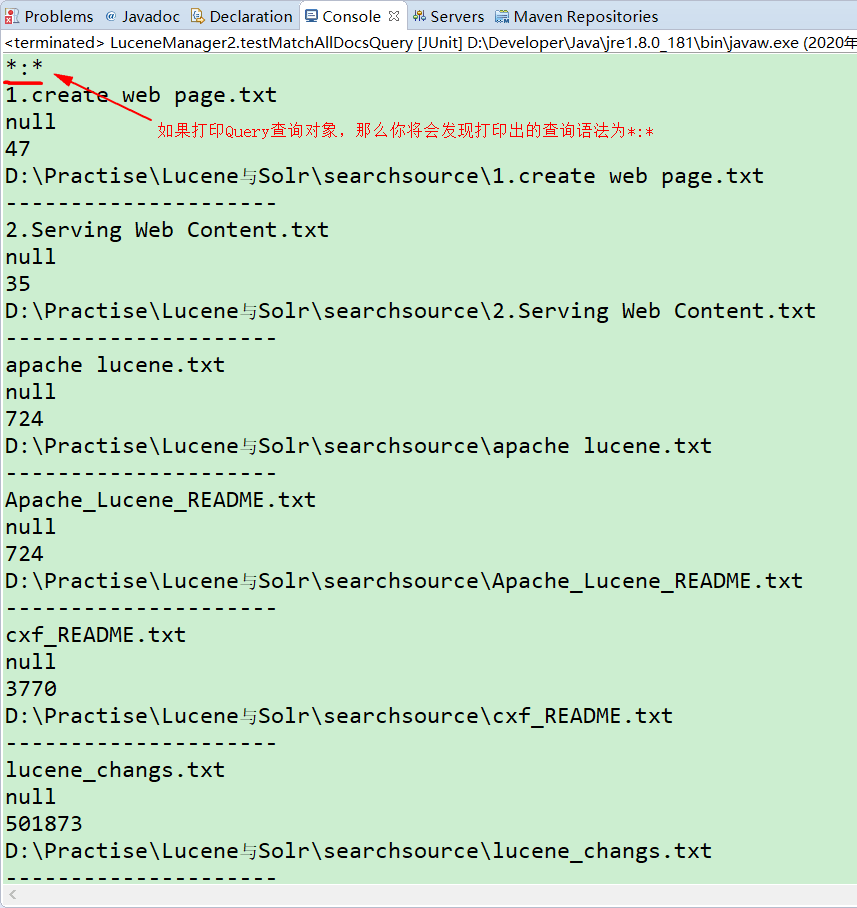
精确查询
使用TermQuery来查询,也叫项查询,也叫精准查询,在《Lucene快速入门第二讲——首次使用Lucene,开不开心!》这一讲中,我就已经使用TermQuery来查询过,故在此并不过多赘述。但有一点,我还得说一下,在项查询时,由于TermQuery不使用分析器,所以建议匹配不分词的Field域查询,比如订单号、分类ID号等。
数值指定范围查询
在更老版本的Lucene中,使用NumericRangeQuery可以根据数值范围来查询,代码的具体实现请参见如下testNumericRangeQuery方法。
package com.meimeixia.lucene;import java.nio.file.Paths;import org.apache.lucene.document.Document;import org.apache.lucene.document.LongPoint;import org.apache.lucene.index.DirectoryReader;import org.apache.lucene.index.IndexReader;import org.apache.lucene.search.IndexSearcher;import org.apache.lucene.search.MatchAllDocsQuery;import org.apache.lucene.search.Query;import org.apache.lucene.search.ScoreDoc;import org.apache.lucene.search.TopDocs;import org.apache.lucene.store.Directory;import org.apache.lucene.store.FSDirectory;import org.junit.Test;/** * 索引维护 * 添加:入门程序讲过了 * 删除 * 修改 * 查询:入门程序讲过了,介绍的是精准查询 * @author liayun * */public class LuceneManager2 {// 获取IndexSearcher对象public IndexSearcher getIndexSearcher() throws Exception {// 第一步:创建一个Directory对象,也就是索引库存放的位置Directory directory = FSDirectory.open(Paths.get("D:\\temp\\index"));//磁盘(硬盘)上的索引库// 第二步:创建一个IndexReader对象,需要指定Directory对象IndexReader indexReader = DirectoryReader.open(directory);// 第三步:创建一个IndexSearcher对象,需要指定IndexReader对象return new IndexSearcher(indexReader);}// 执行查询的结果(或者渲染结果)public void printResult(IndexSearcher indexSearcher, Query query) throws Exception {// 第五步:执行查询TopDocs topDocs = indexSearcher.search(query, 10); // 如果文档很多的话,这里只返回头十个文档// 第六步:返回查询结果,即遍历查询结果并输出ScoreDoc[] scoreDocs = topDocs.scoreDocs;for (ScoreDoc scoreDoc : scoreDocs) {int doc = scoreDoc.doc; // 获取到文档IDDocument document = indexSearcher.doc(doc);// 文件名称String fileName = document.get("fileName");System.out.println(fileName);// 文件内容String fileContent = document.get("fileContent");System.out.println(fileContent);// 文件路径String fileSize = document.get("fileSize");System.out.println(fileSize);// 文件大小String filePath = document.get("filePath");System.out.println(filePath);System.out.println("---------------------");}}// 查询所有(MatchAllDocsQuery)@Testpublic void testMatchAllDocsQuery() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();Query query = new MatchAllDocsQuery();System.out.println(query); // 其实MatchAllDocsQuery这个子类帮我们构建了里面的查询语法,打印出的查询语法为*:*,其中第一个*是域名,第二个*是值printResult(indexSearcher, query);// 关闭资源,即关闭IndexReaderindexSearcher.getIndexReader().close();}// 根据数值指定范围查询(NumericRangeQuery)@Testpublic void testNumericRangeQuery() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();/* * newLongRange方法中一系列参数的意思 * 1. 第一个参数:域名 * 2. 第二个参数:最小值 * 3. 第三个参数:最大值 * 4. 第四个参数:是否包含最小值 * 5. 第五个参数:是否包含最小大值 */Query query = NumericRangeQuery.newLongRange("fileSize", 47L, 200L, false, true);System.out.println(query); // 其实NumericRangeQuery这个子类帮我们构建了里面的查询语法,打印出的查询语法为fileSize:{47 TO 200]printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}}
但是在新版本的Lucene(例如本系列教程所使用的Lucene 8.4.0这个版本)中,数值指定范围查询都使用IntPoint/LongPoint/DoublePoint了,原来的NumericRangeQuery被废弃了。所以,你要是想实现以上的数值指定范围查询,即查询文件大小范围为[47字节(包括), 200字节(也包括)]的文档,testNumericRangeQuery方法就得改写成下面这样了。
// 根据数值指定范围查询@Testpublic void testNumericRangeQuery() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 查询文件大小范围为[47字节(包括), 200字节(也包括)]的文档Query query = LongPoint.newRangeQuery("fileSize", 47L, 200L);System.out.println(query); // 此时,打印出的查询语法为fileSize:[47 TO 200]printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}
你想,是不是还有这样的需求:我就只想查询文件大小为47字节和82字节的两个文件,要实现这样的数值精确查询,代码该如何写呢?此时,就得使用LongPoint类的newSetQuery方法。
// 根据数值指定范围查询@Testpublic void testNumericRangeQuery() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 数值精确查询,例如查询文件大小为47字节和82字节的两个文件Query query = LongPoint.newSetQuery("fileSize", 47L, 82L); // 第二个参数传入的是不定参数System.out.println(query); // 此时,打印出的查询语法为fileSize:{47 82}printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}
LongPoint类的newSetQuery方法中的第二个参数除了可以传入不定参数之外,还能传入集合参数,所以以上的testNumericRangeQuery方法还能改写为下面这样子。
// 根据数值指定范围查询@Testpublic void testNumericRangeQuery() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 数值精确查询,例如查询文件大小为47字节和82字节的两个文件List<Long> list = new ArrayList<Long>();list.add(47L);list.add(82L);Query query = LongPoint.newSetQuery("fileSize", list); // 第二个参数传入的是集合参数System.out.println(query); // 此时,打印出的查询语法为fileSize:{47 82}printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}
组合条件查询
BooleanQuery也是实际开发过程中经常使用的一种Query,它其实是一个组合的Query,在使用时可以把各种Query对象添加进去并标明它们之间的逻辑关系。所有的Query都可以通过BooleanQuery组合起来。BooleanQuery本身来讲是一个布尔子句的容器,它提供了专门的API方法往其中添加子句,并标明它们之间的关系。
怎样使用BooleanQuery来组合查询条件呢?代码的具体实现请参见如下testBooleanQuery方法。
在编写以上方法时,大家可能不知道Occur.MUST、Occur.SHOULD是啥意思,所以,我还得对它们解释一下。
我最后说一嘴,其实BooleanQuery这个子类帮我们构建了里面的查询语法,如果打印BooleanQuery查询对象的话,那么你将有可能会发现打印出的查询语法是+fileName:apache (fileName:lucene)^2.0这样子的。你肯定对Lucene中这样的查询语法感到陌生,但没关系,因为下面我就会介绍到Lucene中的查询语法。
使用QueryParser查询
通过QueryParser也可以创建Query,QueryParser提供一个parse方法,此方法可以直接根据查询语法来查询。Query对象执行的查询语法可通过System.out.println(query);语句打印出来。
使用QueryParser来查询时,需要使用到分析器。强烈建议创建索引时使用的分析器和查询索引时使用的分析器一致。而且,在使用QueryParser查询时,需要加入QueryParser依赖的jar包,即lucene-queryparser-8.4.0.jar。
下面咱们就使用QueryParser来查的试一下,也顺便看看Lucene中的查询语法。
查询全部
还记得使用Query抽象类的子类查询索引目录中的所有文档时,所打印出来的*:*查询语法吗?没错,查询索引目录中的所有文档时,所使用的查询语法就是它,代码的具体实现请参见如下testQueryParser方法。
// 条件解析的对象查询@Testpublic void testQueryParser() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 参数一:默认查询的域// 参数二:查询的时候采用的分析器QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());// *:*,域:值Query query = queryParser.parse("*:*"); // 查询所有printResult(indexSearcher, query);//关闭资源indexSearcher.getIndexReader().close();}
精确查询
精确查询所使用的是最基础的查询语法,即关键词查询,语法为域名:搜索的关键字,例如fileContent:apache。如果你想查询文件名中包含apache的文档,那么代码可能就应该这样写了。
// 条件解析的对象查询@Testpublic void testQueryParser() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 参数一:默认查询的域// 参数二:查询的时候采用的分析器QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());// *:*,域:值// Query query = queryParser.parse("*:*"); // 查询所有Query query = queryParser.parse("apache"); // 缺域,会使用默认的域,即文件名称printResult(indexSearcher, query);//关闭资源indexSearcher.getIndexReader().close();}
如果QueryParser类的parse方法中传入的不是一个个单词,而是一句话,例如java is apache,那么查询出来的会是什么东东呢?若parse方法中传入的是一句话,并不是某一个单词,则直接把这句话作为一个整体,而且还要经过IK分词器的拆分,它拆完之后,就会发现拆成java和apache了,也就是说最后文件名字当中有java或者apache的文档都得查询出来。
// 条件解析的对象查询@Testpublic void testQueryParser() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 参数一:默认查询的域// 参数二:查询的时候采用的分析器QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());// *:*,域:值// Query query = queryParser.parse("*:*"); // 查询所有// Query query = queryParser.parse("apache"); // 缺域,会使用默认的域,即文件名称Query query = queryParser.parse("java is apache"); // 有可能parse方法中传入的是一句话,而并不是某一个单词,这时,是直接把这句话作为一个整体,// 而且,还要经过IK分词器的拆分,它拆完之后,就会发现拆成java和apache了,// 也就是说最后文件名字当中有java或者apache的文档都得查询出来printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}
万一咱不想使用默认的域(即文件名称),而是想使用其他的域,例如文件内容。试想,是不是有这样的需求:查询文件内容(fileContent)中有apache关键字的文档。要想解决这样的需求,代码就应该这样像下面这样写了。
// 条件解析的对象查询@Testpublic void testQueryParser() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 参数一:默认查询的域// 参数二:查询的时候采用的分析器QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());// *:*,域:值// Query query = queryParser.parse("*:*"); // 查询所有// Query query = queryParser.parse("apache"); // 缺域,会使用默认的域,即文件名称Query query = queryParser.parse("fileContent:apache"); // 查询文件内容(fileContent)中有apache关键字的文档printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}
数值指定范围查询
还记得使用Query抽象类的子类实现数值指定范围查询时,所打印出来的fileSize:[47 TO 200]查询语法吗?没错,数值指定范围查询所使用的语法就是它,即域名:[最小值 TO 最大值]。
但是有一点需要我们引起注意,在Lucene中支持数值类型,不支持字符串类型。所以,运行以下testQueryParser方法,并不能查询出来什么。
// 条件解析的对象查询@Testpublic void testQueryParser() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 参数一:默认查询的域// 参数二:查询的时候采用的分析器QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());Query query = queryParser.parse("fileSize:[47 TO 200]"); // 查不了,查不出来printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}
但在Solr中支持字符串类型,所以这得等咱们学到Solr了,再来看看。
组合条件查询
组合查询条件时,有很多种组合方式,我也不能都全部介绍到,所以,只介绍如下四种组合方式。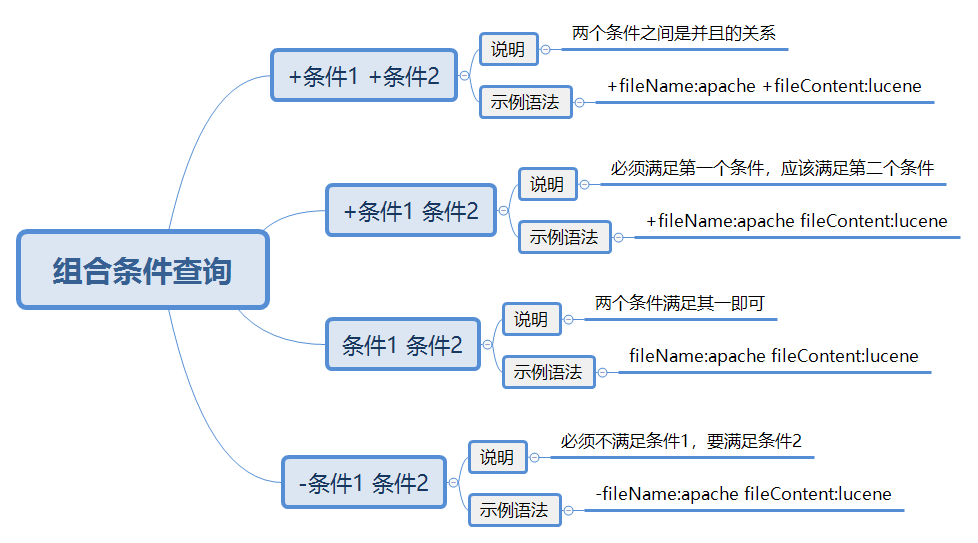
语法中的+、-、空格到底是啥意思啊?如果你还记得Occur.MUST、Occur.SHOULD是什么意思的话,那么你就可以比照着Occur.MUST、Occur.SHOULD来猜它们的意思了。
知道了以上组合条件查询的语法之后,不妨编写如下一个方法来测试一下。
// 条件解析的对象查询@Testpublic void testQueryParser() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 参数一:默认查询的域// 参数二:查询的时候采用的分析器QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());Query query = queryParser.parse("+fileName:apache -fileContent:lucene");printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}
+fileName:apache -fileContent:lucene语法的意思,想必你应该知道了吧!就是查询那些文件名中包含apache,文件内容不包含lucene的文档。
当然了,你也可以使用AND、OR以及NOT等逻辑符号来连接查询条件,例如,要想查询那些文件名中包含apache,而且文件内容中包含lucene的文档,代码就应该写成下面这样。
// 条件解析的对象查询@Testpublic void testQueryParser() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 参数一:默认查询的域// 参数二:查询的时候采用的分析器QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());Query query = queryParser.parse("fileName:apache AND fileContent:lucene");printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}
又想要查询那些或者文件名中包含apache,或者文件内容中包含lucene的文档,代码又应该怎么写呢?
// 条件解析的对象查询@Testpublic void testQueryParser() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();// 参数一:默认查询的域// 参数二:查询的时候采用的分析器QueryParser queryParser = new QueryParser("fileName", new IKAnalyzer());Query query = queryParser.parse("fileName:apache OR fileContent:lucene");printResult(indexSearcher, query);// 关闭资源indexSearcher.getIndexReader().close();}
细心的同学可能发现了,在上面创建QueryParser对象时,只指定了一个默认搜索域。其实,是可以指定多个默认搜索域的,代码的具体实现请参见如下testMultiFieldQueryParser方法。
// 条件解析的对象查询,设置多个默认域@Testpublic void testMultiFieldQueryParser() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();String[] fields = { "fileName", "fileContent"};// 参数一:默认查询的域,怎样才能设置多个呢?// 参数二:查询的时候采用的分析器MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer());Query query = queryParser.parse("fileName:apache AND fileName:lucene");printResult(indexSearcher, query);//关闭资源indexSearcher.getIndexReader().close();}
fileName:apache AND fileName:lucene语法的意思,想必你现在应该知道了吧!就是查询那些文件名中既包含apache,又包含lucene的文档。
如果此时MultiFieldQueryParser类的parse方法中传入的不是一个个单词,而是一句话,例如lucene is apache,那么查询出来的会是什么东东呢?
// 条件解析的对象查询,设置多个默认域@Testpublic void testMultiFieldQueryParser() throws Exception {IndexSearcher indexSearcher = getIndexSearcher();String[] fields = { "fileName", "fileContent"};// 参数一:默认查询的域,怎样才能设置多个呢?// 参数二:查询的时候采用的分析器MultiFieldQueryParser queryParser = new MultiFieldQueryParser(fields, new IKAnalyzer());// Query query = queryParser.parse("fileName:apache AND fileName:lucene");Query query = queryParser.parse("lucene is apache"); // 这儿查的可就多了去了printResult(indexSearcher, query);//关闭资源indexSearcher.getIndexReader().close();}
若parse方法中传入的是一句话,并不是某一个单词,则直接把这句话作为一个整体,而且还要经过IK分词器的拆分,它拆完之后,就会发现拆成lucene和apache了。而且,如果打印Query查询对象,那么你将会发现打印出的查询语法为(fileName:lucene fileContent:lucene) (fileName:apache fileContent:apache),我觉得这个语法还是蛮复杂的,可以想见查询出的文档是很多的。
至此,关于Lucene的学习,就告一段落了,哈哈哈,总共写了四篇文章,如果你觉得写的不错的话,还请点赞,也希望大家对文章中的不足之处提出自己的建议。


































还没有评论,来说两句吧...