SVM4种核函数在简单数据集下的效果对比
小彩笔的学习笔记,时间匆忙只贴代码
import numpy as npimport matplotlib.pyplot as pltfrom matplotlib.colors import ListedColormapfrom sklearn import svm#from sklearn.svm import SVC 两者都可以from sklearn.datasets import make_circles, make_moons, make_blobs,make_classificationn_samples = 100datasets = [make_moons(n_samples=n_samples, noise=0.2, random_state=0),make_circles(n_samples=n_samples, noise=0.2, factor=0.5, random_state=1),make_blobs(n_samples=n_samples, centers=2, random_state=5),#分簇的数据集make_classification(n_samples=n_samples,n_features = 2,n_informative=2,n_redundant=0, random_state=5)#n_features:特征数,n_informative:带信息的特征数,n_redundant:不带信息的特征数]Kernel = ["linear","poly","rbf","sigmoid"]#四个数据集分别是什么样子呢?for X,Y in datasets:plt.figure(figsize=(5,4))plt.scatter(X[:,0],X[:,1],c=Y,s=50,cmap="rainbow")
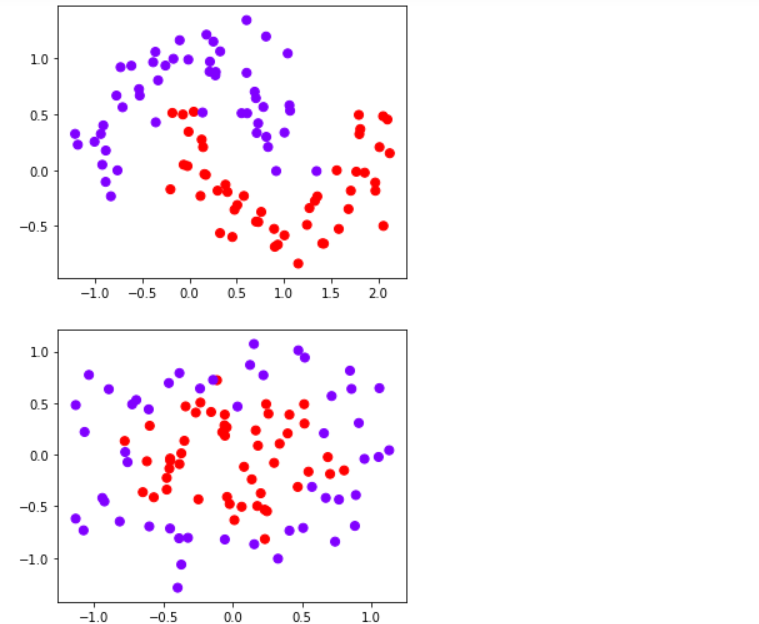
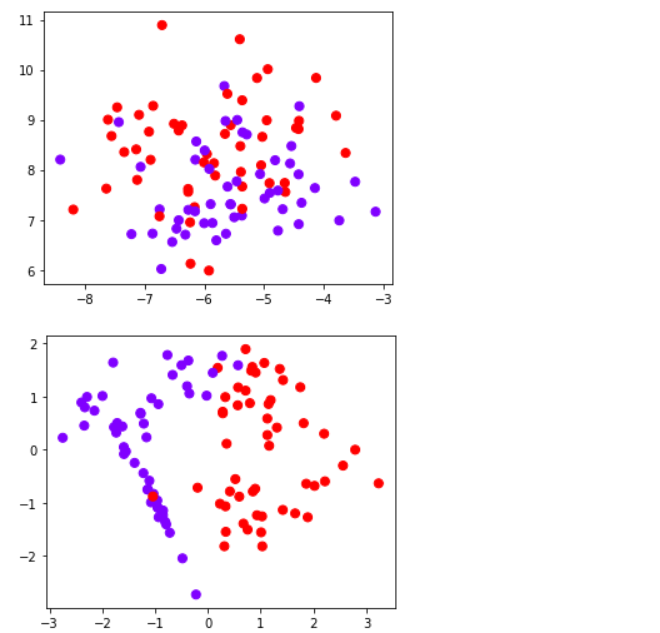
nrows=len(datasets)ncols=len(Kernel) + 1fig, axes = plt.subplots(nrows, ncols,figsize=(20,16))

nrows=len(datasets)ncols=len(Kernel) + 1fig, axes = plt.subplots(nrows, ncols,figsize=(20,16))#第一层循环:在不同的数据集中循环for ds_cnt, (X,Y) in enumerate(datasets):#在图像中的第一列,放置原数据的分布ax = axes[ds_cnt, 0]if ds_cnt == 0:ax.set_title("Input data")ax.scatter(X[:, 0], X[:, 1], c=Y, zorder=10, cmap=plt.cm.Paired,edgecolors='k')ax.set_xticks(())ax.set_yticks(())#第二层循环:在不同的核函数中循环#从图像的第二列开始,一个个填充分类结果for est_idx, kernel in enumerate(Kernel):#定义子图位置ax = axes[ds_cnt, est_idx + 1]#建模clf = svm.SVC(kernel=kernel, gamma=2).fit(X, Y)score = clf.score(X, Y)#绘制图像本身分布的散点图ax.scatter(X[:, 0], X[:, 1], c=Y,zorder=10,cmap=plt.cm.Paired,edgecolors='k')#绘制支持向量ax.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=50,facecolors='none', zorder=10, edgecolors='k')# facecolors='none':透明的#绘制决策边界x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5#np.mgrid,合并了我们之前使用的np.linspace和np.meshgrid的用法#一次性使用最大值和最小值来生成网格#表示为[起始值:结束值:步长]#如果步长是复数,则其整数部分就是起始值和结束值之间创建的点的数量,并且结束值被包含在内XX, YY = np.mgrid[x_min:x_max:200j, y_min:y_max:200j]#np.c_,类似于np.vstack的功能Z = clf.decision_function(np.c_[XX.ravel(), YY.ravel()]).reshape(XX.shape)#填充等高线不同区域的颜色ax.pcolormesh(XX, YY, Z > 0, cmap=plt.cm.Paired)#绘制等高线ax.contour(XX, YY, Z, colors=['k', 'k', 'k'], linestyles=['--', '-', '--'],levels=[-1, 0, 1])#设定坐标轴为不显示ax.set_xticks(())ax.set_yticks(())#将标题放在第一行的顶上if ds_cnt == 0:ax.set_title(kernel)#为每张图添加分类的分数ax.text(0.95, 0.06, ('%.2f' % score).lstrip('0'), size=15, bbox=dict(boxstyle='round', alpha=0.8, facecolor='white')#为分数添加一个白色的格子作为底色, transform=ax.transAxes #确定文字所对应的坐标轴,就是ax子图的坐标轴本身, horizontalalignment='right' #位于坐标轴的什么方向)plt.tight_layout()plt.show()



























")


")




还没有评论,来说两句吧...