《EfficientDet:Scalable and Efficient Object Detection》论文笔记
代码地址:EfficientDet.Pytorch
1. 概述
导读:这篇文章的总体思想上借鉴了EfficientNet的设计思路:使用缩放的思想按照需求的网络性能缩放网络大小,在性能与网络大小上获取权衡,可以看作是EfficientNet在检测领域的延伸。针对与检测领域这篇文章提出了两个改进的地方:
1)提出了BiFPN的特征融合结构,使用加权特征融合(特征的权值是可以学习的)的方式替换了原有FPN同等权值融合的方式,并且借鉴了ResNet中跳跃连接与多次多方向连接,极大增强特征的表达能力;
2)统一化的方式缩放网络中的分辨率、网络深度宽度方式获取不同的性能表现。
从文章的结果来说在性能与网络大小上获得了不错的效果,达到了sota。
文章的网络结构与其它典型检测网络的性能对比:
2. 方法设计
2.1 网络结构

2.2 BIFPN
在BiFPN结构中的两个要点是:高效多方向的跨尺度连接与加权特征融合方式,下面的内容也是按照这样的思路来进行分解的。
2.2.1 FPN特征融合问题描述
在于FPN特征融合的问题中使用 P i n = ( P l 1 i n , P l 2 i n , … ) P^{in}=(P_{l1}^{in},P_{l2}^{in},\dots) Pin=(Pl1in,Pl2in,…),其中 P l i i n P_{li}^{in} Pliin分别代表在 i i i个层次的特征,对应的 s t r i d e = 2 i stride=2^i stride=2i。则经过FPN的输出的可以描述 P o u t = f ( P i n ) P^{out}=f(P^{in}) Pout=f(Pin),而对应的转换部分可以描述为: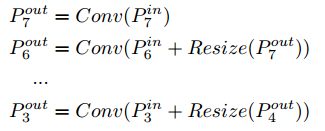
2.2.2 跨尺度的连接
在这篇文章之前已经有了很多对于FPN的改进工作,改进之后的结构见下图2所示:
上图中的这些结构的实际性能见下表所示:
可以看出PANet的结果是优于FPN与NAS-FPN的,但是它需要占据大量的参数与计算量,(文章提出的BiFPN也是参考了PANet结构来对其进行改进的)对此文章对于跨尺度的连接提出了几点优化:
- 1)移除那些输入只有一个的节点,之所以这样做是因为文章认为只有一个输入的节点对于特征融合的贡献度是比较低的,因而可以将其删掉,这样得到的改进结构见图2中的e图;
- 2)在同一个层次上使用shortcut连接的方式连接前后的特征,这样在引入更多特征的情况下不会带来额外的参数与计算量,得到的结构见图2中的f图;
- 3)上面得到的改进结构(从上到下再从下到上算是一个单元)是可以重复的,这样通过级联的形式来提取特征,从而增强backbone的特征表达,文中提到像这样的重叠操作是以2为初始的,后面根据网络大小的scale来累加,参见图3;
2.2.3 加权的特征融合方法
由于参与特征融合的特征是来自于不同分辨率的特征,因而这些不同分辨率特征融合的权重是一致的。基于此,文章的思想就是根据特征的重要性重新分配特征的权值分布,从而文章提出了如下解决方案:
- 1)无约束的融合方式: O = ∑ i w i ⋅ I i O=\sum_iw_i\cdot I_i O=∑iwi⋅Ii,这里不同的特征使用参数 w i w_i wi来确定,但是这样是无约束的加权方式,可能会导致训练的稳定;
- 2)基于Softmax的融合方式: O = ∑ i e w i ∑ j e w j ⋅ I i O=\sum_i\frac{e^{w_i}}{\sum_je^{w_j}}\cdot I_i O=∑i∑jewjewi⋅Ii,上面的方法没有对范围做约束,这里就引入softmax做归一化操作,但是这样会带来运算速度慢的问题;
- 3)快速归一化融合方式: O = ∑ i e w i ϵ + ∑ j w j ⋅ I i O=\sum_i\frac{ew_i}{\epsilon+\sum_jw_j}\cdot I_i O=∑iϵ+∑jwjewi⋅Ii,这里去掉了对应的指数运算,文中提到会快上30%;
下面是两种融合方式的对比:
对应的从上到下与从下到上的特征构建,参考下面的方式(以特征层级6举例):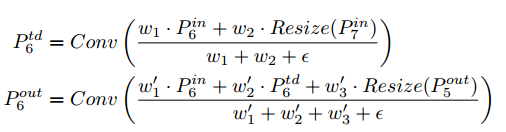
2.3 根据所需性能进行网络组合缩放
这里组合缩放是根据需要的网络性能在backbone、BiFPN、prediction network、input image resolution上进行的。缩放的范围是从 ϕ ∈ [ 0 , 6 ] \phi \in[0,6] ϕ∈[0,6](对于大于等于7的场景就装不下了,需要调整其它的参数设置了,文章对此也没有过多讨论)
- 1)backbone network:这部分参考EfficientNet-Bx的设置;
- 2)BiFPN network:在这个维度上会缩放参与融合的channel个数( W b i f p n W_{bifpn} Wbifpn)与这个网络重叠的次数( D b i f p n D_{bifpn} Dbifpn),则他们的缩放的关系为:
W b i f p n = 64 ∗ 1.3 5 ϕ , D b i f p n = 2 + ϕ W_{bifpn}=64*1.35^{\phi},D_{bifpn}=2+\phi Wbifpn=64∗1.35ϕ,Dbifpn=2+ϕ - 3)Box/class prediction network:这里根据缩放的力度适当增加参与预测的卷积层数:
D b o x = D c l a s s = 3 + ⌊ ϕ / 3 ⌋ D_{box}=D_{class}=3+\lfloor \phi/3\rfloor Dbox=Dclass=3+⌊ϕ/3⌋ - 4)Input image resolution:输入图像的尺寸关系为:
R i n p u t = 512 + ϕ ⋅ 128 R_{input}=512+\phi \cdot 128 Rinput=512+ϕ⋅128
下面表1展示了上面的几个维度缩放的对应表:
3. 实验结果
性能比较:


































还没有评论,来说两句吧...