pytorch学习笔记
一:优化器的使用
# 只为两个全连接层设置较大的学习率,其余层的学习率较小special_layers = nn.ModuleList([net.classifier[0], net.classifier[3]])special_layers_params = list(map(id, special_layers.parameters()))base_params = filter(lambda p: id(p) not in special_layers_params,net.parameters())optimizer = t.optim.SGD([{ 'params': base_params},{ 'params': special_layers.parameters(), 'lr': 0.01}], lr=0.001 )optimizer

对于如何调整学习率,主要有两种做法。一种是修改optimizer.param_groups中对应的学习率,另一种是更简单也是较为推荐的做法——新建优化器,由于optimizer十分轻量级,构建开销很小,故而可以构建新的optimizer。但是后者对于使用动量的优化器(如Adam),会丢失动量等状态信息,可能会造成损失函数的收敛出现震荡等情况。
# 方法1: 调整学习率,新建一个optimizerold_lr = 0.1optimizer1 =optim.SGD([{ 'params': net.features.parameters()},{ 'params': net.classifier.parameters(), 'lr': old_lr*0.1}], lr=1e-5)optimizer1
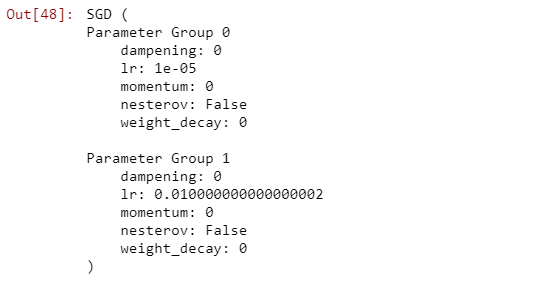
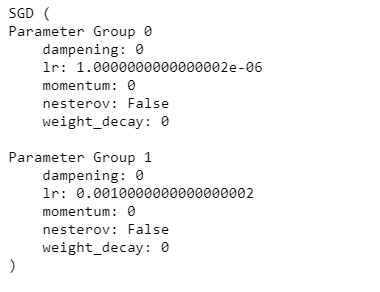
# 方法2: 调整学习率, 手动decay, 保存动量for param_group in optimizer.param_groups:param_group['lr'] *= 0.1 # 学习率为之前的0.1倍optimizer
二:GPU上并行计算
nn.parallel.data_parallel(module, inputs, device_ids=None, output_device=None, dim=0, module_kwargs=None)class torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
可见二者的参数十分相似,通过device_ids参数可以指定在哪些GPU上进行优化,output_device指定输出到哪个GPU上。唯一的不同就在于前者直接利用多GPU并行计算得出结果,而后者则返回一个新的module,能够自动在多GPU上进行并行加速。
# method 1new_net = nn.DataParallel(net, device_ids=[0, 1])output = new_net(input)# method 2output = nn.parallel.data_parallel(new_net, input, device_ids=[0, 1])
DataParallel并行的方式,是将输入一个batch的数据均分成多份,分别送到对应的GPU进行计算,各个GPU得到的梯度累加。与Module相关的所有数据也都会以浅复制的方式复制多份,在此需要注意,在module中属性应该是只读的。
参考一


































还没有评论,来说两句吧...