tensorflow与深度学习之一
目录
- tensorflow是什么
- tensorflow计算模型-计算图
2.1计算图的概念
2.2计算图的使用 - tensorflow数据模型-张量
3.1张量的概念
3.2张量的使用 - tensorflow运行模型-会话
- tensorflow实现神经网络
- 第一个CNN网络
6.1CNN算法原理
6.2CNN是干什么的
6.3tensorflow实现CNN
6.4CNN模型发展 - 第一个RNN网络
7.1RNN算法原理
7.2RNN是干什么的
7.3tensorflow实现RNN
7.4RNN模型发展及变体
1.tensorflow是什么
TensorFlow 究竟是什么,它为什么在 DNN 研究人员和工程师中如此受欢迎?
TensorFlow 是一个强大的库,用于执行大规模的数值计算,如矩阵乘法或自动微分。这两个计算是实现和训练 DNN 所必需的。TensorFlow 有一个高级机器学习 API(tf.contrib.learn),可以更容易地配置、训练和评估大量的机器学习模型。
开源深度学习库 TensorFlow 允许将深度神经网络的计算部署到任意数量的 CPU 或 GPU 的服务器、PC 或移动设备上,且只利用一个 TensorFlow API。 TensorFlow 与其他深度学习库的,如 Torch、Theano、Caffe 和 MxNet,区别在哪里呢?包括 TensorFlow 在内的大多数深度学习库能够自动求导、开源、支持多种 CPU/GPU、拥有预训练模型,并支持常用的NN架构,如递归神经网络(RNN)、卷积神经网络(CNN)和深度置信网络(DBN)。
TensorFlow 则还有更多的特点,如下:
- TensorFlow 在后端使用 C/C++,这使得计算速度更快
- 支持所有流行语言,如 Python、C++、Java、R和Go。
- 可以在多种平台上工作,甚至是移动平台和分布式平台。
- 它受到所有云服务(AWS、Google和Azure)的支持。
- Keras——高级神经网络 API,已经与 TensorFlow 整合。
- 与 Torch/Theano 比较,TensorFlow 拥有更好的计算图表可视化。
- 允许模型部署到工业生产中,并且容易使用。
- 有非常好的社区支持。
- TensorFlow 不仅仅是一个软件库,它是一套包括 TensorFlow,TensorBoard 和 TensorServing 的软件。
- TensorFlow 成为最受欢迎的深度学习库,原因如下:
2.tensorflow计算模型-计算图
2.1计算图的概念
计算图是Tensorflow中最基本的一个概念,Tensorflow中所有的计算都会转为计算图上的节点。Tensorflow由两个单词组成:tensor——张量,可以理解为多维数组(0-d tensor:标量,1-d tensor:向量,2-d tensor:矩阵),它表明了数据结构;flow——流,它体现了计算模型(表达张量之间通过计算相互转换的过程)。tensorflow是一个通过计算图的形式来表述计算的编程系统。Tensorflow中的每个计算都是计算图上的节点,而节点之间的边描述了计算之间的依赖关系。

如图:每一个节点都是一个运算,而每一条边代表了计算之间的依赖关系——如果一个运算的输入依赖于另一个运算的输出,那么这两个运算有依赖关系。
2.2计算图的使用
Tensorflow程序分为两个阶段:1. 定义计算图中所有的计算;2. 执行计算
#定义阶段import tensorflow as tfa = tf.constant([1.0, 2.0], name='a')b = tf.constant([2.0, 3.0], name='b')result = a + b
Tensorflow会自动将定义的计算转为计算图上的节点,并且系统会自动维护一个默认的计算图,可通过tf.get_default_graph函数来获取当前默认的计算图。
#通过a.graph可以查看张量所属的计算图。因为我们没指定,所以是默认计算图print(a.graph is tf.get_default_graph)#输出为:True
除了默认的计算图,Tensorflow可以通过tf.Graph函数来生成新的计算图。
注:不同计算图上的张量和运算都不会共享。
import tensorflow as tfg1 = tf.Graph()with g1.as_default():#在计算图g1中定义变量 'v' ,并设置初始值为 0v = tf.get_variable('v', initializer=tf.zeros_initializer()(shape=[1])) #注:因版本更新,这里书本上有误g2 = tf.Graph()with g2.as_default():#在计算图g2中定义变量 'v' ,并设置初始值为 1v = tf.get_variable('v',initializer=tf.ones_initializer()(shape=[1])) #同上# 在计算图 g1 中读取变量'v'的取值with tf.Session(graph=g1) as sess:tf.global_variables_initializer().run()with tf.variable_scope("", reuse=True):print(sess.run(tf.get_variable("v")))#输出为 0# 在计算图 g2 中读取变量'v'的取值with tf.Session(graph=g2) as sess:tf.global_variables_initializer().run()with tf.variable_scope("", reuse=True):print(sess.run(tf.get_variable("v")))#输出为 1
可以看到,运行不同的计算图时,变量v的值也是不一样的。Tensorflow的计算图不仅仅可以用来隔离张量和计算,它还提供了管理张量和计算机制。
# tf.Graph.device 函数可以指定运行计算的设备g = tf.Graph()with g.device('/gpu:0'):result = a + b
计算图可以有效整理Tensorflow程序中的资源(张量,变量等等)。比如,在一个计算图中,可以通过集合(collection)来管理不同类别的资源。通过tf.add_to_collection()函数可以将资源加入一个或多个集合中,然后通过tf.get_collection获取一个集合里面的所有资源。下图是最常用的几个自动维护的集合。
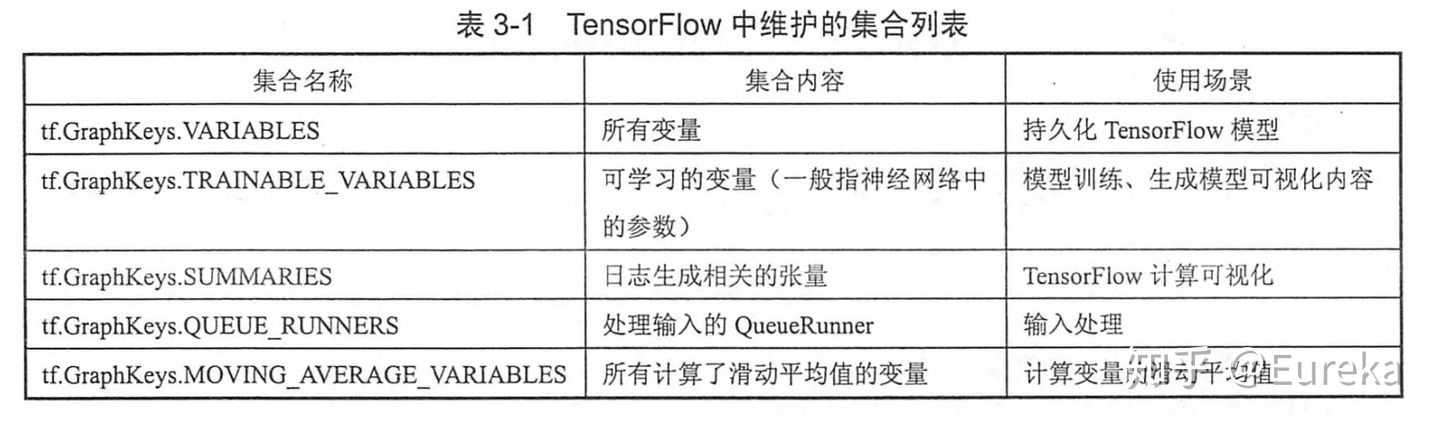
Tensorflow中的节点变量是可以被递归的更新的。我们所说的“训练”,也就是不停的计算一个图,获得图的计算结果,再根据结果的值调整节点变量的值,然后根据新的变量的值再重新计算图,如此重复,直到结果令人满意
总结:
从内部机制上来说,TF就是建立数据流图来进行数值计算。所以,当你使用TF来搭建模型时,其实主要涉及两个方面:根据模型建立计算图,然后送入数据运行计算图得到结果。计算图computational graph是TF中很重要的一个概念,其是由一系列节点(nodes)组成的图模型,每个节点对应的是TF的一个算子(operation)。每个算子会有输入与输出,并且输入和输出都是张量。所以我们使用TF的算子可以构建自己的深度学习模型,其背后的就是一个计算图。这个计算图是静态的,计算图每个节点接收什么样的张量和输出什么样的张量已经固定下来。要运行这个计算图,你需要开启一个会话(session),在session中这个计算图才可以真正运行。
3.tensorflow数据模型-张量
3.1 张量的概念
张量(tensor)可以简单理解为多维数组。其中零阶张量表示标量(scalar),也就是一个数;一阶张量为向量(vector),也就是一维数组;第n阶张量可以理解为一个n维数组。但是张量在Tensorflow中的实现并不是直接采用数组的形式,它只是对Tensorflow中运算结果的引用。在张量中并没有真正保存数字,它保存的是如何得到这些数字的计算过程。在tf的程序中,所有的数据都是通过张量的形式来表示。
import tensorflow as tf# tf.constant是一个计算,这个计算的结果为一个张量,保存在a中a = tf.constant([1.0, 2.0], name='a')b = tf.constant([2.0, 3.0], name='b')result = tf.add(a, b, name='add')print(result)#输出:Tensor("add:0", shape=(2,), dtype=float32)
从结果可以看出,Tensorflow计算结果不是一个具体数字,而是一个张量结构,这与Numpy中的数组不同。从中可以看出,一个张量中主要保存了三个属性:名字(name)、维度(shape)和类型(type)。其中名字不仅是唯一标志,而且给出了这个张量是如何计算出来的。
向量是一维的,而矩阵是二维的,对于张量其可以是任何维度的。一般情况下,你要懂得张量的两个属性:形状(shape)和秩(rank)。秩很好理解,就是有多少个维度;而形状是指的每个维度的大小。下面是常见的张量的形象图表示:
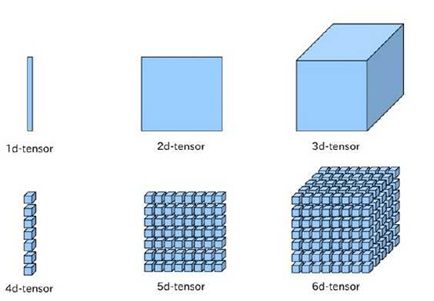
前面介绍了Tensorflow的计算都可以通过计算图的模型来建立,而计算图上的每一个节点代表了一个计算,计算的结果就保存在张量之中。因此张量和计算节图上节点所代表的计算结果是对应的。
张量可以通过’node:src_output’的形式命名,其中node为节点名称,src_output表示当前张量来自节点的第几个输出。shape=(2,)是张量的维度信息,这个说明result是一个一维数组,且数组长度是2。第三个是类型,每个张量都有唯一的类型,Tensorflow的计算类型必须相同,tf会对参与运算的所有张量进行类型检查,如果发现类型不一致就会报错
import tensorflow as tfa = tf.constant([1, 2], name='a')#改成a = tf.constant([1, 2], name='a',dtype=tf.float32)就不报错了b = tf.constant([2.0, 3.0], name='b')result = a + b#类型不匹配报错:#ValueError: Tensor conversion requested dtype int32 for Tensor with dtype float32:#'Tensor("b_1:0", shape=(2,), dtype=float32)'
Tensorflow支持14种数据类型:tf.float32, tf.float64, tf.int8, tf.int16, tf.int32, tf.in64, tf.uint8, tf.bool, tf.complex64, tf.complex128
TensorFlow,就是张量的流动。张量的流动是指保持计算节点不变,让数据进行流动。这样的设计是针对连接式的机器学习算法,比如逻辑斯底回归,神经网络等。连接式的机器学习算法可以把算法表达成一张图,张量从图中从前到后走一遍就完成了前向运算;而残差从后往前走一遍,就完成了后向传播。
Tensorflow中的运算(op)有很多很多种,最简单的当然就是加减乘除,它们的输入和输出都是tensor。
3.2 张量的使用
张量有两个作用:
- 对中间计算结果的引用,提高代码可读性
import tensorflow as tf
a = tf.constant([1.0, 2.0], name=”a”)
b = tf.constant([2.0, 3.0], name=”b”)
result = a + b
与
result=tf.constant([1.0, 2.0], name=”a”)+ tf.constant([2.0, 3.0], name=”b”)
a,b就是对常量生成这个结果的引用,这样就可以直接使用这两个变量而不用再重新生成常量,而且相比而言可读性更强,同时通过张量来存储中间结果,可以方便提取
- 当计算图构造完成后,张量可以用来计算结果。
虽然张量本身没有存储具体数字,但是会话run以后可以获得。
TensorFlow 支持以下三种类型的张量:
- 常量:常量是其值不能改变的张量。t_1 = tf.constant(4),它们在定义时就必须被赋值,而且值永远无法被改变。
变量:当一个量在会话中的值需要更新时,使用变量来表示。例如,在神经网络中,权重需要在训练期间更新,可以通过将权重声明为变量来实现。变量在使用前需要被显示初始化。另外需要注意的是,常量存储在计算图的定义中,每次加载图时都会加载相关变量。换句话说,它们是占用内存的。另一方面,变量又是分开存储的。它们可以存储在参数服务器上。
- w = tf.Variable(tf.random_normal([2,3],mean=1,stddev=2,dtype=tf.float32))
- 占位符:用于将值输入 TensorFlow 图中。它们可以和 feed_dict 一起使用来输入数据。在训练神经网络时,它们通常用于提供新的训练样本。在会话中运行计算图时,可以为占位符赋值。如果每轮迭代中选取的数据都要通过常量来表示,那么tensorflow的计算图将会太大。因为每生成一个常量,tensorflow都会在计算图中增加一个节点,一般来说,一个神经网络的训练过程会需要几百万甚至几亿轮的迭代,这样计算图就会非常大,而且利用率很低。有了占位符以后在构建一个计算图时不需要真正地输入数据。需要注意的是,占位符不包含任何数据,因此不需要初始化它们。tf.placeholder(dtype, shape=None, name=None)
4.tensorflow运行模型-会话
会话就是用来执行图形或部分图形的,图必须在会话(Session)里面启动,会话将图的操作分发到CPU、GPU等设备上执行。会话拥有并管理Tensorflow程序运行时的所有资源。所有计算完成之后需要关闭会话来帮助系统回收资源,否则就可能出现资源泄露的问题。Tensorflow中使用会话的模式一般有两种,第一种模式需要明确调用会话生成函数和关闭会话函数,这种模式的代码如下:
import tensorflow as tf# 创建一个会话。sess = tf.Session()# 使用这个创建好的会话来得到关心的运算结果。sess.run(result)# 其中result是运算结果,是一个张量#关闭会话使得本次运行中使用到的资源可以被释放。sess.close()使用这种模式时,在所有计算完成之后,需要明确调用Session.close函数来关闭会话并释放资源。然而,当程序因为异常而退出时,关闭会话的函数可能就不会被执行从而导致资源泄露。为了解决异常退出时资源释放的问题,Tensorflow可以通过Python的上下文管理器来使用会话。代码如下:import tensorflow as tf# 创建一个会话,并通过Python中的上下文管理器来管理这个会话。with tf.Session() as sess:# 使用创建好的会话来计算关心的结果。sess.run(result)# 不需要再调用“Session.close()”函数来关闭会话,# 当上下文退出时会话关闭和资源释放也自动完成了。
通过Python上下文管理器的机制,只要将所有的计算放在”with”的内部就可以。当上下文管理器退出时候会自动释放所有资源。这样既解决了因为异常退出时资源释放的问题,同时也解决了忘记调用Session.close函数而产生的资源泄露。
Tensorflow在计算时会自动生成一个默认的计算图,如果没有特殊指定,运算会自动加入这个计算图中。Tensorflow中的会话也有类似的机制,但Tensorflow不会自动生成默认的会话,而是需要手动指定。当默认的会话被指定之后可以通过tf.Tensor.eval函数来计算一个张量的取值。通过设定默认会话计算张量的取值代码如下:
import tensorflow as tfsess = tf.Session()with sess.as_default():print(result.eval)
以下代码也可以完成相同的功能。
sess = tf.Session()# 以下两个命令也可以完成相同的功能print(sess.run(result))print(result.eval(session=sess))
当python编辑环境是shell、IPython等交互式环境时,通过设置默认会话的方式来获取张亮的取值更方便。tf.InteractiveSession是tf在交互环境下直接构建默认会话的函数,它会自动将生成的会话注册成默认会话,用方法tensor.eval( ),operation.run( ) 代替sess.run( ),这样可避免用一个变量sess来持有会话。其中更多地使用 tensor.eval(),所有的表达式都可以看作是tensor。
sess = tf.InteractiveSession()a = tf.constant(5.0)b = tf.constant(6.0)c = a * bprint(c.eval())sess.close()
tf.InteractivesSession( )可以省去将产生的会话注册为默认会话的过程。以上无论哪种方式产生会话的方式都可以通过tf.ConfigProto进行参数配置,通过tf.ConfigProto可以配置类似并行的线程数,GPU分配策略,运算超时时间等参数。最常用的两个参数:
tf.Session(config=tf.ConfigProto(gpu_options=gpu_options,log_device_placement=True))
log_device_placement = True ,可以获取到 operations 和 Tensor 被指派到哪个设备(几号CPU或几号GPU)上运行,会在终端打印出各项操作是在哪个设备上运行的。
在tf中,通过命令 “with tf.device(‘/cpu:0’):”,允许手动设置操作运行的设备。如果手动设置的设备不存在或者不可用,就会导致tf程序等待或异常,为了防止这种情况,可以设置tf.ConfigProto()中参数allow_soft_placement=True,允许tf自动选择一个存在并且可用的设备来运行操作。
5.tensorflow实现神经网络
训练神经网络的过程分为三个步骤
- 定义神经网络的结构和前向传播的输出结果
- 定义损失函数以及选择反向传播的算法
生成会话(tf.session)并在训练集上反复运行反向传播算法
import tensorflow as tf
初始化两个变量
w1 = tf.Variable(tf.random_normal((2,3), stddev=1, seed=1))
w2 = tf.Variable(tf.random_normal((3,1), stddev=1, seed=1))输入的特征向量
x = tf.constant([[0.7, 0.9]])
前向传播
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)sess = tf.Session()
初始化全部变量
init_op = tf.global_variables_initializer()
sess.run(init_op)print(sess.run(y))
sess.close()输出:[[3.957578]]
变量和张量的关系:变量的声明函数是tf.Variable是一个运算,这个运算的结果是一个张量,所以变量只是一中特殊的张量
所有变量都会被自动加入到GraphKeys.VARIABLES这个集合中。通过tf.global_variables()函数可以拿到当前计算图上所有变量。
在构建机器学习模型时,可以通过变量声明函数中的trainable参数来区分需要优化的参数(神经网络参数)和其他参数(迭代参数)。如果变量声明为True,则这个变量加入到GraphKeys.TRAINABLE_VARIABLES集合。可以通过tf.trainable_variables函数得到所有需要优化的参数。tf中提供的神经网络优化算法将GraphKeys.TRAINABLE_VARIABLES中的变量作为默认的优化对象,
维度和类型也是变量的两个重要属性。其中变量的类型是不能变的。random_normal结果默认类型是tf.float32。而维度是可以变的,需要通过设置参数validate_shape=Fasle。
w1 = tf.Variable(tf.random_normal((2,3), stddev=1, seed=1), name='w1')w2 = tf.Variable(tf.random_normal((3,1), stddev=1, seed=1), name='w2')#会报错tf.assign(w1, w2)#成功执行tf.assign(w1, w2, validate_shape=False)
Tensorflow提供了placeholder机制用于提供输入数据。placeholder相当于定义了一个位置,这个位置中的数据在程序运行时再指定。在定义placeholder时,数据类型是要指定的。和其他张量一样,类型不可以改变。而维度信息可以根据提供的数据推导得出,所以无需给出。
import tensorflow as tfw1 = tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))#给出维度可以降低出错率x = tf.placeholder(tf.float32, shape=(1, 2), name='input')a = tf.matmul(x, w1)y = tf.matmul(a, w2)sess = tf.Session()init_go = tf.global_variables_initializer()sess.run(init_go)print(sess.run(y, feed_dict={x: [[0.7, 0.9]]})) #feed_dict是个字典#输出: [[3.957578]]训练神经网络时每次需要提供一个batch的训练样例。x = tf.placeholder(tf.float32, shape=(3, 2), name='input')a = tf.matmul(x, w1)y = tf.matmul(a, w2)sess = tf.Session()init_go = tf.global_variables_initializer()sess.run(init_go)#提供三个数据print(sess.run(y, feed_dict={x: [[0.7, 0.9], [0.1, 0.4], [0.5, 0.8]]}))#输出结果:#[[3.957578 ]#[1.1537654]#[3.1674924]]得到以batch前向传播结果之后,需要定义一个损失函数,通过反向传播来调整神经网络参数的取值来缩小差距。#使用sigmoid函数将y转换为0~1之间的数值,转换后y代表预测是正样本的概率y = tf.sigmoid(y)#定义损失函数来刻画预测值与真实值得差距,交叉熵# tf.clip_by_value(A,min,max)cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0))+ (1-y_)*tf.log(tf.clip_by_value(1-y, 1e-10, 1.0)))#学习率learning_rate = 0.001#定义反向传播算法来优化神经网络参数train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)Tensorflow提供的优化算法有10种,常用的有:tf.train.GradientDescentOptimizer, tf.train.AdamOptimizer, tf.train.MomentumOptimizer。定义反向传播之后,通过运行sess.run(train_step)就可以对所有在GraphKeys.TRAINABLE_VARIABLES集合中的变量来进行优化,使当前batch下损失函数更小。
完整代码:
import tensorflow as tffrom numpy.random import RandomState#定义训练数据batch的大小batch_size = 8#定义神经网络参数w1 =tf.Variable(tf.random_normal([2, 3], stddev=1, seed=1))w2 = tf.Variable(tf.random_normal([3, 1], stddev=1, seed=1))#在shape的一个维度上使用None可以方便使用不同的batch大小x = tf.placeholder(tf.float32, shape=(None, 2), name='x-input')y_ =tf.placeholder(tf.float32, shape=(None, 1), name='y-input')#前向传播a = tf.matmul(x, w1)y = tf.matmul(a, w2)#损失函数和反向传播y = tf.sigmoid(y)cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)) + (1-y_)*tf.log(tf.clip_by_value(1-y, 1e-10, 1.0)))train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)#随机生成一个模拟数据集rdm = RandomState(1)dataset_size = 128X = rdm.rand(dataset_size, 2)#定义规则来给出样本标签,x1+x2<1的样例都认为是正样本,其他为负,Y = [[int(x1 + x2 < 1)] for (x1, x2) in X]#创建一个会话来运行Tensorflow程序with tf.Session() as sess:init_go = tf.global_variables_initializer()#初始化变量sess.run(init_go)#训练之前的参数print('parameter w1 before train: ', sess.run(w1))print('parameter w2 before train: ', sess.run(w2))STEPS = 5000for i in range(STEPS):#每次迭代取batch_size个样本进行训练start = (i * batch_size) % dataset_sizeend = min(start+batch_size, dataset_size)#通过训练样本训练神经网络并更新参数sess.run(train_step, feed_dict={x: X[start:end], y_: Y[start:end]})if i % 1000 == 0:#每隔1000步计算所有数据集上的交叉熵并输出total_cross_entropy = sess.run(cross_entropy, feed_dict={x: X, y_: Y})print('After %d training_steps, cross entropy on all data is %g'%(i, total_cross_entropy))print('parameter w1 after train: ', sess.run(w1))print('parameter w2 after train: ', sess.run(w2))parameter w1 before train: [[-0.8113182 1.4845988 0.06532937][-2.4427042 0.0992484 0.5912243 ]]parameter w2 before train: [[-0.8113182 ][ 1.4845988 ][ 0.06532937]]After 0 training_steps, cross entropy on all data is 1.89805After 1000 training_steps, cross entropy on all data is 0.655075After 2000 training_steps, cross entropy on all data is 0.626172After 3000 training_steps, cross entropy on all data is 0.615096After 4000 training_steps, cross entropy on all data is 0.610309parameter w1 after train: [[ 0.02476983 0.56948674 1.6921941 ][-2.1977348 -0.23668921 1.1143895 ]]parameter w2 after train: [[-0.45544702][ 0.49110925][-0.98110336]]
6.第一个CNN网络
6.1CNN解决了什么问题
为什么要用卷积神经网络?
在图像领域,用传统的神经网络并不合适。我们知道,图像是由一个个像素点构成,每个像素点有三个通道,分别代表RGB颜色,那么,如果一个图像的尺寸是(28,28,1),即代表这个图像的是一个长宽均为28,channel为1的图像(channel也叫depth,此处1代表灰色图像)。如果使用全连接的网络结构,即,网络中的神经与与相邻层上的每个神经元均连接,那就意味着我们的网络有28 * 28 =784个神经元,hidden层采用了15个神经元,那么简单计算一下,我们需要的参数个数(w和b)就有:784*15+15+15*10+10个,这还只是两层,这个参数太多了,随便进行一次反向传播计算量都是巨大的,从计算资源和调参的角度都不建议用传统的神经网络。当神经网络的深度、节点数变大,会导致过拟合、参数过多等问题。
所以在 CNN 出现之前,图像对于人工智能来说是一个难题,有2个原因:
- 图像需要处理的数据量太大,导致成本很高,效率很低
- 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高
CNN 最擅长的就是图片的处理。它受到人类视觉神经系统的启发。
CNN 有2大特点:
- 能够有效的将大数据量的图片降维成小数据量
- 能够有效的保留图片特征,符合图片处理的原则
目前 CNN 已经得到了广泛的应用,比如:人脸识别、自动驾驶、美图秀秀、安防等很多领域。
CNN通过局部连接和权值共享将神经网络的参数和计算量降了下来,并且用类似视觉的方式保留了图像的特征,当图像做翻转,旋转或者变换位置时,它也能有效的识别出来是类似的图像。这使得CNN在计算机视觉领域大放异彩
局部感受野(局部连接,稀疏连接,局部感知):生物学中,视觉皮层的神经元是局部感知信息的,只响应某些特定区域的刺激;图像的空间联系中,局部的像素联系较为紧密,距离较远的像素相关性较弱。在卷积神经网络中,卷积核尺度远小于输入的维度,这样每个输出神经元仅与前一层特定局部区域内的神经元存在连接权重(即产生交互),这种特性称为稀疏交互。稀疏交互使得优化过程的时间复杂度减小几个数量级,过拟合情况也得到较好的改善。稀疏交互的物理意义是,通常图像、文本、语音等现实世界中的数据都具有局部的特征结构,我们可以先学习局部的特征,再将局部的特征组合起来形成更复杂和抽象的特征。
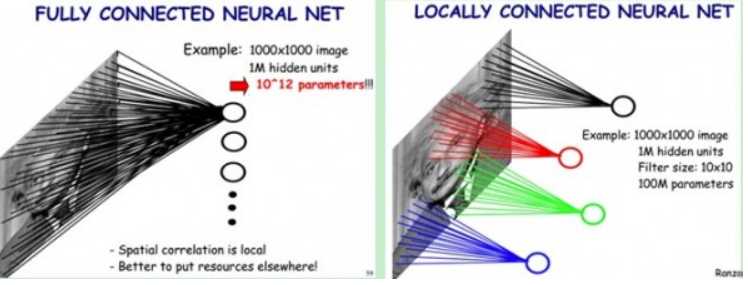
权值共享。参数共享是指在同一个模型的不同模块中使用相同的参数。隐含的原理是:图像的一部分的统计特性与其他部分是一样的。那么在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,都能使用同样的学习特征。全连接神经网络在计算每层的输出时,权值参数矩阵中的每个元素只作用于某个输入元素一次;而卷积神经网络的卷积核中的每一个元素将作用于每一次局部输入的特定位置上,根据参数共享的思想,我们只需要学习一组参数集合,而不需要针对每个位置的每个参数都进行优化,大大降低了模型的存储需求。参数共享的物理意义是使得卷积层具有平移不变性。假如图像中有一只猫,那么无论它出现在图像中任何位置,都应该将它识别为猫。也就是神经网络的输出对于平移变换来说应当是等变的。
所以回到刚才一开始的28*28的图像中来,如果我们用3*3的卷积核,那么我们的参数就只有9个,和图像大小没有关系。
6.2CNN算法原理
用CNN卷积神经网络识别图片,一般需要的步骤有:
- 卷积层初步提取特征
- 池化层提取主要特征
- 全连接层将各部分特征汇总
- 产生分类器,进行预测识别
1. 卷积层 ( Convolution Layer )
假设有一张5x5的图片,其中5的单位是像素(Pixel),每一个像素其实是由RGB三种颜色通道组成,颜色范围是0 ~ 255,如下图。
 RGB三通道
RGB三通道
为了简单起见,我单独抽出B这一通道来进行说明。
首先,卷积运算需要有一个卷积核,在图像处理中我们有时候又叫做算子,或者Filter。卷积核的结构一般可以看成是一个  的一个矩阵。比如我可以定义一个 的卷积核如下
的一个矩阵。比如我可以定义一个 的卷积核如下
我们让上面这个卷积核在图片蓝色通道上滑行,从左上角开始一行一行滑动,每次滑动步长为1,如下图所示。每一次滑动都会对应图片上的9个像素,让卷积核中的数字与图片中对应的像素值依次相乘,然后相加得到一个新数值,于是得到一个新的图片,如下图右侧绿色所示。
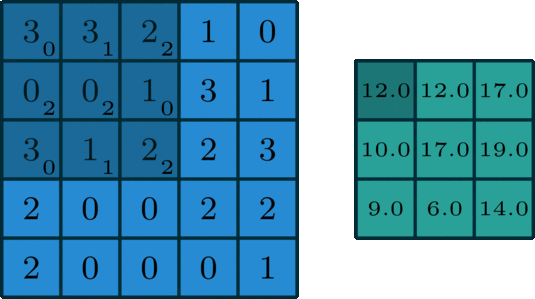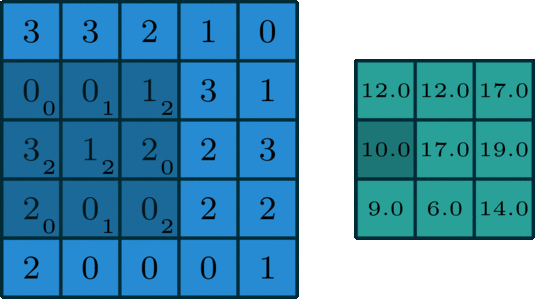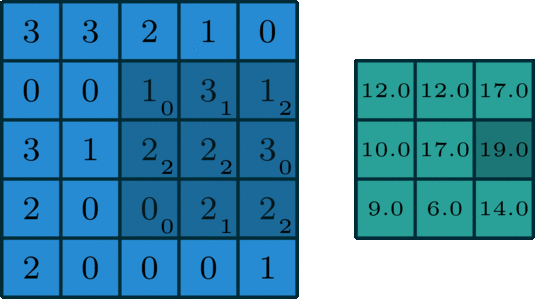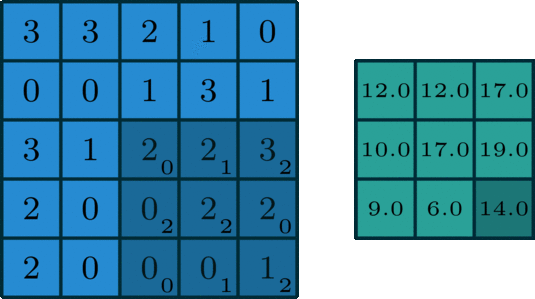
卷积
所以对于一个 的图片,卷积核大小为 ,滑动步长为1,则新生成的图片大小为 。更一般地,对于一个 的图片,卷积核大小为 ,滑动步长为 1,则新生成的图片大小为 。
1.1.padding 填白
从上面的公式中,原图像在经过filter卷积之后,变小了。
- 每次卷积,图像都缩小,这样卷不了几次就没了;
- 相比于图片中间的点,图片边缘的点在卷积中被计算的次数很少。这样的话,边缘的信息就易于丢失。
为了解决这个问题,我们可以采用padding的方法。我们每次卷积前,先给图片周围都补一圈空白,让卷积之后图片跟原来一样大,同时,原来的边缘也被计算了更多次。有same和valid两种方式,让卷积之后的大小不变”的padding方式,称为 “Same”方式,不经过任何填白的,称为 “Valid”方式。
1.2.stride 步长
前面我们所介绍的卷积,都是默认步长是1,但实际上,我们可以设置步长为其他的值。
比如,对于(8,8)的输入,我们用(3,3)的filter,
如果stride=1,则输出为(6,6);
如果stride=2,则输出为(3,3);
1.3.对多通道(channels)图片的卷积
彩色图像,一般都是RGB三个通道(channel)的,因此输入数据的维度一般有三个:(长,宽,通道)。
比如一个28×28的RGB图片,维度就是(28,28,3)。
输入图片是2维的(8,8),filter是(3,3),输出也是2维的(6,6)。
如果输入图片是三维的呢(即增多了一个channels),比如是(8,8,3),这个时候,我们的filter的维度就要变成(3,3,3)了,它的 最后一维要跟输入的channel维度一致。
这个时候的卷积,是三个channel的所有元素对应相乘后求和,也就是之前是9个乘积的和,现在是27个乘积的和。因此,输出的维度并不会变化。还是(6,6)。
但是,一般情况下,我们会 使用多了filters同时卷积,比如,如果我们同时使用4个filter的话,那么 输出的维度则会变为(6,6,4)。
上面只对一个通道进行卷积,而一张图片有RGB一共3个通道,所以要对3个通道分别进行卷积运算,如下图所示。

2、池化层
池化层的输入就是卷积层输出的原数据与相应的卷积核相乘后的输出矩阵
池化层的目的:
- 为了减少训练参数的数量,降低卷积层输出的特征向量的维度
- 减小过拟合现象,只保留最有用的图片信息,减少噪声的传递
最常见的两种池化层的形式:
- 最大池化:max-pooling——选取指定区域内最大的一个数来代表整片区域
- 均值池化:mean-pooling——选取指定区域内数值的平均值来代表整片区域
举例说明两种池化方式:(池化步长为2,选取过的区域,下一次就不再选取)
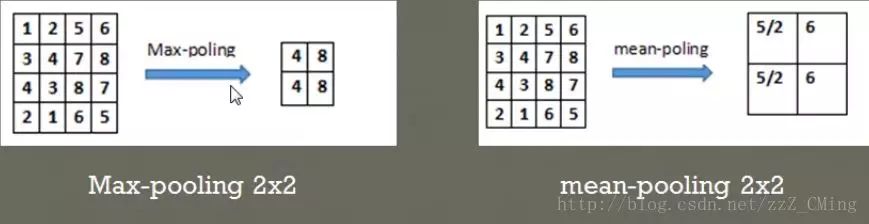
3、全连接层
卷积层和池化层的工作就是提取特征,并减少原始图像带来的参数。然而,为了生成最终的输出,我们需要应用全连接层来生成一个等于我们需要的类的数量的分类器。
我们需要把池化层输出的张量重新切割成一些向量,乘上权重矩阵,加上偏置值,然后对其使用ReLU激活函数,用梯度下降法优化参数既可。
6.3tensorflow实现CNN
from tensorflow.examples.tutorials.mnist import input_dataimport tensorflow as tfimport osos.environ["CUDA_VISIBLE_DEVICES"] = '0'def weight_variable(shape):# 产生随机变量# truncated_normal:选取位于正态分布均值=0.1附近的随机值initial = tf.truncated_normal(shape, stddev=0.1)return tf.Variable(initial)def bias_variable(shape):initial = tf.constant(0.1, shape=shape)return tf.Variable(initial)def conv2d(x, W):#stride = [1,水平移动步长,竖直移动步长,1]return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')def max_pool_2x2(x):# stride = [1,水平移动步长,竖直移动步长,1]return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],strides=[1, 2, 2, 1], padding='SAME')#读取MNIST数据集mnist = input_data.read_data_sets('MNIST_data', one_hot=True)sess = tf.InteractiveSession()#预定义输入值X、输出真实值Y placeholder为占位符x = tf.placeholder(tf.float32, shape=[None, 784])y_ = tf.placeholder(tf.float32, shape=[None, 10])keep_prob = tf.placeholder(tf.float32)x_image = tf.reshape(x, [-1,28,28,1])#print(x_image.shape) #[n_samples,28,28,1]#卷积层1网络结构定义#卷积核1:patch=5×5;in size 1;out size 32;激活函数reLU非线性处理W_conv1 = weight_variable([5, 5, 1, 32])b_conv1 = bias_variable([32])h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) #output size 28*28*32h_pool1 = max_pool_2x2(h_conv1) #output size 14*14*32#卷积层2网络结构定义#卷积核2:patch=5×5;in size 32;out size 64;激活函数reLU非线性处理W_conv2 = weight_variable([5, 5, 32, 64])b_conv2 = bias_variable([64])h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) #output size 14*14*64h_pool2 = max_pool_2x2(h_conv2) #output size 7 *7 *64# 全连接层1W_fc1 = weight_variable([7*7*64,1024])b_fc1 = bias_variable([1024])h_pool2_flat = tf.reshape(h_pool2, [-1,7*7*64]) #[n_samples,7,7,64]->>[n_samples,7*7*64]h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # 减少计算量dropout# 全连接层2W_fc2 = weight_variable([1024, 10])b_fc2 = bias_variable([10])prediction = tf.matmul(h_fc1_drop, W_fc2) + b_fc2#prediction = tf.nn.softmax(stf.matmul(h_fc1_drop, W_fc2) + b_fc2)#二次代价函数:预测值与真实值的误差loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=prediction))#梯度下降法:数据太庞大,选用AdamOptimizer优化器train_step = tf.train.AdamOptimizer(1e-4).minimize(loss)#结果存放在一个布尔型列表中correct_prediction = tf.equal(tf.argmax(prediction,1), tf.argmax(y_,1))#求准确率accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))saver = tf.train.Saver() # defaults to saving all variablessess.run(tf.global_variables_initializer())for i in range(1000):batch = mnist.train.next_batch(50)if i%100 == 0:train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0})print("step",i, "training accuracy",train_accuracy)train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})#保存模型参数saver.save(sess, './model.ckpt')print("test accuracy %g"%accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
1、dropout
tf.nn.dropout是TensorFlow里面为了防止或减轻过拟合而使用的函数,它一般用在全连接层。
Dropout就是在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了。示意图如下:
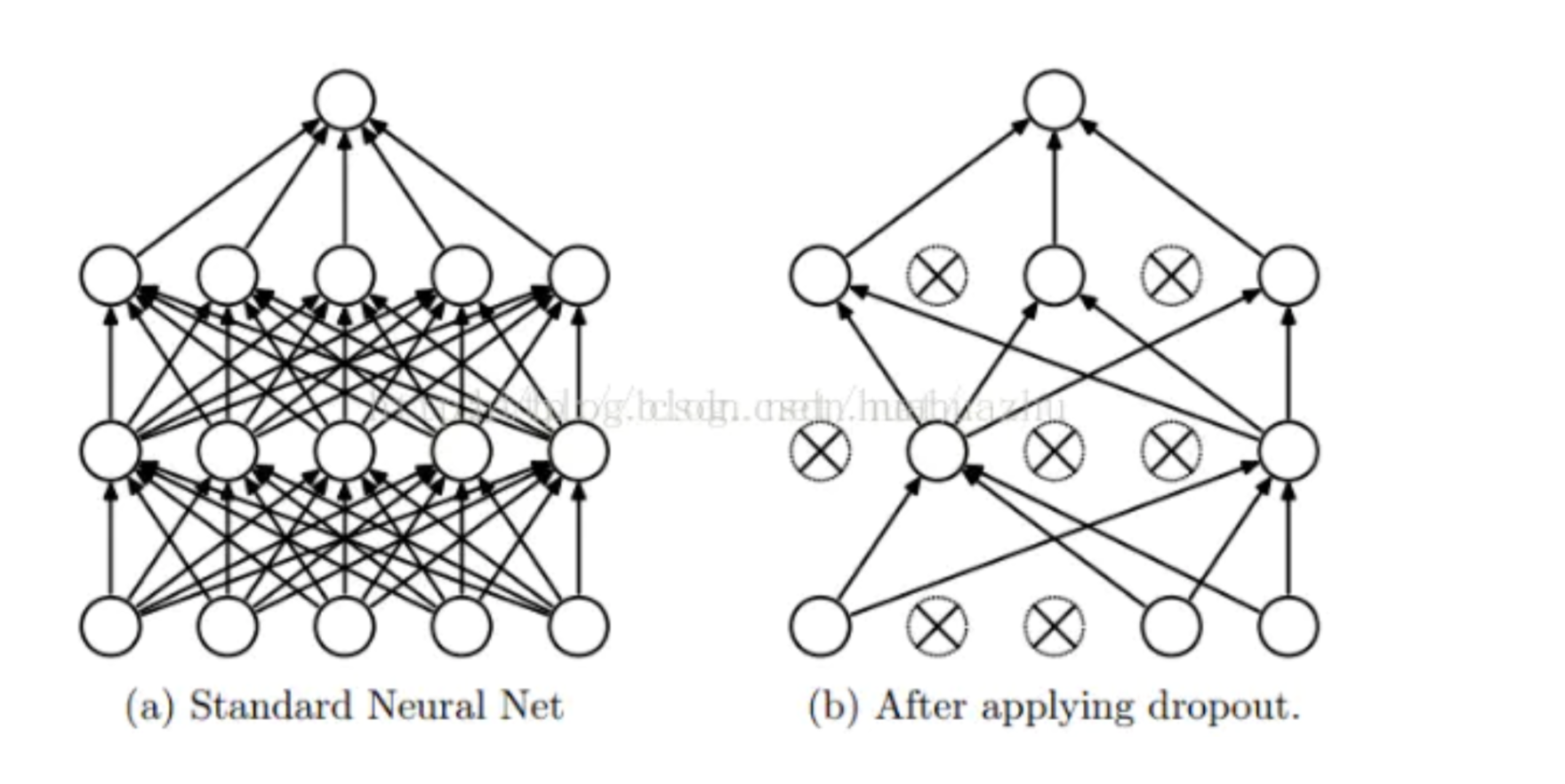

但在测试及验证中:每个神经元都要参加运算,但其输出要乘以概率p。
tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None,name=None)
- x:指输入
- keep_prob:设置神经元被选中的概率,在初始化时keep_prob是一个占位符, keep_prob = tf.placeholder(tf.float32) 。
tensorflow在run时设置keep_prob具体的值,例如keep_prob: 0.5
tensorflow中的dropout就是:使输入tensor中某些元素变为0,其它没变0的元素值变为原来的1/keep_prob大小!
2、损失函数


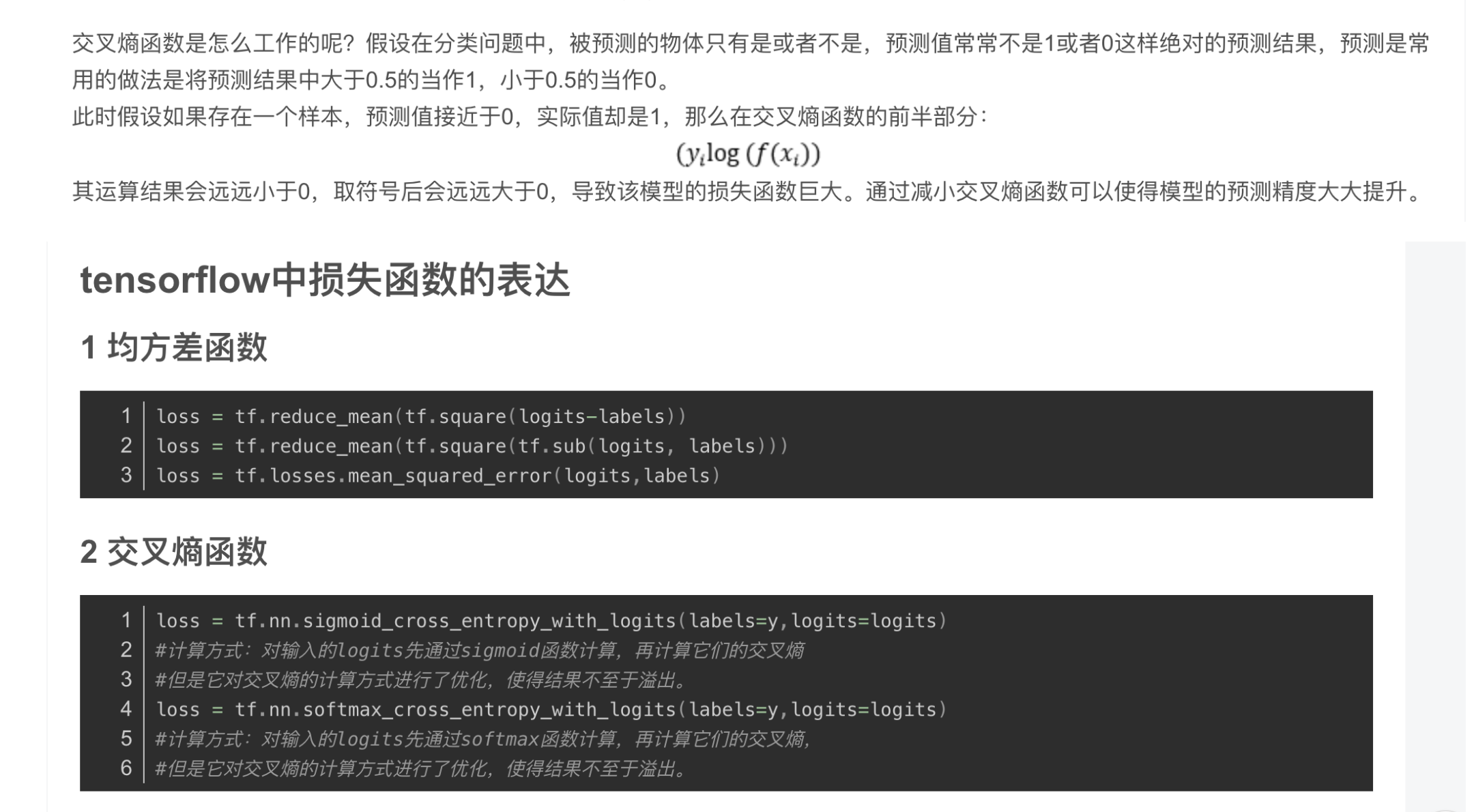
注意由于loss函数在运算的时候会自动进行softmax或者sigmoid函数的运算,所以这里对于logits不需要特殊激励函数。
tf.nn.sparse_softmax_cross_entropy_with_logits是tf.nn.softmax_cross_entropy_with_logits的易用版本,这个版本的logits的形状依然是[batch_size, num_classes],但是labels的形状是[batch_size, 1],每个label的取值是从[0, num_classes)的离散值,这也更加符合我们的使用习惯,是哪一类就标哪个类对应的label。
后续。。。




























还没有评论,来说两句吧...