hadoop-3.2.1伪分布集群安装
准备环境:
一台虚拟机(centos7)
ip:192.168.8.124
hostname:hadoop124
一、前提环境准备
1.设置静态ip
设置好后,需要重启网络
service network restart
2.设置主机名
临时设置主机名
永久设置主机名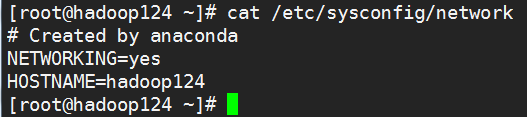
3.hosts文件配置
4.关闭防火墙
注意,centos6跟centos7命令不同
临时关闭防火墙
systemctl stop firewalld
永久关闭防火墙
systemctl disable firewalld
5.ssh免密码登录
ssh-keygen -t rsa#向本机复制公钥cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
验证
第一次需要输入yes,后续就不用了
ssh hadoop124
6.jdk的安装,略,我在虚拟机上安装的是jdk1.8
二、正式安装伪分布集群
上面的工作都是前提环境搭建。
官网下载hadoop3.2.1,我解压到了/data/soft/目录,需要配置一个环境变量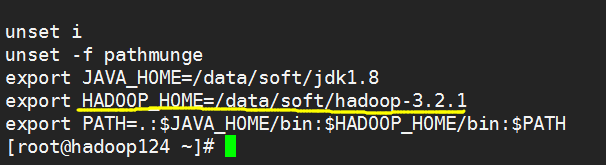
修改环境变量需要执行source /etc/profile让环境变量生效
1.修改hadoop相关配置文件
[root@hadoop124 ~]# cd /data/soft/hadoop-3.2.1/etc/hadoop/[root@hadoop124 hadoop]# vi core-site.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop124:9000</value></property><property><name>hadoop.tmp.dir</name><value>/data/hadoop_repo</value></property></configuration>[root@hadoop124 hadoop]# vi hdfs-site.xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>[root@hadoop124 hadoop]# vi mapred-site.xml<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>[root@hadoop124 hadoop]# vi yarn-site.xml<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CL ASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property></configuration>
修改hadoop-env.sh文件,增加环境变量
export JAVA_HOME=/data/soft/jdk1.8export HADOOP_LOG_DIR=/data/hadoop_repo/logs/hadoop
2.格式化namenode
[root@hadoop124 hadoop-3.2.1]# pwd/data/soft/hadoop-3.2.1[root@hadoop124 hadoop-3.2.1]# bin/hdfs namenode -format
有如下信息,说明格式化成功
3.启动hadoop集群
[root@hadoop124 hadoop-3.2.1]# sbin/start-all.sh

报五个变量没有定义,解决方法为
修改start-dfs.sh,stop-dfs.sh这两个脚本,在文件前面增加如下内容:(两个都要加)
#!/usr/bin/env bashHDFS_DATANODE_USER=rootHDFS_DATANODE_SECURE_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root
修改start-yarn.sh,stop-yarn.sh这两个脚本,在文件前面增加如下内容:(两个都要加)
#!/usr/bin/env bashYARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root
再次执行成功了,可以看到有五个进程。
除了通过jps命令验证,也可以通过webui界面来验证集群服务是否启动成功。
HDFS 的web管理界面: http://192.168.8.124:9870
YARN 的web管理界面: http://192.168.8.124:8088

停止集群




























")

实践篇 动手理解RabbitMQ五种模式 两小时搞定Rabbit应用 摸清路由器的的路由、广播、Topic 类型 了解Comfirm Return的过程")
:构建下一代基础设施 PDN")



还没有评论,来说两句吧...