LinkedHashMap源码分析
阅读本文章之前推荐先阅读博主的以下两篇文章:
HashMap源码分析 + 面试题
LinkedList源码分析,基于JDK1.8逐行分析
LinkedHashMap源码分析
文章目录
- LinkedHashMap源码分析
- 一、整体架构
- 基本介绍
- 存储结构图
- 二、源码分析
- 成员属性
- 内部类
- 构造方法
- 增加方法
- 查询方法
- 5.1 get方法
- 5.2 getOrDefault方法
- 删除方法
一、整体架构
1. 基本介绍
继承体系
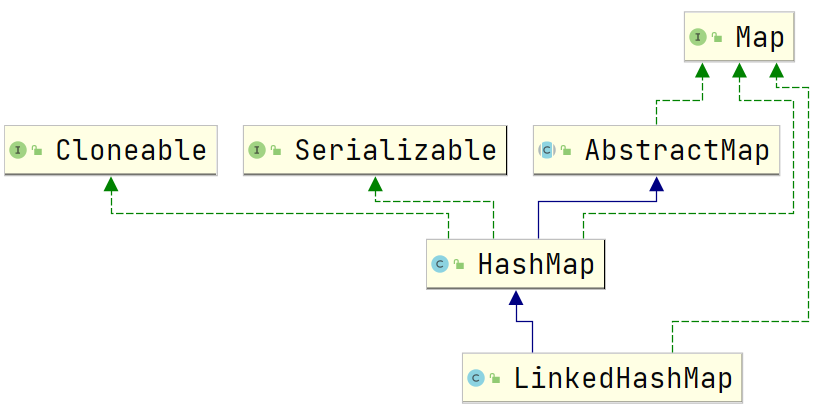
- LinkedHashMap = LinkedList + HashMap
- LinkedHashMap继承于HashMap,所以拥有HashMap的所有特性,区别是LinkedHashMap内部维护了一个双向链表
- LinkedHashMap的元素允许为null,非线程安全
LinkedHashMap支持两种访问顺序:
按插入顺序访问
- 弥补了HashMap无法保证插入顺序的缺陷,但由于要维护顺序,故效率不如HashMap
按访问顺序访问
- 刚刚被访问的元素将其追加到队尾
- 访问次数最少的元素自然会靠近队首,可以设置删除策略,当满足一定条件时将头节点删除,其目的是把很久都没有访问的key自动删除
- 实现LRU缓存策略(最近最少使用)
2. 存储结构图
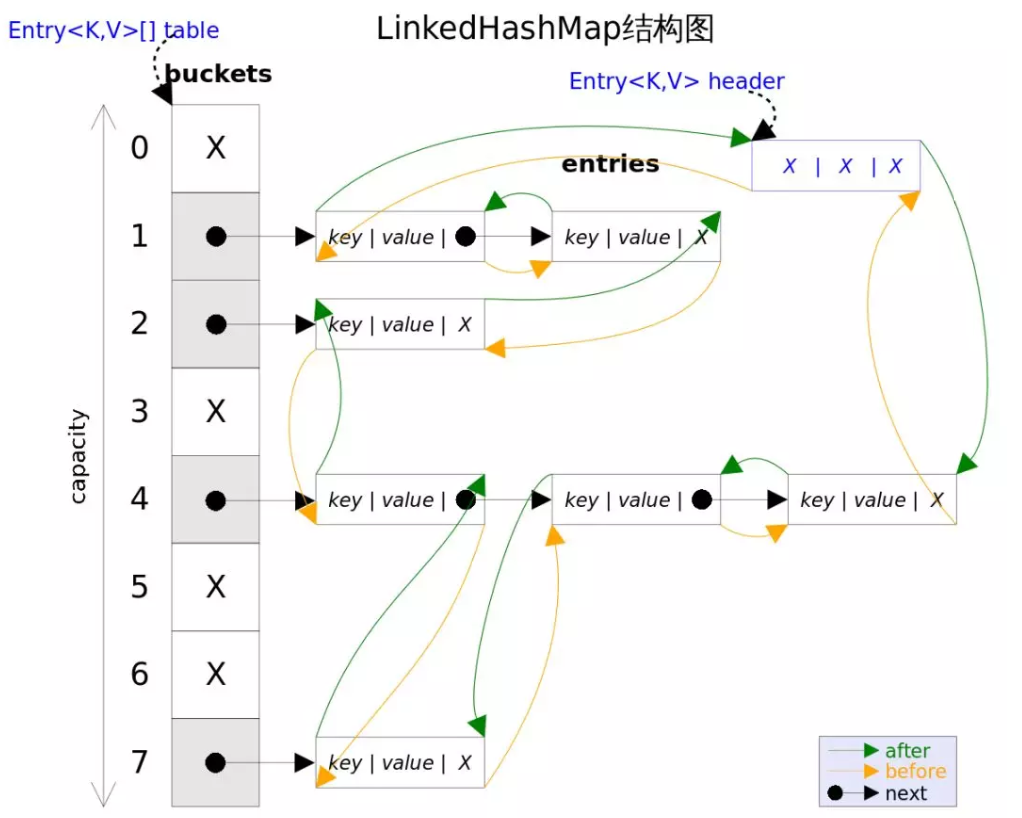
从上图观察得知
- LinkedHashMap存储数据的结构是Entry
- LinkedHashMap底层也是 数组 + 链表 + 红黑树 的结构,但是添加了双向链表保证了所有元素的顺序
区分三个不同的指向
- next用于维护数组桶中的单向链表,是属于HashMap的
- after、before用于维护LinkedHashMap的双向链表,是属于双向链表(LinkedHashMap)的
- next、before / after的作用对象都是Entry,但是各自分离,是两码事儿
二、源码分析
1. 成员属性
//指向双向链表的头节点transient LinkedHashMap.Entry<K,V> head;//指向双向链表的尾节点transient LinkedHashMap.Entry<K,V> tail;//用于区分访问顺序的类别//默认为false,即按插入顺序访问//取值为true时,按访问顺序访问final boolean accessOrder;
2. 内部类
//LinkedHashMap存储元素的结构是Entry//Entry中包含了HashMap的Node结构//得出结论,LinkedHashMap的Entry就是在HashMap的Node的基础上添加了双向链表的前后指针static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}}//LinkedHashMap的数据结构很像是把双向链表的的每个元素换成了HashMap的Node
3. 构造方法
LinkedHashMap的构造方法调用了父类HashMap的构造方法,详细内容不再赘述
public LinkedHashMap() {super();accessOrder = false;}public LinkedHashMap(int initialCapacity) {super(initialCapacity);accessOrder = false;}public LinkedHashMap(int initialCapacity, float loadFactor) {super(initialCapacity, loadFactor);accessOrder = false;}public LinkedHashMap(Map<? extends K, ? extends V> m) {super();accessOrder = false;putMapEntries(m, false);}//上述几种构造器中accessOrder取值均为false,即默认按插入顺序访问//可以设置accessOrder取值的构造器,若accessOrder取值为true,按照访问顺序访问public LinkedHashMap(int initialCapacity,float loadFactor,boolean accessOrder) {super(initialCapacity, loadFactor);this.accessOrder = accessOrder;}
4. 增加方法
LinkedHashMap中没有实现put方法,所以put方法使用的是父类HashMap中的方法,不过覆写了put方法执行中调用的 newNode 方法和 afterNodeInsertion 方法
newNode 方法源码如下:
//newNode方法控制元素追加到双向链表的尾部,用来保证插入顺序Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {//新增节点LinkedHashMap.Entry<K,V> p =new LinkedHashMap.Entry<K,V>(hash, key, value, e);//调用linkNodeLast方法追加到链表的尾部linkNodeLast(p);return p;}//linkNodeLast方法源码如下,典型的双向链表尾插法private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {LinkedHashMap.Entry<K,V> last = tail;//新增节点成为尾节点tail = p;//双向链表为空,首尾节点都是新增节点if (last == null)head = p;//双向链表不为空,建立新增节点和上个尾节点之间的前后关系else {p.before = last;last.after = p;}}
观察上述源码可知,LinkedHashMap在添加元素时就维护了按照插入顺序排序的链表结构
afterNodeInsertion 方法源码如下:
//添加元素之后调用的方法//HashMap中evict传递的实参值为truevoid afterNodeInsertion(boolean evict) {LinkedHashMap.Entry<K,V> first;//如果双向链表的头节点不为空//调用removeEldestEntry方法判断是否需要删除最老的节点(头节点)if (evict && (first = head) != null && removeEldestEntry(first)) {K key = first.key;//调用HashMap的removeNode方法删除头节点,removeNode方法删除头节点后会调用LinkedHashMap中的afterNodeRemoval方法,详见总结中的第二、6小节//这里的头节点是双向链表的头节点,而不是某个桶中的第一个元素removeNode(hash(key), key, null, false, true);}}
removeEldestEntry() 方法源码如下:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false; //默认返回false,也就是不删除最老元素(头节点)}
默认的LinkedHashMap并不会移除旧元素,如果需要移除旧元素,则需要重写 removeEldestEntry() 方法设定移除策略,返回为true就会删除旧元素(头节点),示例如下:
@Override//重写了删除策略的方法,设定当节点个数大于3时,就删除头节点protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {return size() > 3;}
综上所述,put方法添加元素时也会执行移除策略
5. 查询方法
5.1 get方法
get() 方法源码如下:
public V get(Object key) {Node<K,V> e;//调用父类HashMap的getNode方法获取元素if ((e = getNode(hash(key), key)) == null)return null;//判断属性accessOrder是否为true,如果为true,表示按访问顺序访问//调用afterNodeAccess方法把访问的节点移到双向链表的末尾if (accessOrder)afterNodeAccess(e);return e.value;}
afterNodeAccess() 方法源码如下:
//访问节点后被调用的方法void afterNodeAccess(Node<K,V> e) {LinkedHashMap.Entry<K,V> last;//如果accessOrder为true,并且访问的节点不是尾节点if (accessOrder && (last = tail) != e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;//先将要访问的节点从双向链表中的原位置移除p.after = null;if (b == null)head = a;elseb.after = a;if (a != null)a.before = b;elselast = b;//再将要访问的节点放到双向链表的末尾,末尾为最新访问的元素if (last == null)head = p;else {p.before = last;last.after = p;}tail = p;//计数器加一++modCount;}}
观察上述源码可知,LinkedHashMap比HashMap访问节点时多了判断是否按照访问顺序访问的步骤
注意:afterNodeAccess() 方法不仅 get() 方法中会调用,put() 已经存在的元素时也会被调用(put与get都算是对节点的访问)
5.2 getOrDefault方法
getOrDefault() 方法源码如下:
基本上与get方法的作用一致,区别在于当没有找到元素时返回的是指定的参数 defaultValue,而不是null
public V getOrDefault(Object key, V defaultValue) {Node<K,V> e;if ((e = getNode(hash(key), key)) == null)return defaultValue;if (accessOrder)afterNodeAccess(e);return e.value;}
6. 删除方法
LinkedHashMap中没有实现 remove() 方法,调用的仍然是父类HashMap的方法,LinkedHashMap中重写的是 remove() 方法调用的 afterNodeRemoval() 方法
afterNodeRemoval() 方法源码如下:
//节点被删除后调用的方法//典型的把节点从双向链表中删除的方法void afterNodeRemoval(Node<K,V> e) {LinkedHashMap.Entry<K,V> p =(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;p.before = p.after = null;if (b == null)head = a;elseb.after = a;if (a == null)tail = b;elsea.before = b;}


































还没有评论,来说两句吧...