【集合】LinkedHashMap 源码分析
前言
Github:https://github.com/yihonglei/jdk-source-code-reading
HashTable 源码
HashMap 源码
ConcurrentHashMap 源码
一 概述
LinkedHashMap 对数据的操作依赖 HashMap,对 HashMap 进行包装,解决 HashMap 的
无序性。底层基于双向链表 + 数组 + 单向链表 + 红黑树 实现,后三者是 HashMap 的底层
数据结构,依赖双向链表维护顺序性。LinkedHashMap 分为按两种顺序排列,
一种是按照插入的顺序排序,一种是按照访问的顺序排序,并且 LinkedHashMap 支持更好
的 LRU 算法。
二 实例
【Leetcode】LRU 缓存机制,最早插入的是最久不使用的,当缓存满的时候,删除最久
不使用的,为新插入的元素预留存储空间。
package com.jpeony.collection.linked;import java.util.LinkedHashMap;import java.util.Map;/*** 【题源】https://leetcode-cn.com/problems/lru-cache/** @author yihonglei*/public class LRUCache extends LinkedHashMap<Integer, Integer> {int capacity = 0;public LRUCache(int capacity) {super(capacity, 0.75f, true);this.capacity = capacity;}/*** 查询缓存,没有则返回 -1*/public int get(int key) {return super.getOrDefault(key, -1);}/*** 插入缓存,当缓存满了,调用 removeEldestEntry() 判断是否要移出最久不使用的元素,* 需要则调用 removeNode() 移出最久元素,为新元素的插入预留空间。*/public void put(int key, int value) {super.put(key, value);}/*** 是否要删除最近元素*/@Overrideprotected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {return size() > capacity;}}
三 LinkedHashMap 底层实现
重点分析“按插入顺序排序”和“按访问顺序排序”实现逻辑。
重要属性
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {/*** 链表结点*/static class Entry<K,V> extends HashMap.Node<K,V> {Entry<K,V> before, after;Entry(int hash, K key, V value, Node<K,V> next) {super(hash, key, value, next);}}/*** 链表头结点*/transient LinkedHashMap.Entry<K,V> head;/*** 链表尾节点*/transient LinkedHashMap.Entry<K,V> tail;/*** true 时 access-order,即按访问顺序遍历,如果为 false,则表示按插入顺序遍历。默认为false。*/final boolean accessOrder;}
accessOrder
accessOrder 为 true 时,即按访问顺序排序,如果为 false,则表示按插入顺序排序。
默认为 false。
按插入顺序性排序
LinkedHashMap#put()
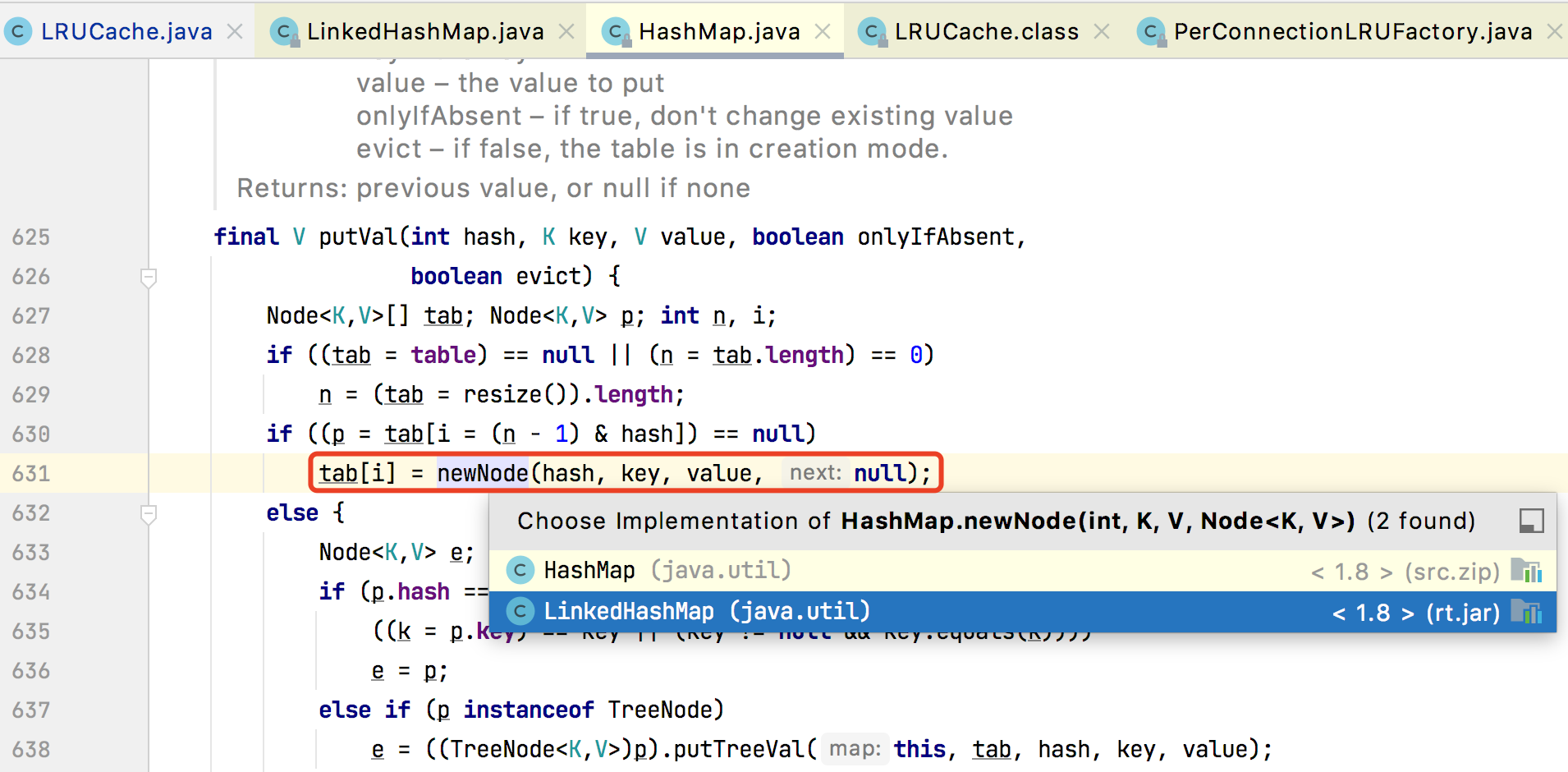
put() 顺序的精华在于 LinkedHashMap 重写了 HashMap 的 newNode() 构造器方法。
newNode()
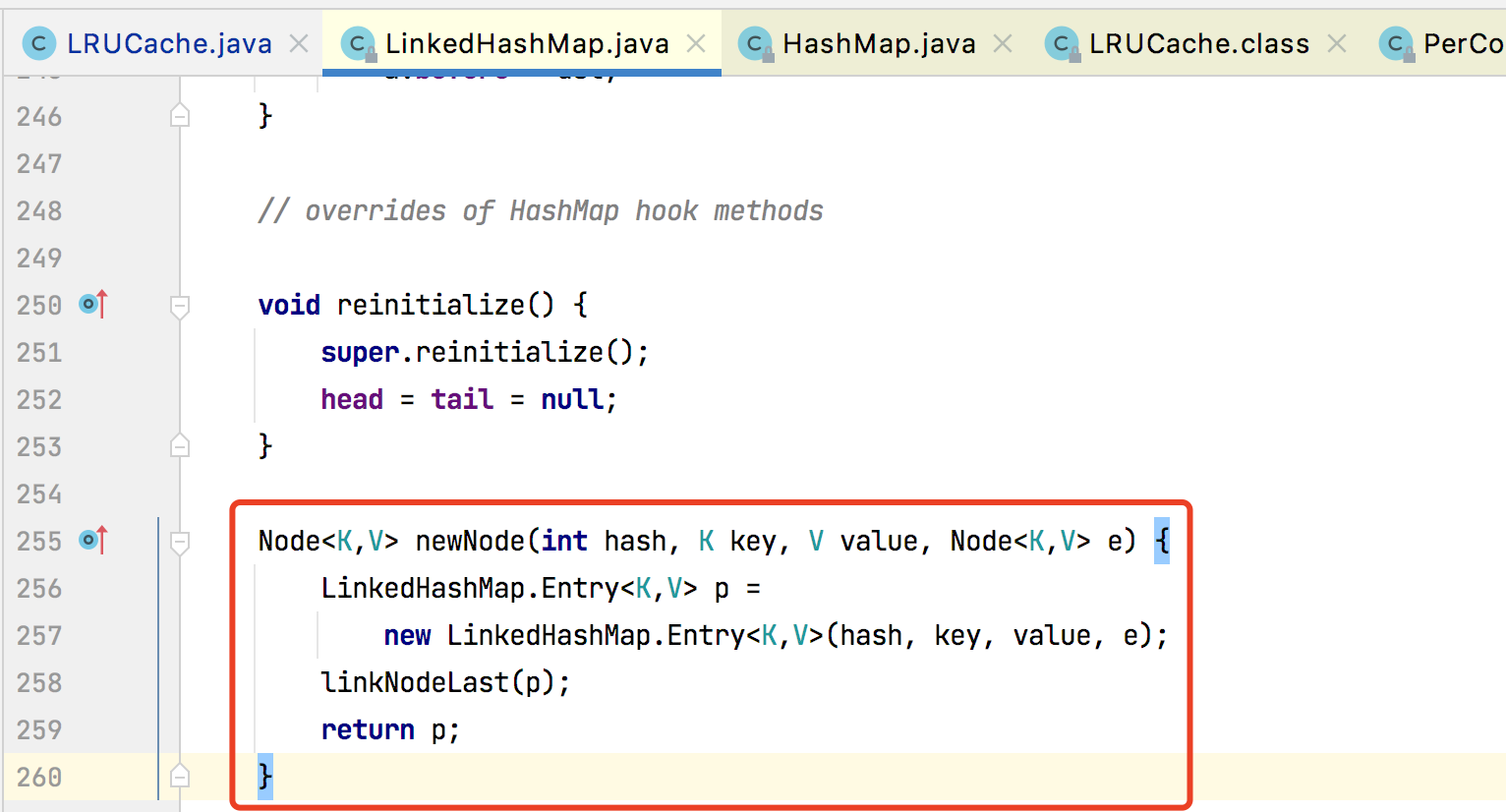
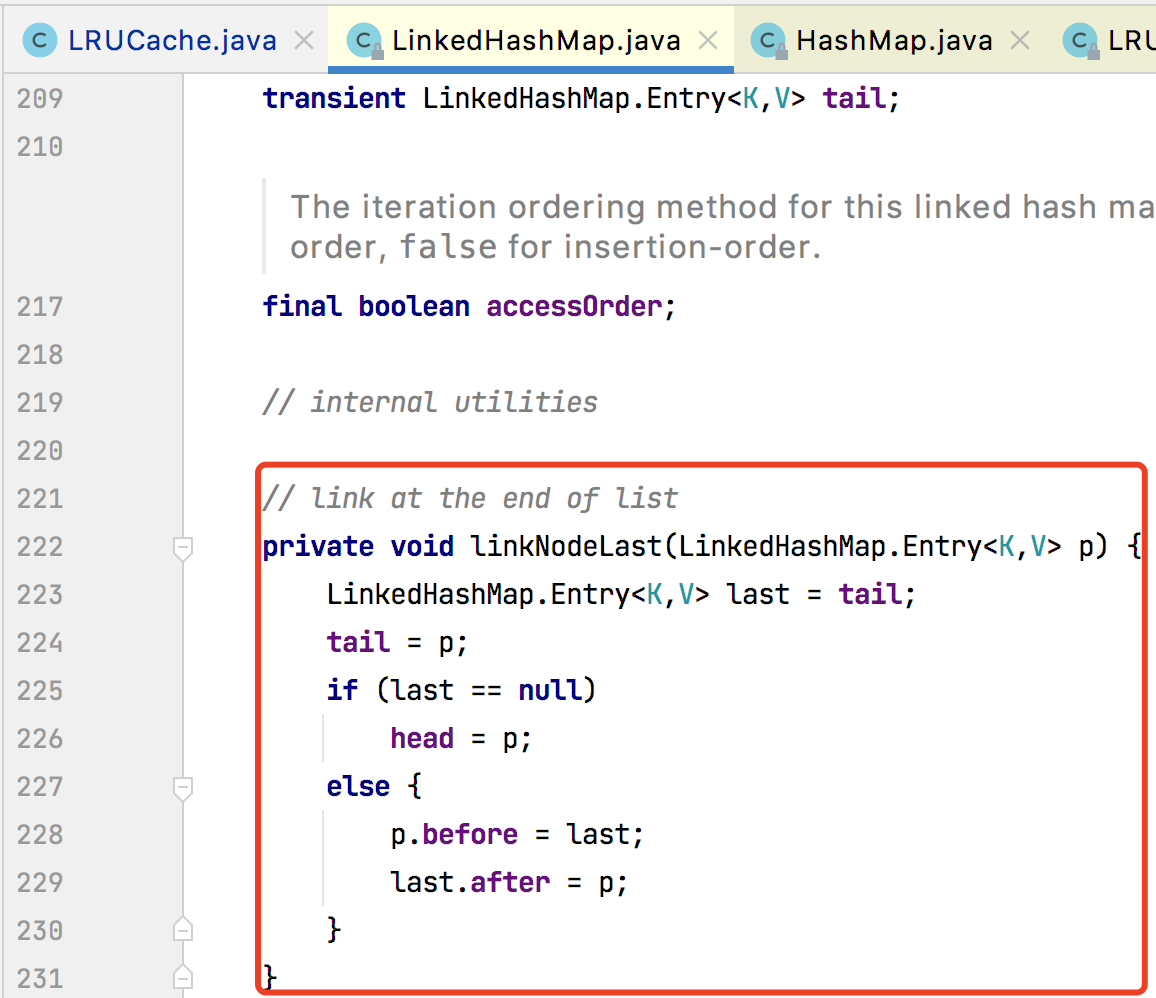
linkNodeLast()
将结点添加到链表尾部,从而保证插入的顺序性。
按读取顺序性排序
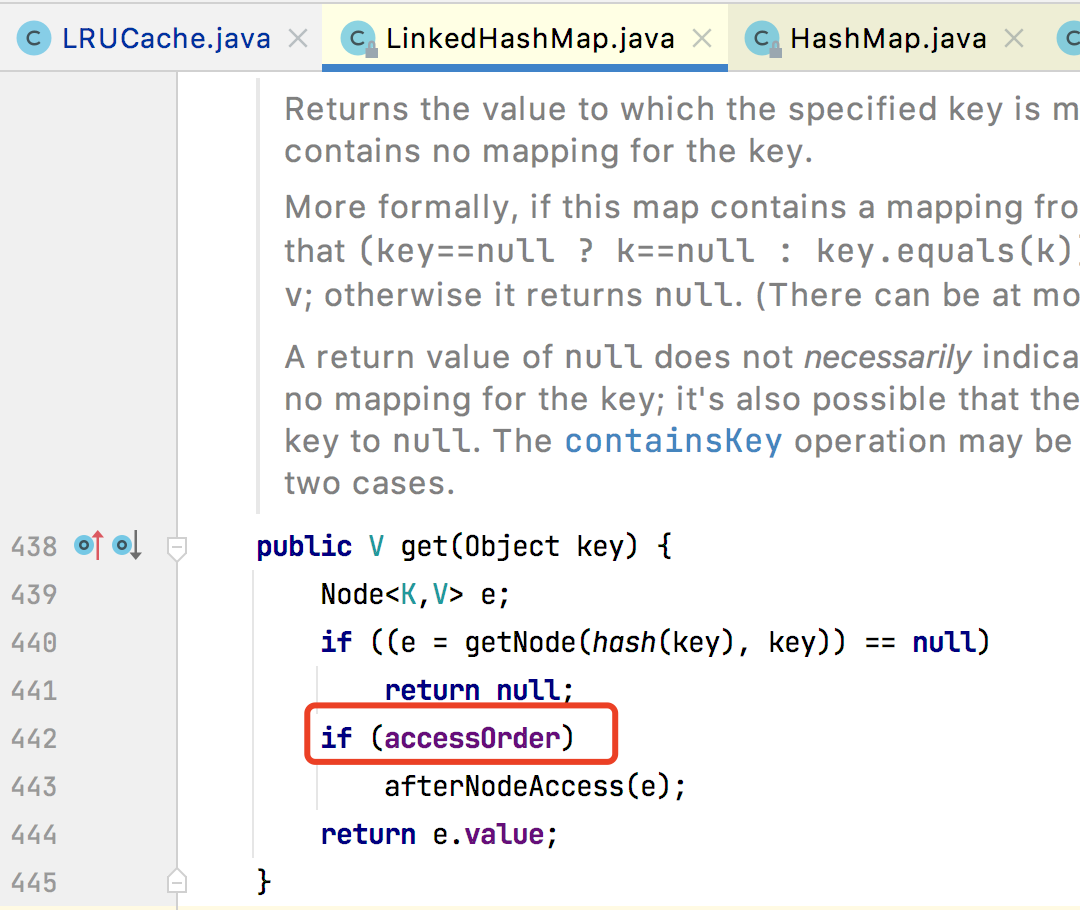
LinkedHashMap#get()
如果 accessOrder 为 true,表示按照访问的顺序排序,则调用 afterNodeAccess 将访问元素放
到链表尾部,从而实现按照访问的顺序排序。
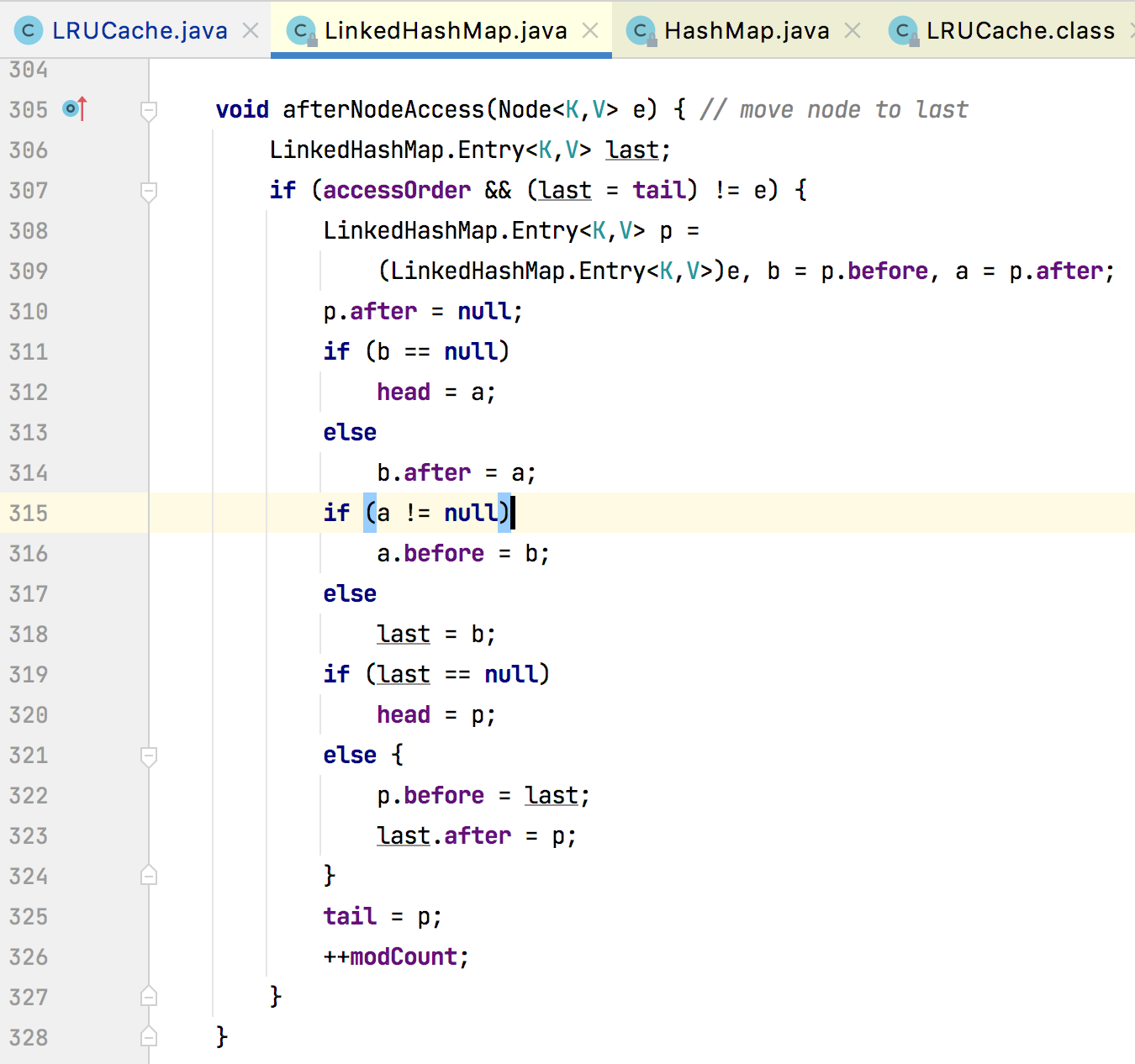
afterNodeAccess()
其作用就是在访问元素之后,将该元素放到双向链表的尾巴处(所以这个函数只有在按照读取的顺
序的时候才会执行)。
LUR 操作
在插入元素的时候,如果存储满了,删除最久未使用的元素,即头结点。
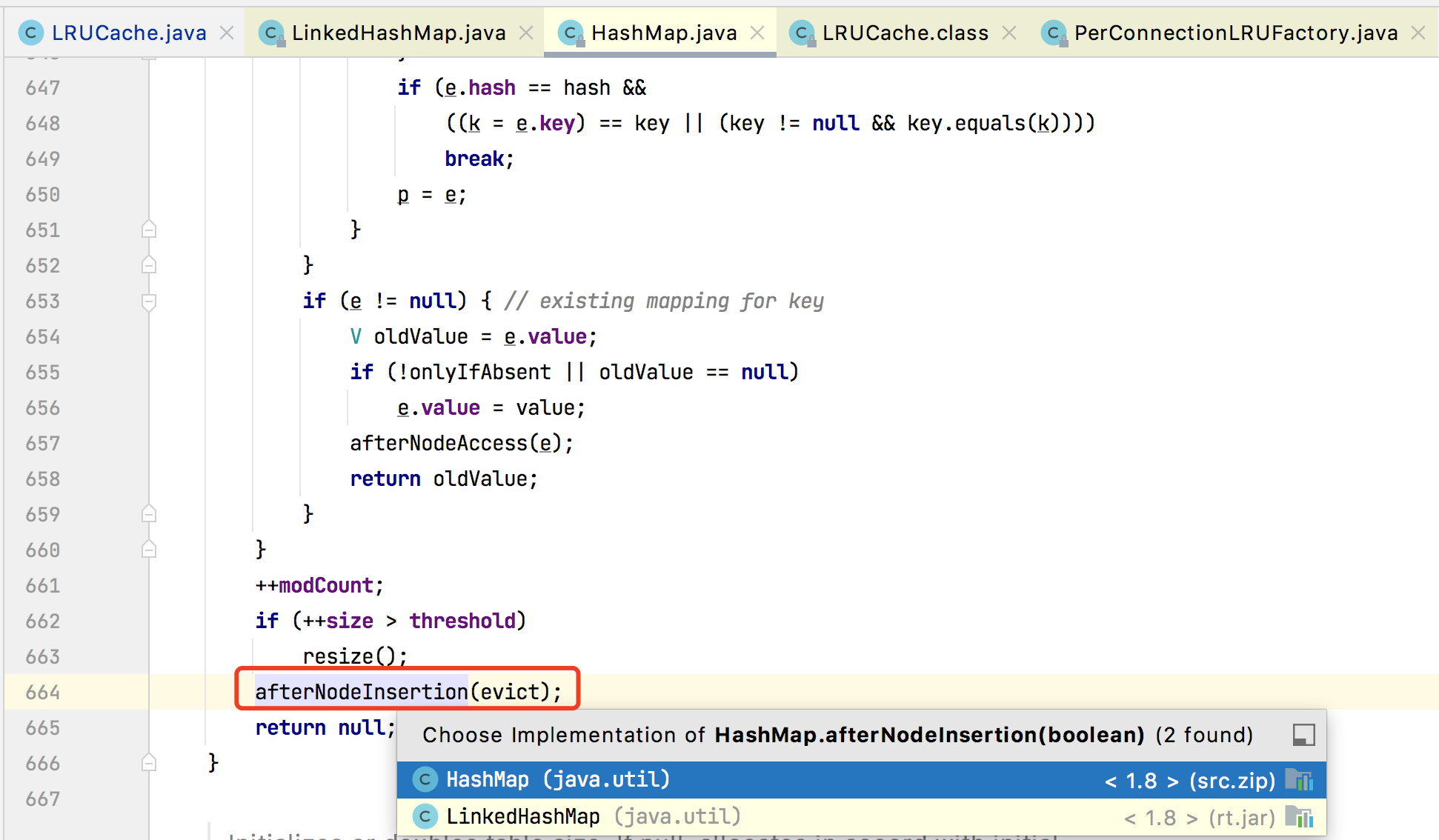
afterNodeInsertion()
在插入新元素之后,需要回调函数判断是否需要移除一直不用的某些元素。
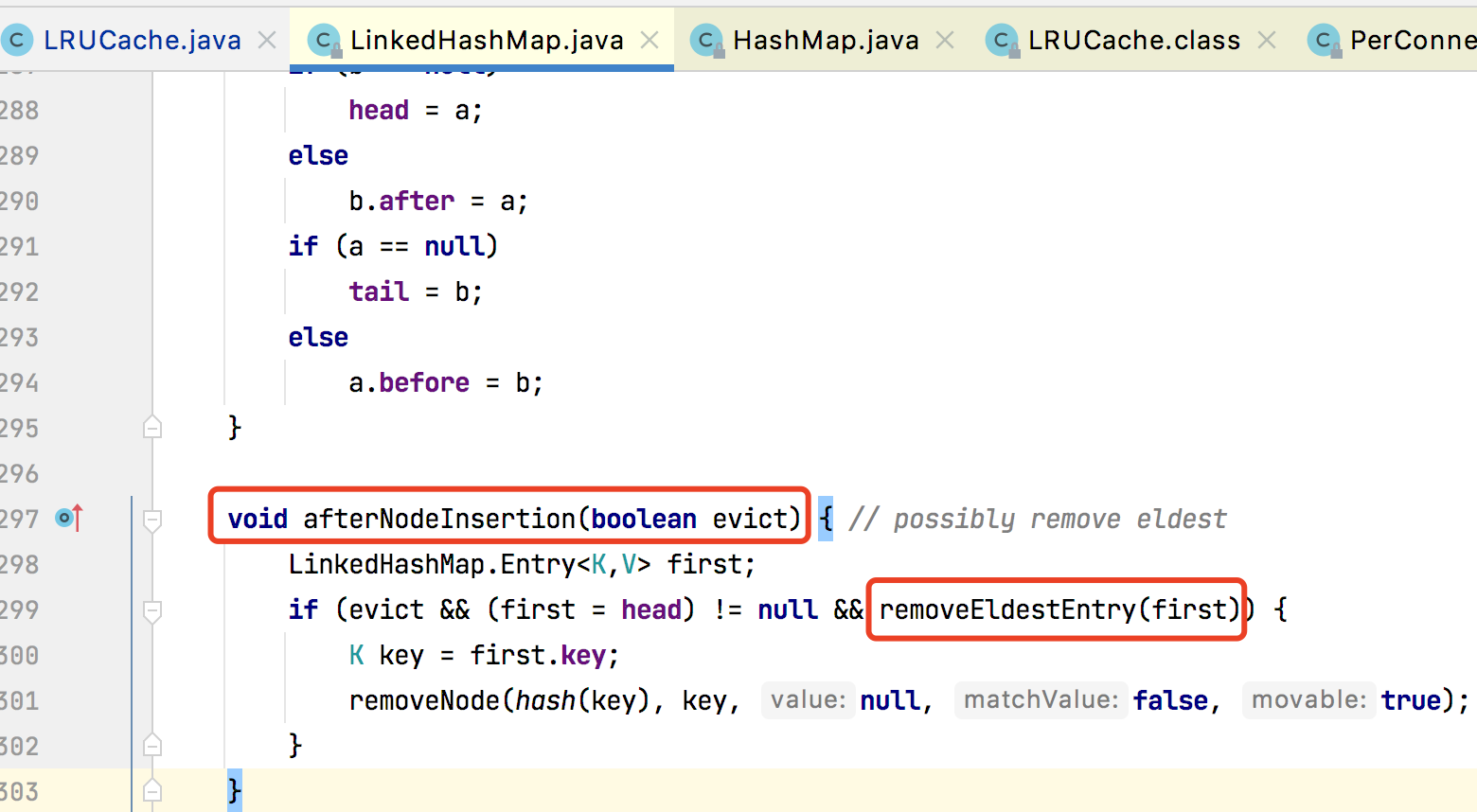
removeEldestEntry()
这个是需要具体继承 LinkedHashMap 的子类重写的逻辑,你可以写自己的满逻辑。
removeNode()
真正去删除链表的头结点。
四 总结
1、HashMap 是无序的,如果用 HashMap 实现本地缓存,不能很好支持 LRU 淘汰策略,
通过 LinkedHashMap 加个双向链表维护有序性,支持 LRU 这样的快速操作;
2、关于 散列表有很多实现。
HashTable,通过 synchronized 锁哈希表方式实现线程安全,jdk 已经对其放弃维护更新,
价值不大,是线程安全的散列表;
HashMap,通过 数组+链表(解决 hash 冲突),在 jdk1.8 加了 红黑树优化链表时间复杂度退化
O(n) 问题,并从链表的头插入优化到尾插法,解决并发时扩容导致 HashMap 死循环问题的线程
安全问题,是非线程安全的散列表;
SychronizedMap,包装 HashMap 解决线程安全问题,但是性能并不理想;
ConcurrentHashMap,底层基于 数组+链表(解决 hash 冲突),在 jdk1.8 加了 红黑树优化链
表时间复杂度退化 O(n) 问题,通过 分段锁解决线程安全问题,在 jdk1.8 优化为 sychronized +
CAS 解决线程安全问题,是线程安全的散列表;
LinkedHashMap,通过双向链表解决 HashMap 无序问题,非线程安全;
你会发现 jdk 搞这么多散列表干啥子,其实就像业务系统,一开始就是满足一种需求,然后不断
优化需求,搞得越来越多优化,选择适合的,才是最好的。这些散列表实现方式,都是围绕着
散列表的执行性能和线程安全的中心思想进行不断优化升级,并拓展了一些比如顺序性啥的
额外需求,你可能要问顺序性有啥用,如果你要让你自己实现 LRU 缓存淘汰策略,这个时候
顺序性的 LinkedHashMap 数据结构就能最快的满足你的 LRU 算法轻而易举实现缓存淘汰。


































还没有评论,来说两句吧...