JVM 类加载器详解(加载详情与加载器类型)
加载
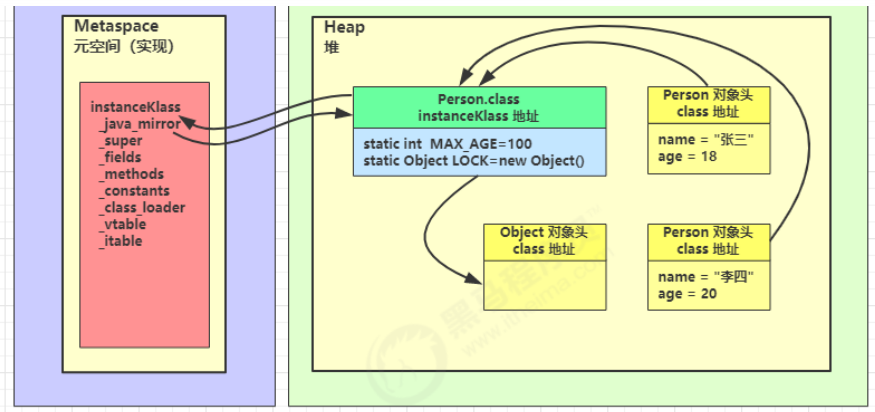
将类的字节码载入方法区中,内部即底层是采用 C++ 的 instanceKlass 描述 java 类,它的重要 field 有:
- _java_mirror 即 java 的类镜像,例如对 String 来说,就是 String.class,作用是把 klass 暴露给 java 使用
- _super 即父类
- _fields 即成员变量
- _methods 即方法
- _constants 即常量池
- _class_loader 即类加载器
- _vtable 虚方法表
- _itable 接口方法表
如果这个类还有父类没有加载,先加载父类;加载和链接可能是交替运行的。
instanceKlass 这样的【元数据】是存储在方法区(1.8 后的元空间内),但 _java_mirror是存储在堆中,可以通过前面介绍的 HSDB 工具查看。
链接
1、 验证:验证类是否符合 JVM规范,安全性检查
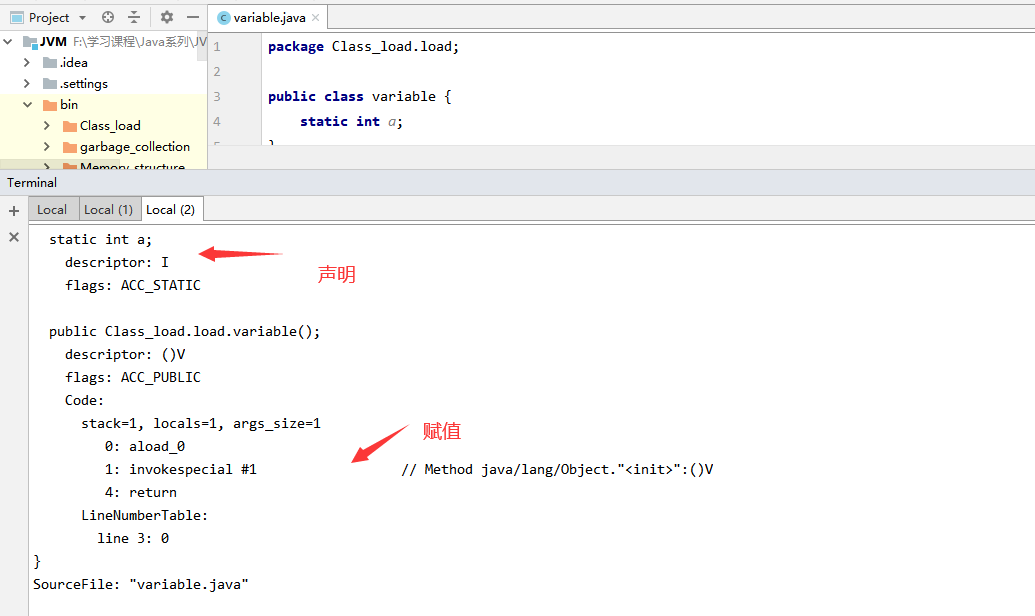
2、 准备:为 static 变量分配空间,设置默认值
- static 变量在 JDK 7 之前存储于 instanceKlass 末尾,从 JDK 7 开始,存储于 _java_mirror 末尾
- static 变量分配空间和赋值是两个步骤,分配空间在准备阶段完成,赋值在初始化阶段完成
- 如果 static 变量是 final 的基本类型,以及字符串常量,那么编译阶段值就确定了,赋值在准备阶段完成
- 如果 static 变量是 final 的,但属于引用类型,那么赋值也会在初始化阶段完成
使用一个简单的变量声明进行测试,可以发现变量的声明和赋值时分开的。
3、解析
在类的初始化时如果这个类没有被使用,那么这个类是不会主动加载的。
初始化
<cinit>()V 方法,初始化即调用 <cinit>()V ,虚拟机会保证这个类的构造方法的线程安全。
使用下面的java代码进行测试:加载A类,查看输出,B类是否会被初始化,也就是说在B类当中的输出语句是否会被执行。答案时很显然的,B类的输出语句是没有输出的。
package Class_load.load;import java.io.IOException;public class analysis_class {public static void main(String[] args) throws ClassNotFoundException, IOException {ClassLoader classloader = analysis_class.class.getClassLoader();// loadClass 方法不会导致类的解析和初始化Class<?> A = classloader.loadClass("Class_load.load.A");}}class A {B b = new B();}class B {static {System.out.println("hello");}}
发生的时机:概括得说,类初始化是懒惰的。
- main 方法所在的类,总会被首先初始化
- 首次访问这个类的静态变量或静态方法时
- 子类初始化,如果父类还没初始化,会引发
- 子类访问父类的静态变量,只会触发父类的初始化
- Class.forName
- new 会导致初始化
不会导致类初始化的情况:
- 访问类的 static final 静态常量(基本类型和字符串)不会触发初始化
- 类对象.class 不会触发初始化
- 创建该类的数组不会触发初始化
- 类加载器的loadClass方法
- Class.forName的参数2为false时
检测:使用字节码对以下代码进行分析
public class practice {public static void main(String[] args) {System.out.println(E.a);System.out.println(E.b);System.out.println(E.c);}}class E {public static final int a = 10;public static final String b = "hello";public static final Integer c = 20; // Integer.valueOf(20)static {System.out.println("init E");}}
在先对上方的变量进行加载,在对Integer包装类型进行初始化的时候会触发类的初始化,所以说init E的输出会在20之前输出。
类加载器
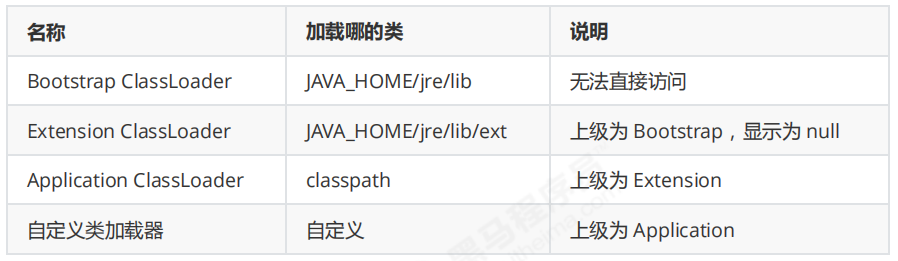
启动类加载器
用 Bootstrap 类加载器加载类:使用下述代码作为测试:
public class start_up {public static void main(String[] args) throws ClassNotFoundException {Class<?> aClass = Class.forName("Class_load.loader.Son");System.out.println(aClass.getClassLoader());}}class Son {static {System.out.println("Son init");}}
使用java命令 java -Xbootclasspath/a:. Class_load.loader.start_up 对类进行加载,
- -Xbootclasspath 表示设置 bootclasspath
- 其中 /a:. 表示将当前目录追加至 bootclasspath 之后
扩展类加载器
使用上方相同的代码,直接运行,在这里会直接初始化加载Son这个类,并且会打印App对象,但在这里如果我们在jdk的扩展类当中加上一个Son的jar包,这时就会加载扩展类的jar包文件。
双亲委派模式
所谓的双亲委派,就是指调用类加载器的 loadClass 方法时,查找类的规则

线程上下文类加载器
我们在使用 JDBC 时,都需要加载 Driver 驱动,不知道你注意到没有,不写
Class.forName("com.mysql.jdbc.Driver")
也是可以让 com.mysql.jdbc.Driver 正确加载的,你知道是怎么做的吗?追踪一下源码:
public class DriverManager {// 注册驱动的集合private final static CopyOnWriteArrayList<DriverInfo> registeredDrivers= new CopyOnWriteArrayList<>();// 初始化驱动static {loadInitialDrivers(); println("JDBC DriverManager initialized");}
先不看别的,看看 DriverManager 的类加载器:
System.out.println(DriverManager.class.getClassLoader());
打印 null,表示它的类加载器是 Bootstrap ClassLoader,会到 JAVA_HOME/jre/lib 下搜索类,但JAVA_HOME/jre/lib 下显然没有 mysql-connector-java-5.1.47.jar 包,这样问题来了,在DriverManager 的静态代码块中,怎么能正确加载 com.mysql.jdbc.Driver 呢?
继续看 loadInitialDrivers() 方法:


先看第二点发现它最后是使用 Class.forName 完成类的加载和初始化,关联的是应用程序类加载器,因此可以顺利完成类加载
再看第一点它就是大名鼎鼎的 Service Provider Interface (SPI)
自定义类加载器
什么时候需要使用自定义类加载器?
- 想加载非 classpath 随意路径中的类文件
- 都是通过接口来使用实现,希望解耦时,常用在框架设计
- 这些类希望予以隔离,不同应用的同名类都可以加载,不冲突,常见于 tomcat 容器
自定义加载类的步骤:
- 继承 ClassLoader 父类
- 要遵从双亲委派机制,重写 findClass 方法
- 注意不是重写 loadClass 方法,否则不会走双亲委派机制 - 读取类文件的字节码
- 调用父类的 defineClass 方法来加载类
- 使用者调用该类加载器的 loadClass 方法
运行期优化
即时编译=>分层编译
使用以下代码进行测试:
public class Jit1 {// -XX:+PrintCompilationpublic static void main(String[] args) {for (int i = 0; i < 200; i++) {long start = System.nanoTime();for (int j = 0; j < 1000; j++) {new Object();}long end = System.nanoTime();System.out.printf("%s%d%s\t%d\n","次数 = ",i,"。 时间 = ",(end - start));}}}
在进行循环创建对象的时候,到后续进行创建新的对象的时候时间会缩短,这是为什么呢?
JVM 将执行状态分成了 5 个层次:
- 0 层,解释执行(Interpreter)
- 1 层,使用 C1 即时编译器编译执行(不带 profiling)
- 2 层,使用 C1 即时编译器编译执行(带基本的 profiling)
- 3 层,使用 C1 即时编译器编译执行(带完全的 profiling)
- 4 层,使用 C2 即时编译器编译执行
在这里使用一个JVM参数 -XX:-DoEscapeAnalysis 关闭即时编译器,这是我们所花费的时间就会变长,也就是在上述的过程中,是不会进入C2。
即时编译器(JIT)与解释器的区别
- 解释器是将字节码解释为机器码,下次即使遇到相同的字节码,仍会执行重复的解释
- JIT 是将一些字节码编译为机器码,并存入 Code Cache,下次遇到相同的代码,直接执行,无需再编译
- 解释器是将字节码解释为针对所有平台都通用的机器码
- JIT 会根据平台类型,生成平台特定的机器码
对于占据大部分的不常用的代码,我们无需耗费时间将其编译成机器码,而是采取解释执行的方式运行;另一方面,对于仅占据小部分的热点代码,我们则可以将其编译成机器码,以达到理想的运行速度。 执行效率上简单比较一下 Interpreter < C1 < C2,总的目标是发现热点代码(hotspot名称的由来),优化之刚才的一种优化手段称之为【逃逸分析】,
即时编译=>方法内联
使用以下代码段进行测试:在执行一千次方法调用:
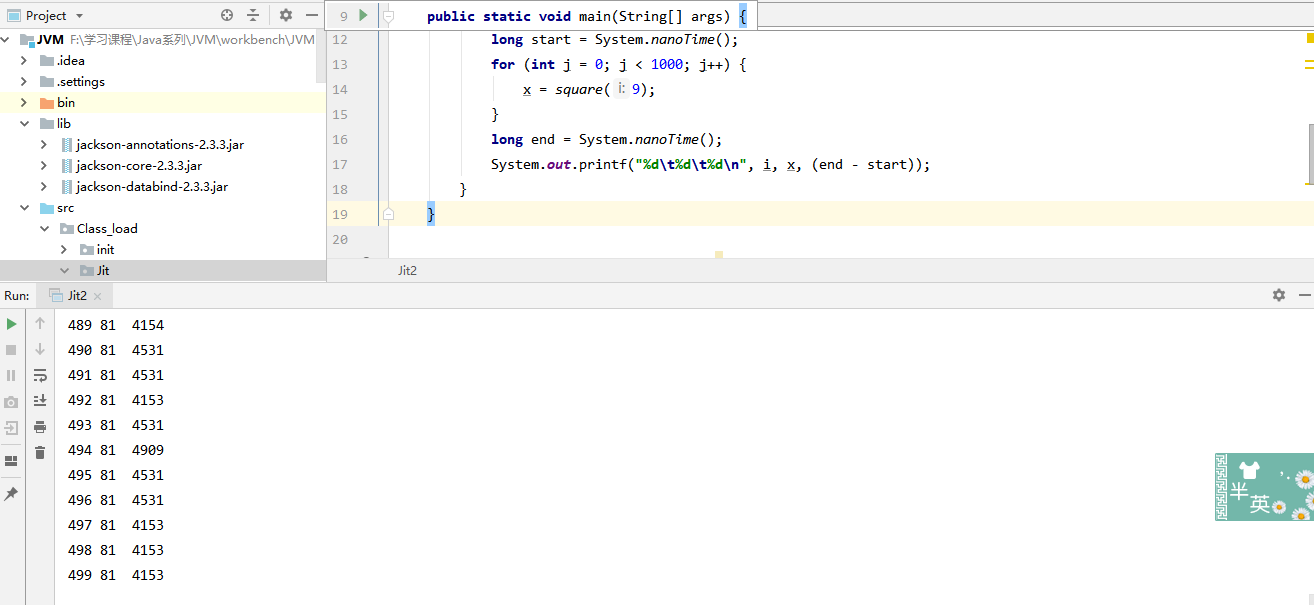
import java.util.Random;import java.util.concurrent.ThreadLocalRandom;public class Jit2 {public static void main(String[] args) {int x = 0;for (int i = 0; i < 500; i++) {long start = System.nanoTime();for (int j = 0; j < 1000; j++) {x = square(9);}long end = System.nanoTime();System.out.printf("%d\t%d\t%d\n", i, x, (end - start));}}private static int square(final int i) {return i * i;}}
运行代码可以发现在执行179次的时候用时第一次出现0,这个时候发现 square 是热点方法,并且长度不太长时,会进行内联,所谓的内联就是把方法内代码拷贝、粘贴到调用者的位置:
System.out.println(9 * 9);
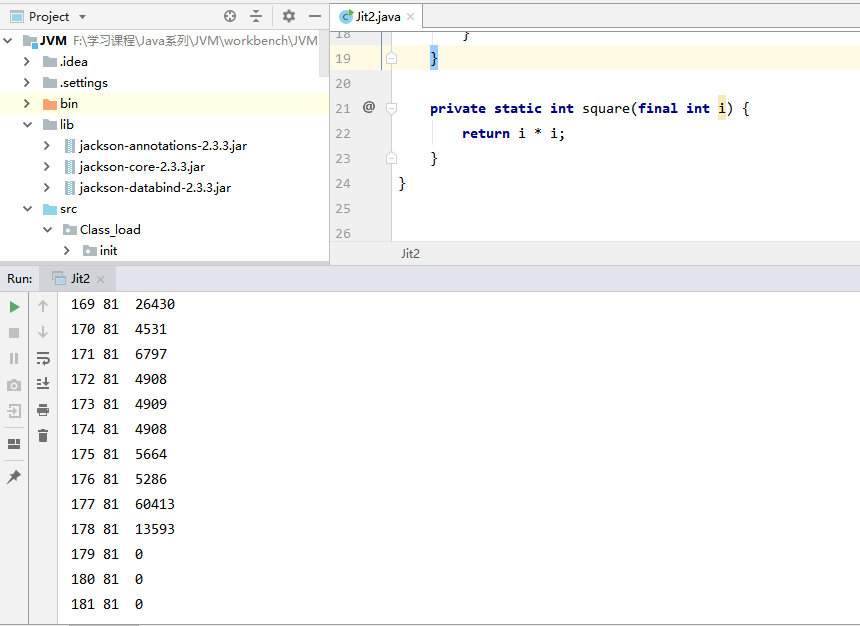
早这里我们可以使用JVM参数 -XX:+UnlockDiagnosticVMOptions -XX:+PrintInlining 查看内联方法和详细参数。运行代码查看,在@28的地方提示Squre方法进行了内联
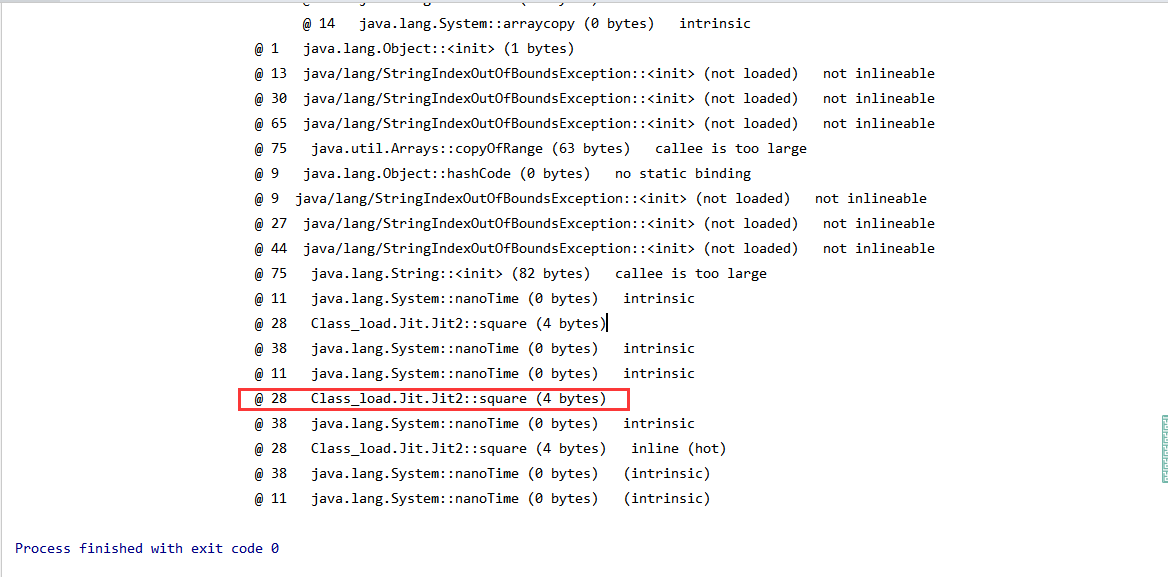
并且还可以使用一个参数 -XX:CompileCommand=dontinline,*Jit2.square 表示禁用方法内联,这个参数后面接上类名和方法名即可,再一次运行代码,会发现这个时候就不会出现时间为0的情况,因为在这个时候没有进行方法内联。
反射优化
使用以下代码段进行测试:
import java.io.IOException;import java.lang.reflect.InvocationTargetException;import java.lang.reflect.Method;public class Reflect {public static void foo() {System.out.println("foo...");}public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, IllegalAccessException, IOException {Method foo = Reflect.class.getMethod("foo");for (int i = 0; i <= 16; i++) {System.out.printf("%d\t", i);foo.invoke(null);}System.in.read();}}
foo.invoke 前面 0 ~ 15 次调用使用的是 MethodAccessor 的 NativeMethodAccessorImpl 实现
当调用到第 16 次(从0开始算)时,会采用运行时生成的类代替掉最初的实现。


































还没有评论,来说两句吧...