Ribbon(六) Ribbon源码分析 - IRULE负载均衡的实现
具体负载均衡服务还是由IRULE实现,在ribbon的使用案例中我们可以注意到切换具体的路由实现非常简单:
@RibbonClient(name = "MICROSERVICE-PROVIDER-PRODUCT", configuration = RibbonConfig.class)
通过 @RibbonClient指定负载均衡的实现类 RibbonConfig后,在这个类中创建具体实现算法即可.
public class RibbonConfig {@Beanpublic IRule ribbonRule() { // 其中IRule就是所有规则的标准return new com.netflix.loadbalancer.RandomRule(); // 随机的访问策略}}
那么如果不是自已像上面一样配置 RibbonConfig作为负载均衡的实现类的话,ribbon会自动提供一个默认实现。
让我们追踪一下 RibbonClientConfiguration 这个类,它位于包 org.springframework.cloud.netflix.ribbon 下, 它是Ribbon客户端的默认配置类。它里面加载了一系列的Ribbon所需的对象.其中就包括 IRule.
@Bean@ConditionalOnMissingBeanpublic IRule ribbonRule(IClientConfig config) {if (this.propertiesFactory.isSet(IRule.class, name)) {return this.propertiesFactory.get(IRule.class, config, name);}ZoneAvoidanceRule rule = new ZoneAvoidanceRule();rule.initWithNiwsConfig(config);return rule;}
从以上代码可以看出,加载的默认IRule实现是 ZoneAvoidanceRule, 让我们先来看一下IRule有哪些常用实现.
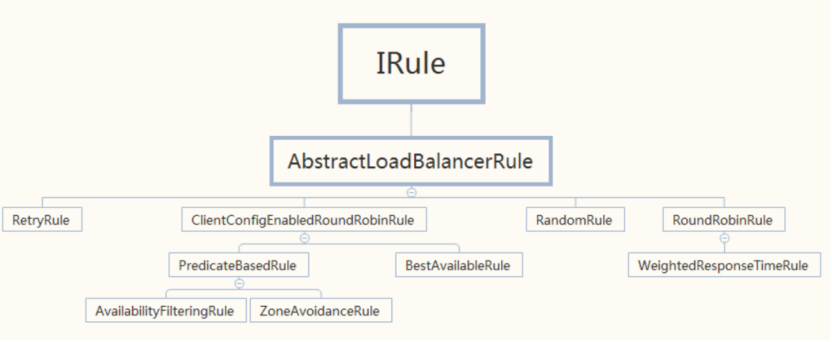
BestAvailableRule :会先过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务RoundRobinRule:默认算法,轮询
ClientConfigEnabledRoundRobinRule: 使用RoundRobinRule选择服务器
RetryRule: 先按照RoundRobinRule的策略获取服务,如果获取服务失败则在指定时间内会进行重试,获取可用的服务WeightedResponseTimeRule: 根据平均响应时间计算所有服务的权重,响应时间越快服务权重越大被选中的概率越高。刚启动时如果统计信息不足,则使用RoundRobinRule策略,等统计信息足够,会切换到WeightedResponseTimeRule
ZoneAvoidanceRule: 默认规则,复合判断server所在区域的性能和server的可用性选择服务器
- ZoneAvoidanceRule 的具体实现
ZoneAvoidanceRule是默认的IRule实例,他使用PredicateBasedRule来根据服务区的运行状况和服务器的可用性来选择服务器
它的父类是com.netflix.loadbalancer.PredicateBasedRule
它的choose()方法具体依次做了以下工作:
- 先使用ILoadBalancer 获取服务器列表
- 使用AbstractServerPredicate进行服务器过滤
最后轮询从剩余的服务器列表中选择最终的服务器
public abstract class PredicateBasedRule extends ClientConfigEnabledRoundRobinRule {
public abstract AbstractServerPredicate getPredicate();@Overridepublic Server choose(Object key) {ILoadBalancer lb = getLoadBalancer();//轮询Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key);if (server.isPresent()) {return server.get();} else {return null;}}
}
追踪 chooseRoundRobinAfterFiltering 方法,
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) {//根据loadBalancerKey获取可用服务器列表List<Server> eligible = getEligibleServers(servers, loadBalancerKey);if (eligible.size() == 0) {return Optional.absent();}// 这里面的 incrementAndGetModulo 是轮询的具体实现return Optional.of(eligible.get(incrementAndGetModulo(eligible.size())));}
incrementAndGetModulo方法的源码,它是轮询的具体实现: 至此,可以得出ZoneAvoidanceRule也是使用的轮询算法的结论.
// modulo 可用服务器列表数private int incrementAndGetModulo(int modulo) {for (;;) {int current = nextIndex.get();int next = (current + 1) % modulo;if (nextIndex.compareAndSet(current, next) && current < modulo)return current;}}
再回到上面的代码中 getPredicate()是一个抽象方法,具体在 ZoneAvoidanceRule中实现,请看下面的实现代码:
@Overridepublic AbstractServerPredicate getPredicate() {return compositePredicate; //请注意这里的 compositePredicate 是在下面的构造方法中初始化的.}public ZoneAvoidanceRule() {super();//判断一个服务器的运行状况是否可用,去除不可用服务器的所有服务器ZoneAvoidancePredicate zonePredicate = new ZoneAvoidancePredicate(this);//用于过滤连接数过多的服务器AvailabilityPredicate availabilityPredicate = new AvailabilityPredicate(this);compositePredicate = createCompositePredicate(zonePredicate, availabilityPredicate);}//将两个Predicate组合成一个CompositePredicateprivate CompositePredicate createCompositePredicate(ZoneAvoidancePredicate p1, AvailabilityPredicate p2) {return CompositePredicate.withPredicates(p1, p2).addFallbackPredicate(p2).addFallbackPredicate(AbstractServerPredicate.alwaysTrue()).build();}
接着再看另一个方法 chooseRoundRobinAfterFiltering, 它是过滤的方法,然后AvailabilityPredicate 里面并没有这方法,他直接继承了他的父类com.netflix.loadbalancer.AbstractServerPredicate#chooseRoundRobinAfterFiltering(java.util.List
public Optional<Server> chooseRoundRobinAfterFiltering(List<Server> servers, Object loadBalancerKey) {//过滤服务器列表List<Server> eligible = getEligibleServers(servers, loadBalancerKey);if (eligible.size() == 0) {return Optional.absent();}//(i+1)%n 轮询选择一个服务实例return Optional.of(eligible.get(incrementAndGetModulo(eligible.size())));}
查看一下 getEligibleServers()
public List<Server> getEligibleServers(List<Server> servers, Object loadBalancerKey) {//如果前面loadBalancerKey直接传入的null, 方法getEligibleServers会使用serverOnlyPredicate来依次过滤if (loadBalancerKey == null) {return ImmutableList.copyOf(Iterables.filter(servers, this.getServerOnlyPredicate()));} else {List<Server> results = Lists.newArrayList();for (Server server: servers) {if (this.apply(new PredicateKey(loadBalancerKey, server))) {results.add(server);}}return results;}}
追踪 getServerOnlyPredicate() , 会发现它返回的 serverOnlyPredicate 的创建代码如下:
//serverOnlyPredicate 则会调用apply方法,并将Server 对象分装PredicateKey当作参数传入private final Predicate<Server> serverOnlyPredicate = new Predicate<Server>() {@Overridepublic boolean apply(@Nullable Server input) {return AbstractServerPredicate.this.apply(new PredicateKey(input));}};
AbstractServerPredicate并没有实现apply方法,具体的实现又回到了子类CompositePredicate的apply方法,它会依次调用ZoneAvoidancePredicate(它以查看服务区是否可用为主)与AvailabilityPredicate(它看的是联接数是否达到可用)的apply方法. 两个类的算法实现不同.
那么首先看 ZoneAvoidancePredicate 的apply实现如下:
@Overridepublic boolean apply(@Nullable PredicateKey input) {if (!ENABLED.get()) {return true;}String serverZone = input.getServer().getZone();if (serverZone == null) {//如果服务器没有zone的相关信息,直接返回return true;}LoadBalancerStats lbStats = getLBStats();//LoadBalancerStats 存储每个服务器节点的执行特征和运行记录,这些信息可供动态负载均衡使用if (lbStats == null) {//如果没有服务器的运行状态的记录,直接返回return true;}if (lbStats.getAvailableZones().size() <= 1) {//如果只有就一个服务器,直接返回return true;}//PredicateKey 封装了Server的信息,判断下服务器区的记录是否用当前区的信息Map<String, ZoneSnapshot> zoneSnapshot = ZoneAvoidanceRule.createSnapshot(lbStats);//如果没有直接返回if (!zoneSnapshot.keySet().contains(serverZone)) {// The server zone is unknown to the load balancer, do not filter it outreturn true;}logger.debug("Zone snapshots: {}", zoneSnapshot);// 最重要的方法: 前面都是一些基本信息的判断 获取可用的服务器列表Set<String> availableZones = ZoneAvoidanceRule.getAvailableZones(zoneSnapshot, triggeringLoad.get(), triggeringBlackoutPercentage.get());logger.debug("Available zones: {}", availableZones);//判断当前服务器是否在可用的服务器列表中if (availableZones != null) {return availableZones.contains(input.getServer().getZone());} else {return false;}}
在上面代码中大量出现的ZoneSnapshot代码如下: 它用于封装zone快照信息
public class ZoneSnapshot {//实例数final int instanceCount;//平均负载final double loadPerServer;//断路器端口数量final int circuitTrippedCount;//活动请求数量final int activeRequestsCount;}
在这个代码: Set
public static Set<String> getAvailableZones(Map<String, ZoneSnapshot> snapshot, double triggeringLoad,double triggeringBlackoutPercentage) {if (snapshot.isEmpty()) { //服务区列表是空的,则返回空return null;}//只有一个区,则直接返回此 availableZonesSet<String> availableZones = new HashSet<String>(snapshot.keySet());if (availableZones.size() == 1) {return availableZones;}Set<String> worstZones = new HashSet<String>();double maxLoadPerServer = 0;boolean limitedZoneAvailability = false;//遍历所有的服务区for (Map.Entry<String, ZoneSnapshot> zoneEntry : snapshot.entrySet()) {String zone = zoneEntry.getKey();ZoneSnapshot zoneSnapshot = zoneEntry.getValue();//获取服务区中的服务实例数int instanceCount = zoneSnapshot.getInstanceCount();if (instanceCount == 0) {//如果服务区中没有服务实例,那么移除该服务区availableZones.remove(zone);limitedZoneAvailability = true;} else {//获取此服务区中的平均负载double loadPerServer = zoneSnapshot.getLoadPerServer();//服务区的实例平均负载小于0,或者实例故障率(断路器端口次数/实例数)大于等于阈值(默认0.99999),则去掉该服务区if (((double) zoneSnapshot.getCircuitTrippedCount())/ instanceCount >= triggeringBlackoutPercentage|| loadPerServer < 0) {availableZones.remove(zone);limitedZoneAvailability = true;} else {//如果该服务区的平均负载和最大负载的差小于一定的数量,则将该服务区加入到最坏服务区集合if (Math.abs(loadPerServer - maxLoadPerServer) < 0.000001d) {worstZones.add(zone);} else if (loadPerServer > maxLoadPerServer) {//如果该zone的平均负载还大于最大负载,也将此服务区加入到最坏服务区集合中maxLoadPerServer = loadPerServer;worstZones.clear();worstZones.add(zone);}}}}//如果最大的平均负载小于设定的阈值 , 则此服务区可以用,直接返回if (maxLoadPerServer < triggeringLoad && !limitedZoneAvailability) {return availableZones;}//否则,从最坏的服务区集合服务器集合里面随机挑选一个(没办法啊 )String zoneToAvoid = randomChooseZone(snapshot, worstZones);if (zoneToAvoid != null) {availableZones.remove(zoneToAvoid);}return availableZones;}
下面再谈谈AvailabilityPredicate(它看的是联接数是否达到可用) 的apply方法:
@Overridepublic boolean apply(@Nullable PredicateKey input) {LoadBalancerStats stats = getLBStats();if (stats == null) {return true;}//获得关于该服务器的记录return !shouldSkipServer(stats.getSingleServerStat(input.getServer()));}private boolean shouldSkipServer(ServerStats stats) {//如果该服务器的断路器已经打开,或者他的连接数大于设定的阈值,那么就需要将服务区过滤掉if ((CIRCUIT_BREAKER_FILTERING.get() && stats.isCircuitBreakerTripped())|| stats.getActiveRequestsCount() >= activeConnectionsLimit.get()) {return true;}return false;}
至此一个 IRule的实现类 ZoneAvoidanceRule的分析到此结束. 其它的实现方案可以自己去查看源码了.
小结: ZoneAvoidanceRule类从名字上看与RoundRobin没有什么关系,但仔细查看源码,还是可以看出它使用的就是轮询方案.


































还没有评论,来说两句吧...