案例---电商用户业务行为分析
1. 电商用户业务行为分析
电商平台中的用户行为频繁且较复杂,系统上线运行一段时间后,可以收集到大量的用户行为数据,进而利用数据分析技术进行深入挖掘和分析,得到感兴趣的商业指标并增强对风险的控制。
电商用户行为数据多样,整体可以分为用户行为习惯数据和业务行为数据两大类。
用户的行为习惯数据包括了用户的登录方式、上线的时间点及时长、点击和浏览页面、页面停留时间以及页面跳转等等,我们可以从中进行流量统计和热门商品的统计,也可以深入挖掘用户的特征;这些数据往往可以从web服务器日志中直接读取到。
而业务行为数据就是用户在电商平台中针对每个业务(通常是某个具体商品)所作的操作,我们一般会在业务系统中相应的位置埋点,然后收集日志进行分析。
业务行为数据又可以简单分为两类:一类是能够明显地表现出用户兴趣的行为,比如对商品的收藏、喜欢、评分和评价,我们可以从中对数据进行深入分析,得到用户画像,进而对用户给出个性化的推荐商品列表,这个过程往往会用到机器学习相关的算法;另一类则是常规的业务操作,但需要着重关注一些异常状况以做好风控,比如登录和订单支付。
2. 项目主要模块
基于对电商用户行为数据的基本分类,我们可以发现主要有以下三个分析方向:
1.热门统计
利用用户的点击浏览行为,进行流量统计、近期热门商品统计等。
2.偏好统计
利用用户的偏好行为,比如收藏、喜欢、评分等,进行用户画像分析,给出个性化的商品推荐列表。
3.风险控制
利用用户的常规业务行为,比如登录、下单、支付等,分析数据,对异常情况进行报警提示。
本项目限于数据,我们只实现以下三个需求:
- 用户的四种行为情况,用柱状图显示;
- 统计每天各行为的访问次数,并以折线图显示;
- 找出购买率最高的前二十个商品品类,并以柱状图展示
3. 数据源解析
我们准备了一份淘宝用户行为数据集,保存为csv文件。包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢),数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔;用户行为类型共有四种
*1. pv:商品详情页点击;
- buy:购买;
- cart:加入购物车;
- fav:收藏商品;*
4、需求的实现过程:
分析数据 —> 整理并清除异常数据 —> 实现需求
1、分析数据
数据有3个多G,全部读取耗费时间与内存,因此使用pandas的迭代读取方法,先获取前一万条数据,熟悉数据内容,并加入列名
import pandas as pduser_behavior = pd.read_csv('UserBehavior.csv',header=None,iterator=True)head_data = user_behavior.get_chunk(10000)head_data.head()
2、对数据进行整理、清洗
2.1、添加列名,数据特征分别是:用户ID,商品ID,商品类目ID,行为类型,时间戳
head_data.columns = ['user_id','goods_id','category_id','behaviour','timestamp']
2.2 查看是否有缺失值
head_data.info()
2.3、将时间戳转为时间格式,并新加一列time
head_data['time'] = pd.to_datetime(head_data['timestamp'],unit='s')
2.4、时间戳这列数据下面不会用到,可以删除掉
head_data = head_data.drop(['timestamp'],axis=1)
2.5、将time字段设为索引,目的是为了方便清除异常时间的数据
head_data.set_index('time',inplace=True)
2.6、数据是2017年11月25日至2017年12月3日之间,将异常时间的数据清洗掉
head_data = head_data['2017-11-25':'2017-12-3']
3、数据整理完,开始解决需求
需求1 : 统计用户的每个购物行为,思路:使用groupby进行分组并统计
count_by_user_behav = head_data.groupby(['user_id','behaviour']).count()count_by_user_behav.head()
只取一列次数,作为画图的Y轴值
count_by_user_behav = count_by_user_behav['goods_id']count_by_user_behav.head()
使用pandas自带的画图功能,因为用户很多,所以x轴就很长,双击图片可以放大
count_by_user_behav.plot(kind='bar', figsize=(150,10))

需求2 : 统计每天各行为的访问次数,并以折线图显示
# 接下来结合matplotlib画图from matplotlib import pyplot as plt%matplotlib inline# 设置画布尺寸plt.figure(figsize=(20, 8))# 以行为类型进行分组for group_name,group_data in head_data.groupby('behaviour'):# 对每天的行为进行统计,resample中的D表示天,也可以用H按小时统计count_by_day = group_data.resample('D').count()['behaviour']# 以日期作为X轴,以次数为y轴x = count_by_day.indexy = count_by_day.values课# 设置x,y轴数据以及每条线的标签名plt.plot(range(len(x)), y, label=group_name)# 设置x轴的刻标以及对应的标签,rotation是设置标签的倾斜度plt.xticks(range(len(x)), x, rotation=45)# 对每条折线的含义进行标注,自动选择最佳位置plt.legend(loc='best')可以清晰看出四种购物行为的走势图plt.show()
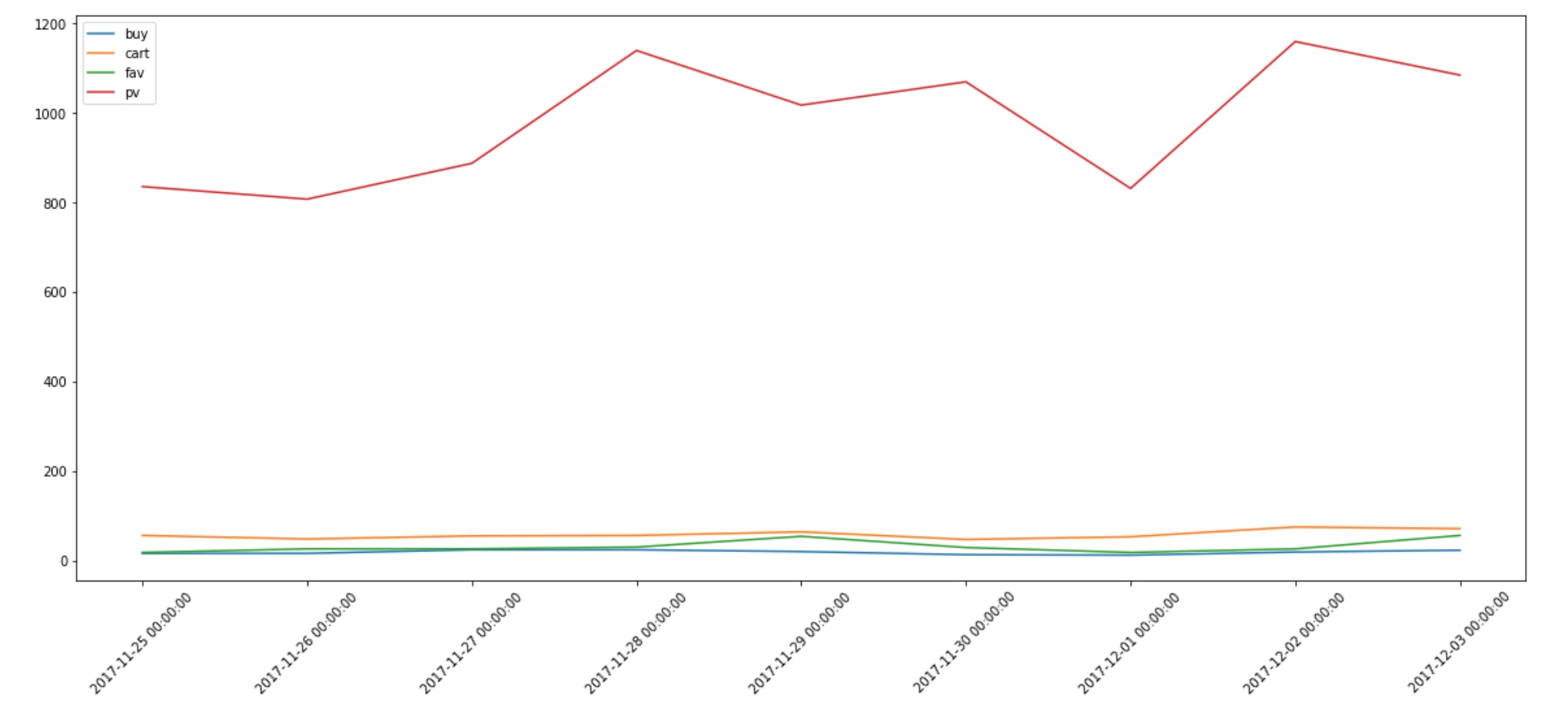
需求3 : 找出购买率最高的前二十个商品品类,并以柱状图展示
思路:按商品种类进行分组,购买率 = 购买次数/(访问+购物车+收藏+购买)
# 取消以时间为索引head_data = head_data.reset_index()# 按商品种类进行分组count_by_category_id = head_data.groupby('category_id')# 分组后每组数据的数量count_by_category_id.size()
看一下分组后的部分数据
for group_name,group_data in count_by_category_id:print('组名:',group_name)print('数据:')print(group_data)print(group_data.shape)break

思路:通过shape看出这组数据的形状为两行五列,因此可以直接用shape[0]作为购物的总次数使用,接下来再以behaviour分组,通过size属性,获取buy这一组的次数,最后将商品种类与购买率一一对应保存在字典中,使用内置函数sorted对字典进行排序
con_dict = { }中,使用内置函数sorted对字典进行排序# 总次数for group_name,group_data in count_by_category_id:total = group_data.shape[0]buy = 0try:# 有些商品没有购买行为,以buy作为索引获取时会出错,使用异常语句捕捉一下buy = group_data.groupby('behaviour').size()['buy']except:pass# 转化率convention = buy/total*100# 类别名称对应转化率con_dict[group_name] = convention# 排序sort_con = sorted(con_dict.items(),key=lambda item:item[1],reverse=True)# 对排好序的列表取值sort_con_20 = sort_con[:20]sort_con_20
sorted的用法: 第一个参数是进行排序的可迭代对象; key:主要是用来比较的元素,lambda函数的参数取自要排序的可迭代对象,指定可迭代对象中的元素进行排序; reverse:排序规则,默认升序,True表示降序;
前二十个商品种类及对应购买率如下,拿到这个,就可以使用matplotlib进行绘图了
# 获取所有的商品种类tick_label = [i[0] for i in sort_con_20]# 获取转化率num_list = [i[1] for i in sort_con_20]# 开始画图plt.figure(figsize=(20, 8))plt.bar(range(len(sort_con_20)), num_list,tick_label=tick_label)plt.show()



































还没有评论,来说两句吧...