大数据技术总体概括
1、知识点
1.1 RDBMS
Relational DataBase Magement System
关系型数据库管理系统
相关技术栈:SQL、SQL databases(MySQL、Postgres、Oracle等),Data Modeling(FB DE)
1.2 SQL
结构化查询语言
1.3 Batch ETL
Extract,Transform,Load
从数据仓库中提取数据,使用slicing和dicing规则去传输和加载数据到marts中。
1.4 data warehouse
数据仓库
与数据库DB的区别:
- 数据仓库用于从数据库中收集数据并进行优化和分析
- 数据库适用于OLTP(Online Transactional Process),数据仓库用于OLAP(Online Analytical Processing).
1.5 data marts
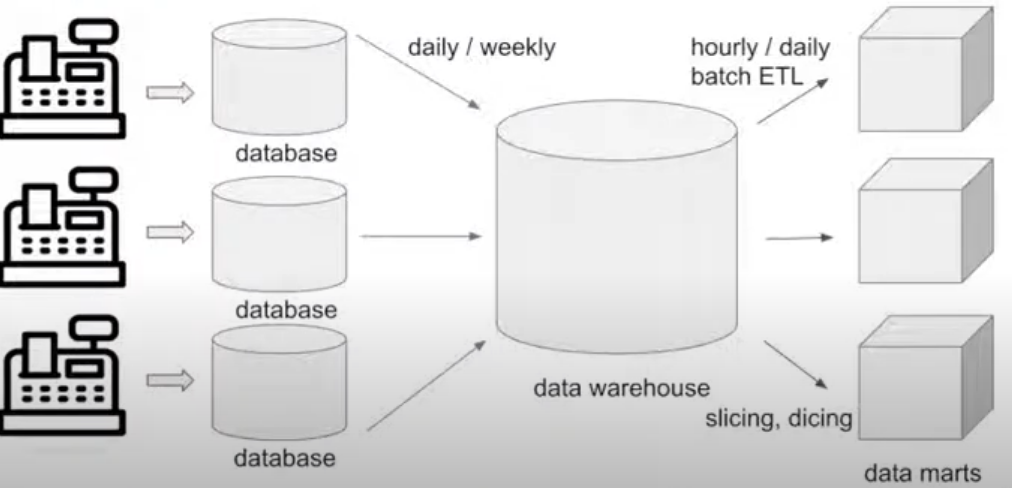
比如当一个公司有很多部门,每个部门信息存到一个数据库中,当要查询一个公司的某个信息的结果时,需要query所有的数据库。我们需要将数据库的数据放到数据仓库中,然后根据相关属性的限制条件进一步拆分为一个个小的DataMart。
DataMart是一个数据仓库的拆分,易于管理和更快的查询。
1.6 slicing和dicing
对数据库进行切分
1.7 dimension和metrics
每个分析查询是由dimension和metrics组成的。
dimension是数据的属性
Metrics是可以量化的结果。
例子:
每次超市购物产生一条含有 (超市名、各个商品名称、价格、时间)的记录,这是一条交易数据。以超市名为dimension,价格为metric,可以知道每家超市的销售额。以时间为dimension,商品名字为metric,就可以知道每天销售出的商品数量。
1.8 OLTP
Online Transactional Processing
- 可以在数据库中对数据进行增删改查
- 每个用户的操作只涉及极少量的数据操作,通常只涉及到一条记录。
1.9 OLAP
Online Analytical Processing
从多个维度分析数据
在讨论大数据时,主要讨论OLAP的情况。
OLAP大数据系统在推荐、预测、分类、分析、广告、流行话题等商业领域有广泛的应用。高盈利的服务产品大多来源于OLAP。
1.10 传统数据框架的不足
(1)大数据时代3V挑战
- Vaiety 多样化,除了传统的交易数据,用户数据外,用户行为、网页widgets上的操作、地图位置、声音图像等都会产生数据。传统的database无法解决。
- Velocity,数据会以极快的速度产生,例如用户的没一点浏览操作,划屏幕,点击等等,因此大数据需要具备收集和处理实时数据的能力。
- Volume,数据量变得空前的大,因此要有高效稳健的存储方式以及足够的空间,同时也能满足查询的需求。需要达到TB-PB级别。
(2)对实时数据进行OLAP处理(主要是creating和querying)的需求。 - 以天、小时为粒度的数据不能满足即时查询的需求
- 例如:当前微博话题热度排行,过去半小时爆款文章的阅读量
- 要有low latency,以分甚至秒的粒度来进行数据处理和查询。
- 实时(非实时)
stream data(batch)
online data(offline)
low latency data(hourly/daily)
(3)数据分析产品和业务服务于全球用户 - 多元化
- 数据量多
- 稳定性高、用户规模大
2、大数据知识架构
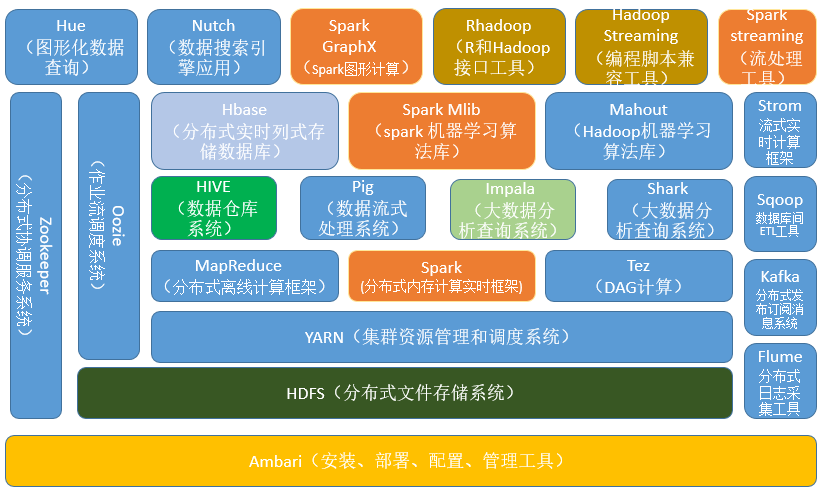
2.1 数据采集和传输层
- Kafka
分布式消息系统,生产者(producer)——消费者(consumer)模型。提供了类似于JMS的特性,但设计上完全不同,不遵循JMS规范。比如Kafka允许多个消费者主动拉取数据,然而JMS中只有点对点模式消费者才会主动拉数据。主要应用在数据缓冲、异步通信、汇集数据、系统接偶等方面。 - Pulsar
pub-sub模式的分布式消息平台,拥有灵活的消息模型和直观的客户端API。类似Kafka,但是Pulsar支持多租户,有着资产和命名空间的概念,资产代系统里的租户。 - Sqoop
Sqoop主要通过一组命令进行数据导入导出的工具,底层引擎依赖MapReduce,主要用于Hadoop(如HDFS、Hive、HBase)和RDBMS(mysql、orcle)之间的数据导入和导出。
2.2 数据存储层
- Hbase
基于Google Bigtable的开源实现,是一个具有高可靠性、高性能、面向列、可伸缩性、典型的key/value分布式存储的nosql数据库系统,主要用于海量结构化和半结构化数据存储。它介于nosql和RDBMS之间,仅能通过行键(row key)和行键的range来检索数据,行数据存储是原子性的,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。HBase查询数据功能简单,不支持join等复杂操作,不支持跨行和跨表事务。 - HDFS
分布式文件存储系统,具有高容错(high fault-tolerant)、高吞吐(high throughput)、高可用(high avaliable)的特性。非常适合在大规模数据集上的应用,提供高吞吐量的数据访问。 可部署在廉价的机器上。它放宽了POSIX的要求,这样可以实现流的形式访问(文件系统中的数据),主要为各类分布式计算框架如Spark、MapReduce等提供海量数据存储服务。 - Kudu
介于HDFS和HBase之间的基于列式存储的分布式数据库,兼具了HBase的实时性、HDFS的高吞吐,传统数据库的sql支持。
2.3 数据分析层
- Spark
Spark是一个快速、通用、可扩展、可容错、内存迭代式计算的大数据分析引擎。目前生态体系主要包括用于批处理的SparkRDD、SparkSQL、用于流数据处理的SparkStreaming、Structured-Streaming。用于机器学习的Spark MLLib,用于图计算的Graphx以及用于统计分析的SparkR,支持Java,Scala,Python等多种语言。 - Flink
分布式大数据处理引擎,可以对有限数据流和无限数据流进行有状态的计算,Flink在设计之初就是以流为基础发展的,然后再进入批处理领域,相对spark而言,它是一个真正意义上的实时计算引擎。 - Strom
由Twitter开源后归于Apache管理的分布式实时计算系统,Strom是一个没有批处理能力的数据流计算引擎,strom提供了偏底层的API,用户需要自己实现很多复杂的逻辑。 - MapReduce
分布式运算程序的编程框架,适用于离线数据处理场景,内部处理流程主要划分map和reduce两个阶段。 - Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供HQL语句查询功能,存储依赖于HDFS,支持多种计算引擎,如Spark、MapReduc、Tez;支持多种存储格式,如TextFile、SwquenceFile、RCFile、ORC、Parquet(常用);支持多种压缩格式,如gzip、lzo、bzip2等。 - Tez
支持DAG作业的开源计算框架。相对于MapReduce性能更好,主要原因在于其将作业描述为DAG(有向无环图),与 - Pig
基于Hadoop的大规模数据分析平台,它包含了一种名为Pig Latin的脚本语言来描述数据流,并行地执行数据流处理的引擎,为复杂的海量数据并行计算提供了一个简单的操作和编程接口。
Pig Latin本身提供了很多传统的数据操作,同时允许用户自己开发一些自定义函数来读取、处理和写数据。该语言的编译器会把类SQL的数据分析请求转化为一系列经过优化处理的MapReduce运算。
2.4 OLAP引擎
- Druid
基于列存储的、分布式的、适用于实时数据分析的存储系统,能够快速聚合、灵活过滤、毫秒级查询和低延迟数据导入。通过使用Bitmap indexing加速存储的查询速度,并使用CONCISE算法来对bitmap indexing进行压缩,使得生成的segments比原始文件小很多,并且它的各个组成部分支架耦合性低,如果不需要实时数据可以忽略实时节点。 - kylin
分布式分析引擎。提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力以支持超大规模数据,它能在亚秒内查询巨大的Hive表,需要使用者对数据仓库模型有深度了解,并需构建cube,能够与多种可视化工具,如Tableau,PowerBI等,令用户可以使用BI工具对Hadoop数据进行分析。 - Impala
提供对HDFS、HBase等数据的高性能,低延迟的交互式SQL查询功能的大数据查询分析引擎,由Cloudera开源。它基于Hive,使用Hive的元数据在内存中计算,具有实时,批处理,高并发等优点。 - Presto
开源的分布式大数据SQL查询引擎,适用于交互式分析查询,可以将多个数据源的数据进行合并,并且可以直接从HDFS读取数据,并在使用前不需要大量的ETL操作。
2.5 资源管理层
- Yarn
一个资源调度平台,负责为运算程序分配资源和调度,不参与用户程序内部工作,核心组件包括:ResourceManager(全局资源管理器,负责整个系统的资源管理和分配)、Nodemanager(每个节点上的资源和任务管理器)。 - Mesos
- Kubernetes
2.6 工作流调度器
- Oozie
基于工作流引擎的任务调度框架,能够提供对MapReduce和Pig任务的调度与协调。 - Azkban
相对Oozie更轻量级,用于在一个工作流内以一个特定顺序运行一组任务,通过一种kv文件格式来建立任务之间的依赖关系,并为用户提供了易于使用的web界面来维护和跟踪允许任务的工作流。
2.7 分布式协调框架
- Ambari
基于web的安装部署工具,支持对大多数的hadoop组件,如HDFS、MapReduce、Hive、Pig等的管理和监控。 - Zookeeper
分布式协调服务即为用户的分布式应用程序提供协调服务,如主从协调,服务器节点动态上下线,统一配置管理,分布式共享锁等,它本身也是一个分布式程序。
3 业界主流大数据体系
业界目前主流的大数据基础架构和组件,主要围绕在Hadoop/Spark为核心的开源生态体系:
- 数据收集层:主要由关系型与非关系型数据收集组件,以及分布式消息队列构成。
- 数据存储层:主要由分布式文件系统(面向文件的存储)和分布式数据库(面向行/列的存储)构成。
- 资源管理与服务协调层
- 计算引擎层:包含批处理,交互式处理和流式实时处理三类引擎。
- 数据分析层:提供了各种大数据分析工具。
参考:
https://www.youtube.com/watch?v=9YsAfWRzl2w
https://zhuanlan.zhihu.com/p/68451233
https://zhuanlan.zhihu.com/p/112688499
https://zhuanlan.zhihu.com/p/95926504
https://www.youtube.com/watch?v=YKUa5xrkQGQ






























、methods、watch的区别")



还没有评论,来说两句吧...