TensorFlow笔记(四)——数据读取(一)
Tensorflow读取数据的一般方式有下面3种:
- preloaded直接创建变量:在tensorflow定义图的过程中,创建常量或变量来存储数据(仅适用于数据量比较小的情况)。
- 供给数据(feed): 在TensorFlow程序运行的每一步/在运行程序时,通过feed_dict传入数据
- reader从文件中读取数据:在tensorflow图开始时,通过一个输入管线从文件中读取数据
一、Preloaded方法的简单例子
import tensorflow as tf"""定义常量"""const_var = tf.constant([1, 2, 3])"""定义变量"""var = tf.Variable([1, 2, 3])with tf.Session() as sess:sess.run(tf.global_variables_initializer())print(sess.run(var))print(sess.run(const_var))
二、Feed方法
可以在tensorflow运算图的过程中,将数据传递到事先定义好的placeholder中。方法是在调用session.run函数时,通过feed_dict参数传入。简单例子:
import tensorflow as tf"""定义placeholder"""x1 = tf.placeholder(tf.int16)x2 = tf.placeholder(tf.int16)result = x1 + x2"""定义feed_dict"""feed_dict = {x1: [10],x2: [20]}"""运行图"""with tf.Session() as sess:print(sess.run(result, feed_dict=feed_dict))当数据量较小时,可能一般选择直接将数据加载进内存,然后再分`batch`输入网络进行训练(tip:使用这种方法时,结合`yield` 使用更为简洁,大家自己尝试一下吧,我就不赘述了)。但是,如果数据量较大,这样的方法就不适用了,因为太耗内存,所以这时最好使用tensorflow提供的队列`queue`,也就是第三种方法 **从文件读取数据**。对于一些特定的读取,比如csv文件格式,官网有相关的描述,在这儿我介绍一种比较通用,高效的读取方法(官网介绍的少),即使用tensorflow内定标准格式——`TFRecords`
TFRecords
TFRecords其实是一种二进制文件,虽然它不如其他格式好理解,但是它能更好的利用内存,更方便复制和移动,并且不需要单独的标签文件(等会儿就知道为什么了)… …总而言之,这样的文件格式好处多多,所以让我们用起来吧。TFRecords文件包含了`tf.train.Example` 协议内存块(protocol buffer)(协议内存块包含了字段 `Features`)。我们可以写一段代码获取你的数据, 将数据填入到`Example`协议内存块(protocol buffer),将协议内存块序列化为一个字符串, 并且通过`tf.python_io.TFRecordWriter` 写入到TFRecords文件。从TFRecords文件中读取数据, 可以使用`tf.TFRecordReader`的`tf.parse_single_example`解析器。这个操作可以将`Example`协议内存块(protocol buffer)解析为张量。
三、从文件中读取数据
![424966-20180206225745388-699164490.png][]图引用自 https://zhuanlan.zhihu.com/p/27238630
步骤:
- 获取文件名列表list
- 创建文件名队列,调用tf.train.string_input_producer,参数包含:文件名列表,num_epochs【定义重复次数】,shuffle【定义是否打乱文件的顺序】
- 定义对应文件的阅读器>* tf.ReaderBase >* tf.TFRecordReader >* tf.TextLineReader >* tf.WholeFileReader >* tf.IdentityReader >* tf.FixedLengthRecordReader
- 解析器 >* tf.decode_csv >* tf.decode_raw >* tf.image.decode_image >* …
- 预处理,对原始数据进行处理,以适应network输入所需
- 生成batch,调用tf.train.batch() 或者 tf.train.shuffle_batch()
- prefetch【可选】使用预加载队列slim.prefetch_queue.prefetch_queue()
- 启动填充队列的线程,调用tf.train.start_queue_runners
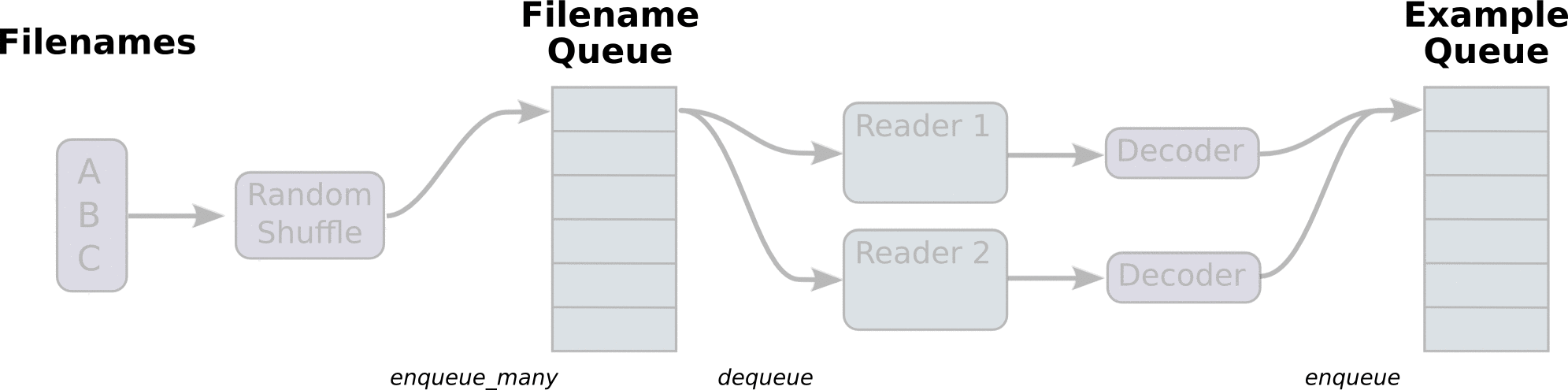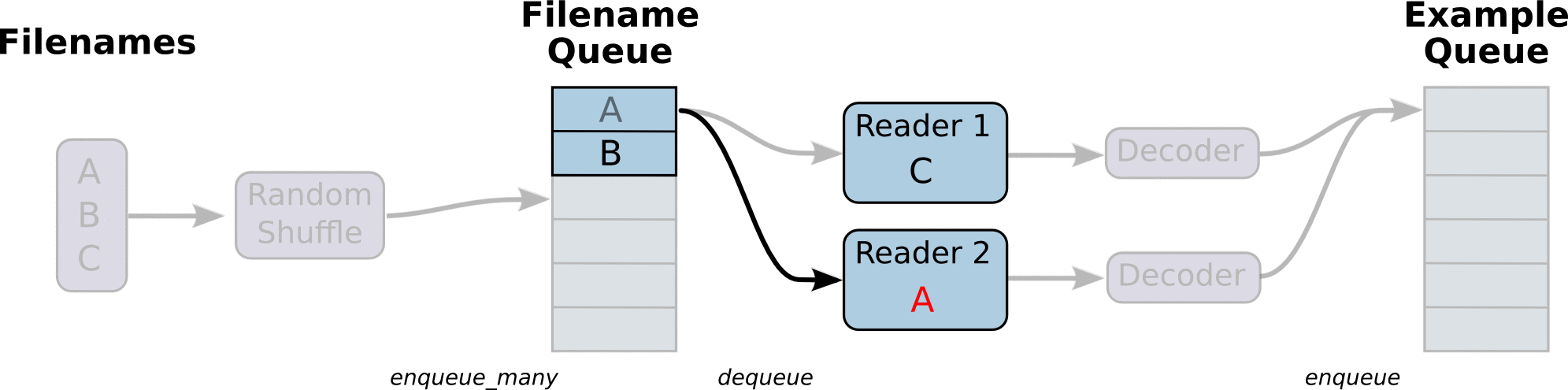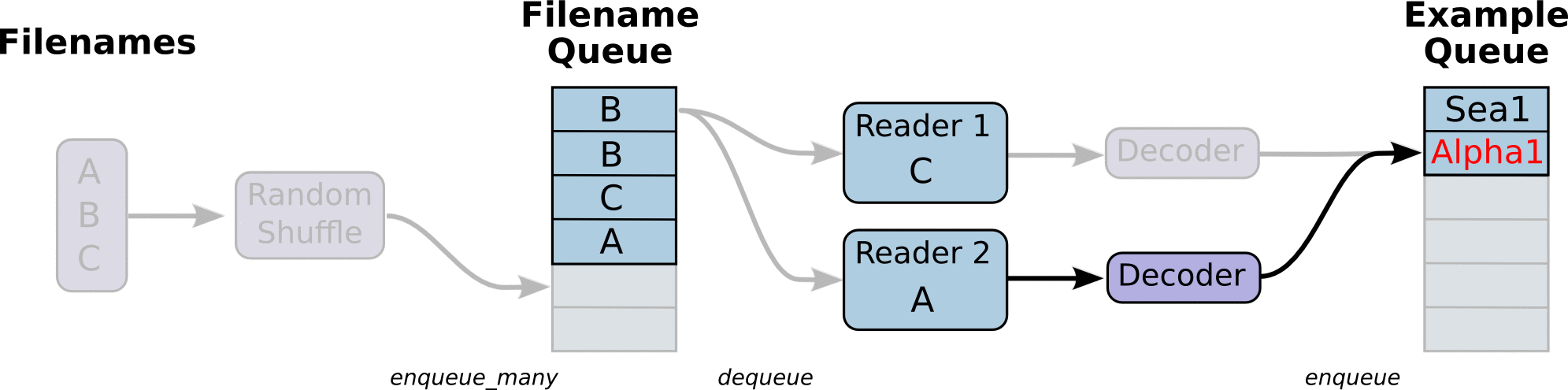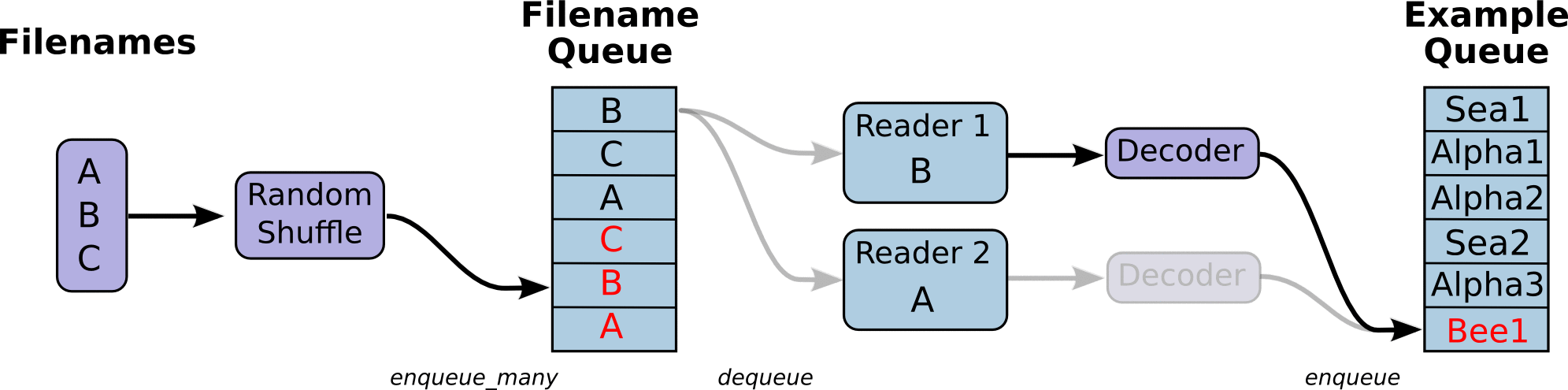
图引用自http://www.yyliu.cn/post/89458415.html
原文地址:https://zhuanlan.zhihu.com/p/27238630
四、tensorflow读文件的读取机制图解
首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示:
![Image 1][]
假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg……我们只需要把它们读取到内存中,然后提供给GPU或是CPU进行计算就可以了。这听起来很容易,但事实远没有那么简单。事实上,我们必须要把数据先读入后才能进行计算,假设读入用时0.1s,计算用时0.9s,那么就意味着每过1s,GPU都会有0.1s无事可做,这就大大降低了运算的效率。
如何解决这个问题?方法就是将读入数据和计算分别放在两个线程中,将数据读入内存的一个队列,如下图所示:
![Image 1][]
读取线程源源不断地将文件系统中的图片读入到一个内存的队列中,而负责计算的是另一个线程,计算需要数据时,直接从内存队列中取就可以了。这样就可以解决GPU因为IO而空闲的问题!
而在tensorflow中,为了方便管理,在内存队列前又添加了一层所谓的“文件名队列”。
为什么要添加这一层文件名队列?我们首先得了解机器学习中的一个概念:epoch。对于一个数据集来讲,运行一个epoch就是将这个数据集中的图片全部计算一遍。如一个数据集中有三张图片A.jpg、B.jpg、C.jpg,那么跑一个epoch就是指对A、B、C三张图片都计算了一遍。两个epoch就是指先对A、B、C各计算一遍,然后再全部计算一遍,也就是说每张图片都计算了两遍。
tensorflow使用文件名队列+内存队列双队列的形式读入文件,可以很好地管理epoch。下面我们用图片的形式来说明这个机制的运行方式。如下图,还是以数据集A.jpg, B.jpg, C.jpg为例,假定我们要跑一个epoch,那么我们就在文件名队列中把A、B、C各放入一次,并在之后标注队列结束。
![Image 1][]
程序运行后,内存队列首先读入A(此时A从文件名队列中出队):
![Image 1][]
再依次读入B和C:
![Image 1][]
![Image 1][]
此时,如果再尝试读入,系统由于检测到了“结束”,就会自动抛出一个异常(OutOfRange)。外部捕捉到这个异常后就可以结束程序了。这就是tensorflow中读取数据的基本机制。如果我们要跑2个epoch而不是1个epoch,那只要在文件名队列中将A、B、C依次放入两次再标记结束就可以了。
五、tensorflow读取数据机制的对应函数
如何在tensorflow中创建上述的两个队列呢?
对于文件名队列,我们使用tf.train.string_input_producer函数。这个函数需要传入一个文件名list,系统会自动将它转为一个文件名队列。
此外tf.train.string_input_producer还有两个重要的参数,一个是num_epochs,它就是我们上文中提到的epoch数。另外一个就是shuffle,shuffle是指在一个epoch内文件的顺序是否被打乱。若设置shuffle=False,如下图,每个epoch内,数据还是按照A、B、C的顺序进入文件名队列,这个顺序不会改变:
![Image 1][]
如果设置shuffle=True,那么在一个epoch内,数据的前后顺序就会被打乱,如下图所示:
![Image 1][]
在tensorflow中,内存队列不需要我们自己建立,我们只需要使用reader对象从文件名队列中读取数据就可以了,具体实现可以参考下面的实战代码。
除了tf.train.string_input_producer外,我们还要额外介绍一个函数:tf.train.start_queue_runners。初学者会经常在代码中看到这个函数,但往往很难理解它的用处,在这里,有了上面的铺垫后,我们就可以解释这个函数的作用了。
在我们使用tf.train.string_input_producer创建文件名队列后,整个系统其实还是处于“停滞状态”的,也就是说,我们文件名并没有真正被加入到队列中(如下图所示)。此时如果我们开始计算,因为内存队列中什么也没有,计算单元就会一直等待,导致整个系统被阻塞。
![Image 1][]
而使用tf.train.start_queue_runners之后,才会启动填充队列的线程,这时系统就不再“停滞”。此后计算单元就可以拿到数据并进行计算,整个程序也就跑起来了,这就是函数tf.train.start_queue_runners的用处。
![Image 1][]
六、实战代码
我们用一个具体的例子感受tensorflow中的数据读取。如图,假设我们在当前文件夹中已经有A.jpg、B.jpg、C.jpg三张图片,我们希望读取这三张图片5个epoch并且把读取的结果重新存到read文件夹中。
![Image 1][]
对应的代码如下:
# 导入tensorflowimport tensorflow as tf# 新建一个Sessionwith tf.Session() as sess:# 我们要读三幅图片A.jpg, B.jpg, C.jpgfilename = ['A.jpg', 'B.jpg', 'C.jpg']# string_input_producer会产生一个文件名队列filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)# reader从文件名队列中读数据。对应的方法是reader.readreader = tf.WholeFileReader()key, value = reader.read(filename_queue)# tf.train.string_input_producer定义了一个epoch变量,要对它进行初始化tf.local_variables_initializer().run()# 使用start_queue_runners之后,才会开始填充队列threads = tf.train.start_queue_runners(sess=sess)i = 0while True:i += 1# 获取图片数据并保存image_data = sess.run(value)with open('read/test_%d.jpg' % i, 'wb') as f:f.write(image_data)
我们这里使用filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)建立了一个会跑5个epoch的文件名队列。并使用reader读取,reader每次读取一张图片并保存。
运行代码后,我们得到就可以看到read文件夹中的图片,正好是按顺序的5个epoch:
![Image 1][]
如果我们设置filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=5)中的shuffle=True,那么在每个epoch内图像就会被打乱,如图所示:
![Image 1][]
我们这里只是用三张图片举例,实际应用中一个数据集肯定不止3张图片,不过涉及到的原理都是共通的。
作者:cheerss
链接:https://www.jianshu.com/p/c83eedce50c9
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
关于Tensorflow 的数据读取环节:https://www.cnblogs.com/bicker/p/8424538.html
[Image 1]:




























还没有评论,来说两句吧...