《Involution:Inverting the Inherence of Convolution for Visual Recognition》论文笔记
参考代码:involution
1. 概述
导读:CNN操作已经被广泛使CV领域,其具有空间无关性(spatial-agnostic)和通道特异性(channel-specific),前一个性质来源于在空间尺度上共享卷积参数,后一个性质来自于输出通道维度上的参数各不相同。在这篇文章中提出了一种性质与之相反的操作involution,通过学习的方式去得到卷积参数,之后经过维度变换之后与unfold之后的特征进行multiply-add,从而得到最后的输出结果,这里用到的multiply-add操作可以看作是self-attention的一种形式。因而整体上文章提出的involution操作具有了空间特异性和通道无关性,并且融合了self-attention的特性。以文章的操作作为基础模块去构建检测/分割任务网络,均在原来的基础上具有较大提升,而且由于这个操作本身的特性,使得其参数量/计算量有所减少。
现有的很多网络结构都是设计在算子CNN基础上的,其具有空间无关性与通道特异性,首先对这两个特性进行分析:
- 1)空间无关性:CNN算子中使用相同的参数在空间维度上进行滑动运算保证计算效率,同时也满足了平移不变性的需求。但是这样的方式却使得卷积核在不同空间位置上对于不同视觉任务的适应能力不足,而且其局部特性也限制了其感受野(增大感受野多是 3 ∗ 3 3*3 3∗3卷积的堆叠,而不是直接上采用大尺寸的卷积核);
- 2)通道特异性:这里通过在输出通道上使用不同的卷积核从而使得网络中的信息被编码到了不同的channel中去。其实这样的形式是比较冗余的,文章后面的实验也表明通过分组的形式共享卷积参数,在一定的范围内对性能的影响很小,因而通道中存在较多的冗余;
对此文章提出了新的算子involution操作,通过算子设计将CNN的空间无关性和通道特异性进行对调,从而可以在相同条件下相比CNN算子减少计算量和参数量(后面内容会对其进行比较)。相比传统CNN算子新算子具有如下优点:
- 1)由于CNN算子参数量和计算量的原因,不能使用较大尺寸的卷积核,多是使用多个小卷积核堆叠的形式实现增大感受野。而由于文章的算子相对起来更加轻量化,这就使得可以使用更大尺寸的卷积核,从而增加会上下文信息的获取能力;
- 2)involution算子在优化的过程中不仅仅优化卷积核参数,还优化生成卷积核参数的参数(可能会对网络的训练带来一定难度,需实际验证),之后通过在空间维度上进行mutiply-add操作实现,卷积结果的加权组合,实现类似self-attention的范式,但相对self-attention操作省去了位置编码的部分;
2. 方法设计
2.1 回顾传统卷积操作
假定输入的特征图 X ∈ R H ∗ W ∗ C i X\in R^{H*W*C_i} X∈RH∗W∗Ci,输出的通道数量为 C o C_o Co,则需要使用到的卷积核为 f ∈ R C o ∗ C i ∗ K ∗ K \mathcal{f}\in R^{C_o*C_i*K*K} f∈RCo∗Ci∗K∗K,这里 K K K是卷积核的大小。经过卷积之后输出的特征描述为:
Y i , j , k = ∑ c = 1 C i ∑ ( u , v ) ∈ Δ k f k , c , u + ⌊ K 2 ⌋ , v + ⌊ K 2 ⌋ X i + u , j + v , c Y_{i,j,k}=\sum_{c=1}^{C_i}\sum_{(u,v)\in\Delta_k}\mathcal{f}_{k,c,u+\lfloor\frac{K}{2}\rfloor,v+\lfloor\frac{K}{2}\rfloor}X_{i+u,j+v,c} Yi,j,k=c=1∑Ci(u,v)∈Δk∑fk,c,u+⌊2K⌋,v+⌊2K⌋Xi+u,j+v,c
在一些情况下会使用卷积分组的形式共享卷积参数,从而减少计算量和参数量(其中深度卷积就是其中的极端例子)。则一个分组进行卷积其计算过程可以描述为:
Y i , j , k = ∑ ( u , v ) ∈ Δ K g k , u + ⌊ K 2 ⌋ , v + ⌊ K 2 ⌋ X i + u , j + v , k Y_{i,j,k}=\sum_{(u,v)\in\Delta_K}\mathcal{g}_{k,u+\lfloor\frac{K}{2}\rfloor,v+\lfloor\frac{K}{2}\rfloor}X_{i+u,j+v,k} Yi,j,k=(u,v)∈ΔK∑gk,u+⌊2K⌋,v+⌊2K⌋Xi+u,j+v,k
其中 k k k表示的是对应的分组切片。
2.2 involution操作
文章提出的新算子involution其操作流程可以参考下图: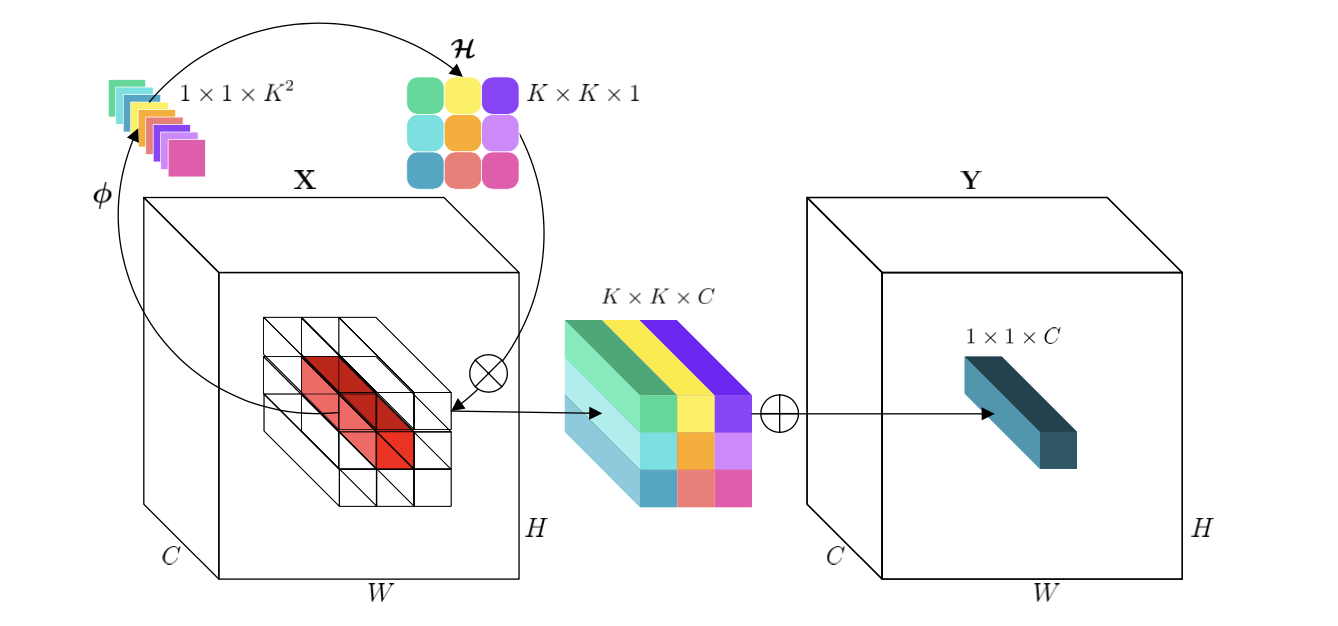
如上图所示,算法首先会在空间维度上对每个像素位置生成 K 2 K^2 K2个卷积参数,在具体实现中,是通过卷积的形式实现的,其数学表达描述为:
H i , j = ϕ ( X i , j ) = W 1 σ ( W o X i , j ) \mathcal{H}_{i,j}=\phi(X_{i,j})=W_1\sigma(W_oX_{i,j}) Hi,j=ϕ(Xi,j)=W1σ(WoXi,j)
这里 X i , j X_{i,j} Xi,j代表的是空间维度上某个点的向量, W 0 ∈ R C r ∗ C ∗ 1 ∗ 1 , W 1 ∈ R ( K ∗ K ∗ G ) ∗ C r ∗ 1 ∗ 1 W_0\in R^{\frac{C}{r}*C*1*1},W_1\in R^{(K*K*G)*\frac{C}{r}*1*1} W0∈RrC∗C∗1∗1,W1∈R(K∗K∗G)∗rC∗1∗1, r r r是通道缩减比例。之后会对生成的卷积参数展平与分组,再与输入的特征(经过unfolf操作)进行Multiply-Add操作,其中一个分组的运算描述为:
Y i , j , k = ∑ ( u , v ) ∈ Δ K H i , j , u + ⌊ K 2 ⌋ , v + ⌊ K 2 ⌋ , ⌈ k G C ⌉ X i + u , j + v , k Y_{i,j,k}=\sum_{(u,v)\in\Delta_K}\mathcal{H}_{i,j,u+\lfloor\frac{K}{2}\rfloor,v+\lfloor\frac{K}{2}\rfloor,\lceil\frac{kG}{C}\rceil}X_{i+u,j+v,k} Yi,j,k=(u,v)∈ΔK∑Hi,j,u+⌊2K⌋,v+⌊2K⌋,⌈CkG⌉Xi+u,j+v,k
下面的伪代码很好展示了其计算的流程:
# B: batch size, H: height, W: width# C: channel number, G: group number# K: kernel size, s: stride, r: reduction ratio################### initialization ###################o = nn.AvgPool2d(s, s) if s > 1 else nn.Identity() reduce = nn.Conv2d(C, C//r, 1)span = nn.Conv2d(C//r, K*K*G, 1)unfold = nn.Unfold(K, dilation, padding, s)#################### forward pass ####################x_unfolded = unfold(x) # B,CxKxK,HxWx_unfolded = x_unfolded.view(B, G, C//G, K*K, H, W)# kernel generation, Eqn.(6)kernel = span(reduce(o(x))) # B,KxKxG,H,Wkernel = kernel.view(B, G, K*K, H, W).unsqueeze(2) # B, G, 1, K*K, H, W# Multiply-Add operation, Eqn.(4)out = mul(kernel, x_unfolded).sum(dim=3) # B,G,C/G,H,W out = out.view(B, C, H, W)return out
involution和CNN参数量和计算量比较:
在输入和输出通道都为 C C C,卷积核都为 K K K的情况下对这两个操作进行比较,得出对比如下:
- 1)参数量:按照上面给出的计算流程,involution的参数包含与卷积参数的生成部分,因而总的参数量为:
P i = 1 ∗ 1 ∗ C ∗ C r + 1 ∗ 1 ∗ C r ∗ G ∗ K 2 = C 2 + C G K 2 r P_i=1*1*C*\frac{C}{r}+1*1*\frac{C}{r}*G*K^2=\frac{C^2+CGK^2}{r} Pi=1∗1∗C∗rC+1∗1∗rC∗G∗K2=rC2+CGK2
而传统卷积的参数量描述为:
P c = C ∗ C ∗ K ∗ K = C 2 ∗ K 2 P_c=C*C*K*K=C^2*K^2 Pc=C∗C∗K∗K=C2∗K2 - 2)计算量比较:involution的操作中浮点数乘法数量包含卷积阐述生成部分和multiply部分,计算量描述为:
F i = H ∗ W ∗ C r ∗ C ∗ 1 ∗ 1 + H ∗ W ∗ C r ∗ G ∗ K 2 ∗ 1 ∗ 1 + C ∗ K 2 ∗ W ∗ H = H ∗ W ∗ C ∗ C + G K 2 + r K 2 r F_i=H*W*\frac{C}{r}*C*1*1+H*W*\frac{C}{r}*G*K^2*1*1+C*K^2*W*H=H*W*C*\frac{C+GK^2+rK^2}{r} Fi=H∗W∗rC∗C∗1∗1+H∗W∗rC∗G∗K2∗1∗1+C∗K2∗W∗H=H∗W∗C∗rC+GK2+rK2
而传统卷积的计算量为:
F c = C ∗ C ∗ K ∗ K ∗ H ∗ W = C 2 ∗ K 2 ∗ H ∗ W F_c=C*C*K*K*H*W=C^2*K^2*H*W Fc=C∗C∗K∗K∗H∗W=C2∗K2∗H∗W
RedNet网络:
这里通过CNN算子替换为involution算子的形式,将ResNet中的部分CNN算子替换为卷积核尺寸为 3 ∗ 3 3*3 3∗3或 7 ∗ 7 7*7 7∗7大小的involution算子,但保留了其中的 1 ∗ 1 1*1 1∗1大小的映射核融合CNN操作,从而头肩构建RedNet网络,将文章的方法与其它的一些新Backbone进行比较,结果如下: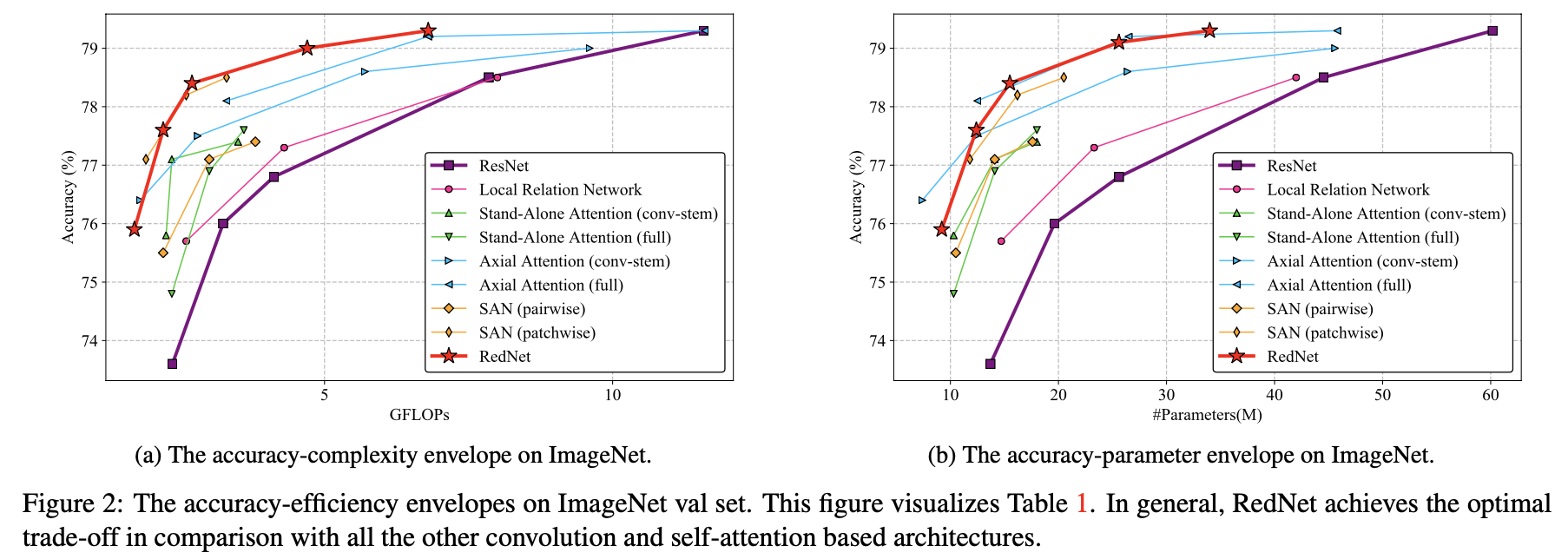
2.3 与Attention机制的关联
文章的involution操作和attention操作其实在某种意义上是统一的,对与这部分的解释可以参考下面的阐释:
- CVPR 2021 | involution:超越convolution和self-attention的神经网络新算子
- Involution=Inverse-Convolution,反着来的卷积?内卷?
3. 实验结果
消融实验:
从上面的表格内容为:
- 1)在运算条件允许的情况下使用更大的卷积核效果更好,折中选择 7 ∗ 7 7*7 7∗7;
- 2)使用分组的形式共享参数,可以减少卷积参数量以及计算量,在一定范围内不会带来较大影响,同时说明网络channel中存在一定冗余;
- 3)involution操作中产生卷积参数的两个卷积操作,其中缩放比例带来的影响;
involution为基础构建的网络与CNN构建的网络infer效率和性能的对比: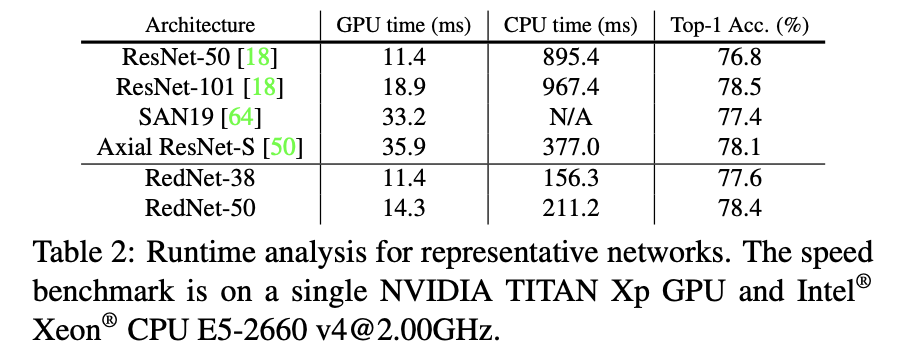
除了上面的对比之外还需要考虑实际部署时候的代码实现与硬件兼容性。


























truffle + web3 + webpack Metcoin 运行")







还没有评论,来说两句吧...