AdaBoost算法和java实现
AdaBoost算法和java实现
算法描述
输入:训练数据集 ,其中xi∈χ⊆Rn,yi∈{-1,+1};弱学习算法;
,其中xi∈χ⊆Rn,yi∈{-1,+1};弱学习算法;
输出:最终分类器G(x)。
- 初始化训练集数据的权值分布
D1=(w11,…,wiN), w1i=1/N, i=1,2…,N 对m=1,2,…,M
- (a)使用具有权值分布Dm的训练数据集学习,得到基本分类器
Gm(x):χ−−>{-1,+1}
(b) 计算Gm(x)在训练数据集上的分类误差率
em=P(Gm(xi)≠yi)=∑Ni=1wmiI(Gm(xi)≠yi)
- (c) 计算Gx的系数
αm=12log1−emem这里的对数是自然对数。
- (a)使用具有权值分布Dm的训练数据集学习,得到基本分类器
(d)更新训练数据集的权值分布
Dm+1=(wm+1,1,…wm+1,N)wm+1,i=wmiZmexp(−αmyiGm(xi)),i=1,2,…,N
,Zm是规范化因子Zm=∑Ni=1wmiexp(−αmyiGm(xi))
它是Dm+1成为一个概率分布。
3. 构建基本分类器的线性组合
f(x)=∑Mm+1αmGm(x)
得到最终分类器
G(x)=sign(f(x))=sign(∑Mm=1αmGm(x))
举例说明
数据如下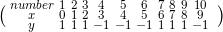
当m=1时,
根据以上的公式有D1=(w1i,w2i,…,w2i),w1i=0.1,i=1,2,…,10然后在权值分布为D1的训练数据集上,阈值v取2.5时分类的误差率最低,故分类器为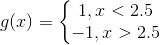
在训练集上的误差率e1=3*0.1(3表示有三个分类错误的数据,0.1对应权值数组D1上的值)
按照(c)中的公式据算 α1=12log1−e1e1=0.4236
更新数据的权值分布:
D2=(0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,0.16667,0.16667,0.16667,0.07143)()大家可以发现被错误分类的点的权值被加大了
f1(x)=α1G1(x)=0.4236G1(x)
分类器sign[f1(x)]在训练数据集上有三个错误分类点。
当m=2时,
-在权值分布为D2的训练数据集上 ,阈值v是8.5时分类误差率最低,基本分类器为
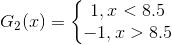
- G2(x)在训练数据集上的误差率e2=0.2143
- 计算α2=0.6496
-更新训练数据集权值分布:
D3=(0.455,0.455,0.455,0.1667,0.1667,0.1667,0.1060,0.1060,0.1060,0.0455)
f2(x)=0.4236G1(x)+0.6496G2(x)
分类器sign[f2(x)]在训练数据集上有三个错误分类点。
当m=3时,
-在权值分布为D2的训练数据集上 ,阈值v是8.5时分类误差率最低,基本分类器为
- G2(x)在训练数据集上的误差率e3=0.1820
- 计算α3=0.7514
-更新训练数据集权值分布:
D3=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)
f2(x)=0.4236G1(x)+0.6496G2(x)+0.7514G3(x)
分类器sign[f2(x)]在训练数据集上有0个错误分类点。
故:G(x)=sign[f3(x)]=sign[0.4236G1(x)+0.6496G2(x)+0.7514G3(x)]
import java.util.ArrayList;import java.util.Comparator;import java.util.HashMap;import java.util.Map;import java.util.TreeMap;public class Test08 {public ArrayList<String> list=new ArrayList<String>();public static final double k = 0.5;public static void main(String[] args) {// TODO Auto-generated method stubTest08 test=new Test08();Map<Integer, Integer> map = new HashMap<Integer, Integer>();map.put(0, 1);map.put(1, 1);map.put(2, 1);map.put(7, 1);map.put(5, -1);map.put(6, 1);map.put(8, 1);map.put(9, -1);map.put(3, -1);map.put(4, -1);System.out.println(test.adaBoost(test.sortMapByKey(map)));}public TreeMap<Integer, Integer> sortMapByKey(Map<Integer, Integer> oriMap) {if (oriMap == null || oriMap.isEmpty()) {return null;}TreeMap<Integer, Integer> sortedMap = new TreeMap<Integer, Integer>(new Comparator<Integer>() {public int compare(Integer o1, Integer o2) {// 如果有空值,直接返回0if (o1 == null || o2 == null)return 0;return String.valueOf(o1).compareTo(String.valueOf(o2));}});sortedMap.putAll(oriMap);return sortedMap;}public Map<Double,Double> adaBoost(TreeMap<Integer, Integer> data) {Map<Double,Double> result=new HashMap<Double,Double>();int dataLenght=data.size();double[] weight = new double[dataLenght];//初始化权值数组for (int i = 0; i < dataLenght; i++) {weight[i]=1.0/dataLenght;}double grade1 = 0;double grade2 = 0;//double flag = 0;String f=null;double current=0;double ah=0;double low=data.firstKey();//选取最小的特征值double high=data.lastKey();//选取最大的特征值//迭代50次for(int it=0;it<50;it++){double min=1000;double flag=low;//用来标记比较优的特征的值while(flag<=high){int index = 0;// 用来索引权值数组grade1=0;grade2=0;for (Integer en : data.keySet()) {//大于某一个特征值则为一时if(GreatToOne(en, flag)!=data.get(en)){grade1+=weight[index];}//小于某一个特征值则为一时if(LessToOne(en, flag)!=data.get(en)){grade2+=weight[index];}index++;}//选取最优的特征值if (grade1 < min) {min = grade1;current = flag;f="great";//用来标记采用的哪一个函数(GreatToOne or LessToOne)}if(grade2<min){min=grade2;current = flag;f="less";}flag+=k;//将用来分类的特征值增加k}ah=0.5*Math.log((1-min)/min);double totle=0;int j=0;//for(Integer en:data.keySet()){if(f.equals("great")){totle+=weight[j++]*Math.exp(-ah*data.get(en)*GreatToOne(en,current));}else{totle+=weight[j++]*Math.exp(-ah*data.get(en)*LessToOne(en,current));}}j=0;for(Integer en:data.keySet()){if(f.equals("great")){weight[j]=weight[j]*Math.exp(-ah*data.get(en)*GreatToOne(en,current))/totle;}else{weight[j]=weight[j]*Math.exp(-ah*data.get(en)*LessToOne(en,current))/totle;}j++;}result.put(ah, current);list.add(f);//错误率为零,则退出if(calc(result,data)==0) break;}return result;}private int calc(Map<Double, Double> result, TreeMap<Integer, Integer> data) {// TODO Auto-generated method stubint count=0;for(Integer en:data.keySet()){double sum=0;int index=0;for(Double d:result.keySet()){if(list.get(index).equals("great")){sum+=d*GreatToOne(en,result.get(d));}else{sum+=d*LessToOne(en,result.get(d));}index++;}if(sum>0&&data.get(en)==-1) {count++;}if(sum<0&&data.get(en)==1){count++;}}if(count==0){return 0;}else{return 1;}}public int GreatToOne(int x,double flag){if(x>flag) {return 1;}else{return -1;}}public int LessToOne(int x,double flag){if(x<flag) {return 1;}else{return -1;}}}
结果如下:
统计学习方法(李航)


































还没有评论,来说两句吧...