一头扎进算法导论-堆排序
定义:堆排序(Heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。可以利用数组的特点快速定位指定索引的元素。堆分为大根堆和小根堆,是完全二叉树。大根堆的要求是每个节点的值都不大于其父节点的值,即A[PARENT[i]] >= A[i]。在数组的非降序排序中,需要使用的就是大根堆,因为根据大根堆的要求可知,最大的值一定在堆顶。
过程:
用自己的话说:
分成两个步骤:
1.构造最大堆(最小堆),即把原来数组的值假想放到一个二叉堆里面去,每次放置值的时都要和自己结点的父亲进行比较,把最大(最小)的值往上排,最后构造成一个最大(最小堆)。特别要注意的一点是在二叉堆中,假设当前结点指针为i,那么父节点的指针计算公式为i/2,但是要注意一点是数组是从0开始计算的,那么就会导致当指针为2的时候计算不正确,所以一定要认识这一个点,下面是我根据概念实现的一段代码。在这段代码里面我为了分辨坐标为0的问题,使用了一个临时数组进行最大堆(最小堆的构建)
public static int[] buildMaxHeap(int[] a) {int[] temp = new int[a.length + 1];// 新建一个临时数组for (int i = 0; i < a.length; i++) {// 对每一个数进行判断int tid = i + 1;// 当前数对应临时数组的idint value = a[i];// 当前数值int pid = tid / 2;// 父结点在临时数组中的值while (temp[pid] < value && pid > 0) {// 父结点小于子结点,父结点下滑,且父结点比较大于0temp[tid] = temp[pid];// 父结点下滑tid = pid;// 当前插入位置改为原来的父节点位置pid = pid / 2;// 查现在父结点的父结点}temp[tid] = value;}return temp;}
按照上述代码可以更快理解最大堆(小堆)的构建方法,不过这里面产生出了一个临时数组,会导致了性能问题,那么接下来我将对它进行优化
public static int[] goodBuildMaxHeap(int[] a){for(int i=0;i<a.length;i++){int value = a[i];//当前值int pid = (i-1)/2;//求父节点指针,原公式:(i+1)/2-1while(a[pid]<value&&pid>-1){//注意这里的父id是可以等于0的a[i] = a[pid];//父节点下滑i=pid;//当前插入结点更改为父节点if(i==0)//插入值为0那么就不用判断了,要加这一句,否则-1/2java会提升为0,造成死循环break;pid=(i-1)/2;//再求上一个父结点}a[i]=value;//插入值}return a;}
2.进行对最大堆(小堆)排序,是这样的,因为构建最大堆(小堆)完了之后呢,最大的值会在堆顶,也就是数组的第一个元素,那么把他摘除了之后,与数组的尾部的元素进行交换位置,然后记录当前排序个数+1,最后让堆重新进行一次排序,如此循环,就能把排序好的数组整理出来。交换位置完了之后的排序是这样的,每一次把第一个元素与自己的最大子结点数交换位置,直到把最大的数冒出去。同样的要注意java的数组指针问题,计算公式是这样的,左结点l = i*2,右结点r=i*2+1,首先为了方便理解,我假设传进来的数组坐标是从1开始的,a[0]=0。
// 清除排序public static int[] percDown(int[] maxa) {int l = 0;// 当前排序个数while (true) {// 把最大的摘除int c = 1;int li = maxa.length - 1 - l;// 最后一个数坐标int ti = maxa[li];// 最后一个数if (ti < maxa[c]) {//如果最后一个数小于第一个数,那么就交换maxa[li] = maxa[c];// 最后一个数等于最大数maxa[c] = ti;// 最大数等于最小数}l++;// 成功排序一个li--;// 最后一个数左边右移int lid = 1 * 2;// 左结点idint rid = 1 * 2 + 1;// 右结点idSystem.out.println("swap before:" + Arrays.toString(maxa));System.out.println("sort:" + l);while (lid <= li || rid <= li) {// 存在子结点,子节点等于最后一个结点位置int rv = rid <= li ? maxa[rid] : 0;// 右结点的值int lv = lid <= li ? maxa[lid] : 0;// 左结点的值if (rv > lv) {// 右边大,往右边下移int temp = maxa[c];maxa[c] = maxa[rid];maxa[rid] = temp;c = rid;rid = rid * 2 + 1;lid = rid * 2;} else {// 左边大,往左边下移int temp = maxa[c];maxa[c] = maxa[lid];maxa[lid] = temp;c = lid;rid = lid * 2 + 1;lid = lid * 2;}}System.out.println("swap end:" + Arrays.toString(maxa));if (li == 1)break;}return maxa;}
通过上面代码是我按照对堆排序的思想写出来的,比较方便理解,但是传入的数组毕竟不是从1开始的,所以,同一个道理,对方法进行优化。
// 清除排序public static int[] goodPercDown(int a[]) {int l = 0;// 当前排序个数for (int i = 0; i < a.length; i++) {// 对每个数进行判断int fid = 0;// 第一个数的指针int eid = a.length - 1 - l;// 最后一个数的指针int fv = a[0];// 第一个数的值int ev = a[eid];// 最后一个数的值// 如果第一个数比最后一个数大那么置换if (fv > ev) {int t = ev;a[eid] = a[fid];a[fid] = t;}l++;// 排序个数+1eid--;// 指针-1int rid = 2 * fid + 2;// 原公式 (fid+1)*2+1-1int lid = 2 * fid + 1;// 原公式 (fid+1)*2-1System.out.println("swap before:" + Arrays.toString(a));System.out.println("sort:" + l);while (rid <= eid || lid <= eid) {// 只要子节点指针不要越界就行int rv = rid<=eid?a[rid]:0;int lv = lid<=eid?a[lid]:0;if(rv>lv){int t = a[fid];a[fid] = a[rid];a[rid] = t;fid = rid;rid = 2 * fid +2;lid = 2 * fid +1;}else{int t = a[fid];a[fid] = a[lid];a[lid] = t;fid = lid;rid = 2 * fid +2;lid = 2 * fid +1;}}System.out.println("swap end:" + Arrays.toString(a));}return a;}
以上实现均是根据图和算法思想自己写的,能达到排序目的,看书里的代码实在太难懂了,还不如根据自己的理解撸一套出来,这样还更不错,有什么不对希望有大神看到可以指点迷津
复杂度同并归排序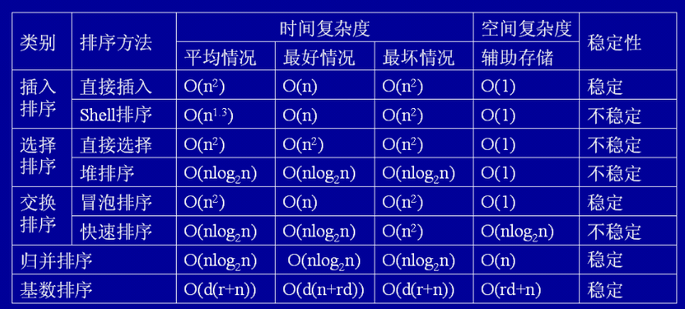
































还没有评论,来说两句吧...