HashMap源码阅读与解析
1、概述
Hashmap是一种常用的集合类,以key-value键值对的形式存在。HashMap中,可以通过hash算法来决定key-value键值对的存储位置,从而实现key-value键值对的快速查找和存储。虽然HashMap存取效率很高,却是线程不安全的,可以通过Collections类的静态方法synchronizedMap获得线程安全的HashMap或者使用ConcurrentHashMap(以后分析),hashTable虽然线程安全,但是效率太低,已经被废弃。
2、HashMap数据结构
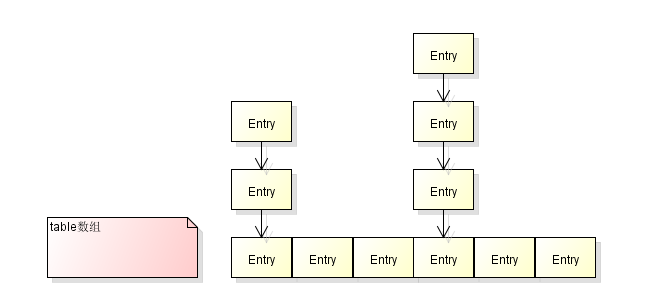
HashMap底层是一个数组,每个数组元素存放着Entry元素或者Entry元素组成的链表。Entry元素里存储着一个Key-value键值对。当有新的Entry元素要插入数组的时候,首先会根据Entry中的key值,计算hash值,然后结合数组长度,得出此Entry元素在数组中下标位置。如果存在N个数组元素计算出的数组下标一致,即出现hash冲突,那么hashMap采用链表解决这个问题。数组下标一致时,最先插入的Entry元素在链表最底层,以后再插入的Entry元素作为链表头指向下一个Entry元素。
3、HashMap关键参数和Entry类
(1)HashMap关键参数
transient Entry[] table;//存储元素的实体数组
transient int size;//存放元素的个数
int threshold; //临界值 当实际大小超过临界值时,会进行扩容threshold =加载因子*容量
final float loadFactor; //加载因子
transient int modCount;//被修改的次数
(2)Entry类
//HashMap的静态内部类static class Entry<K,V> implements Map.Entry<K,V> {//key定义成final,表示在HashMap中,key值不可以替换final K key;V value;//指向下一个Entry引用Entry<K,V> next;final int hash;/*** Creates new entry.*/Entry(int h, K k, V v, Entry<K,V> n) {value = v;next = n;key = k;hash = h;}public final K getKey() {return key;}public final V getValue() {return value;}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}//重写的equals方法public final boolean equals(Object o) {if (!(o instanceof Map.Entry))return false;Map.Entry e = (Map.Entry)o;Object k1 = getKey();Object k2 = e.getKey();if (k1 == k2 || (k1 != null && k1.equals(k2))) {Object v1 = getValue();Object v2 = e.getValue();if (v1 == v2 || (v1 != null && v1.equals(v2)))return true;}return false;}//重写的hashCode方法public final int hashCode() {return (key==null ? 0 : key.hashCode()) ^(value==null ? 0 : value.hashCode());}}
4、HashMap构造函数(为了分析方便,把构造函数分成两类:参数是集合类和参数不是集合类)
(1)参数不是集合类的构造函数(3种)
public HashMap(int initialCapacity, float loadFactor) {//检验输入的map的初始化大小数值是否合法if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);// 确保数组容量为2的n次幂,使capacity为大于initialCapacity的最小的2的n次幂int capacity = 1;while (capacity < initialCapacity)capacity <<= 1;this.loadFactor = loadFactor;//当实际大小超过临界值时,会进行扩容threshold = 加载因子*容量threshold = (int)(capacity * loadFactor);//数组table的大小一定是2的n次幂table = new Entry[capacity];init();}public HashMap(int initialCapacity) {//默认的加载因子是0.75fthis(initialCapacity, DEFAULT_LOAD_FACTOR);}public HashMap() {this.loadFactor = DEFAULT_LOAD_FACTOR;//默认的临界值是(16*0.75)threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);//默认的数组长度是16table = new Entry[DEFAULT_INITIAL_CAPACITY];init();}
(2)参数是集合类的构造函数
public HashMap(Map<? extends K, ? extends V> m) {this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);putAllForCreate(m);}private void putAllForCreate(Map<? extends K, ? extends V> m) {for (Map.Entry<? extends K, ? extends V> e : m.entrySet())putForCreate(e.getKey(), e.getValue());}private void putForCreate(K key, V value) {//根据key值计算hash值int hash = (key == null) ? 0 : hash(key.hashCode());//根据hash值和数组长度,计算存储的下标int i = indexFor(hash, table.length);//检查相应的数组下标元素中是否有与待插入数据key值相同的Entry元素,如果有,value值替换之for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {e.value = value;return;}}//在数组下标i处插入数据createEntry(hash, key, value, i);}static int indexFor(int h, int length) {return h & (length-1);}void createEntry(int hash, K key, V value, int bucketIndex) {//获取位置bucketIndex处的链表头结点引用Entry<K,V> e = table[bucketIndex];table[bucketIndex] = new Entry<>(hash, key, value, e);//map的size加1size++;}
5、put方法
public V put(K key, V value) {//key值的参数校验if (key == null)return putForNullKey(value);//获取key值的hash值int hash = hash(key.hashCode());//根据key的hash值和table数组的长度得出此键值对在数组中的下标int i = indexFor(hash, table.length);//遍历整个数组,如果key值重复,那么新value值替换旧value值for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;addEntry(hash, key, value, i);return null;}void addEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex];table[bucketIndex] = new Entry<>(hash, key, value, e);//如果size加1之后,大于等于临界值之后,那么map需要进行扩容if (size++ >= threshold)resize(2 * table.length);}void resize(int newCapacity) {Entry[] oldTable = table;int oldCapacity = oldTable.length;if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}Entry[] newTable = new Entry[newCapacity];transfer(newTable);table = newTable;//临界值重新赋值threshold = (int)(newCapacity * loadFactor);}void transfer(Entry[] newTable) {Entry[] src = table;//获取新数组的长度(原数组的两倍长度)int newCapacity = newTable.length;//遍历原数组,拿出元素中的每个Entry值,然后计算其key值的hash和数组中的下标值,组建新数组for (int j = 0; j < src.length; j++) {Entry<K,V> e = src[j];if (e != null) {src[j] = null;do {//保存指定entry的next值Entry<K,V> next = e.next;//获取指定entry在新数组中的下标值int i = indexFor(e.hash, newCapacity);//指定entry加入新数组e.next = newTable[i];newTable[i] = e;e = next;} while (e != null);}}}
6、get方法
//根据key值计算出查找数据在table数组的下标位置,然后遍历链表,获取对应key值的value值public V get(Object key) {if (key == null)return getForNullKey();int hash = hash(key.hashCode());for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {Object k;if (e.hash == hash && ((k = e.key) == key || key.equals(k)))return e.value;}return null;}
7、remove方法
public V remove(Object key) {Entry<K,V> e = removeEntryForKey(key);return (e == null ? null : e.value);}final Entry<K,V> removeEntryForKey(Object key) {int hash = (key == null) ? 0 : hash(key.hashCode());int i = indexFor(hash, table.length);Entry<K,V> prev = table[i];Entry<K,V> e = prev;while (e != null) {Entry<K,V> next = e.next;Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {modCount++;size--;if (prev == e)table[i] = next;elseprev.next = next;e.recordRemoval(this);return e;}prev = e;e = next;}return e;}
8、分析下为什么哈希表的容量一定要是2的整数次幂
首先,length为2的整数次幂的话,h&(length-1)就相当于对length取模,这样便保证了散列的均匀,同时也提升了效率;其次,length为2的整数次幂的话,为偶数,这样length-1为奇数,奇数的最后一位是1,这样便保证了h&(length-1)的最后一位可能为0,也可能为1(这取决于h的值),即与后的结果可能为偶数,也可能为奇数,这样便可以保证散列的均匀性,而如果length为奇数的话,很明显length-1为偶数,它的最后一位是0,这样h&(length-1)的最后一位肯定为0,即只能为偶数,这样任何hash值都只会被散列到数组的偶数下标位置上,这便浪费了近一半的空间,因此,length取2的整数次幂,是为了使不同hash值发生碰撞的概率较小,这样就能使元素在哈希表中均匀地散列。
这看上去很简单,其实比较有玄机的,我们举个例子来说明:
假设数组长度分别为15和16,优化后的hash码分别为8和9,那么&运算后的结果如下:
h & (table.length-1) hash table.length-18 & (15-1): 0100 & 1110 = 01009 & (15-1): 0101 & 1110 = 0100-----------------------------------------------------------------------------------------------------------------------8 & (16-1): 0100 & 1111 = 01009 & (16-1): 0101 & 1111 = 0101从上面的例子中可以看出:当它们和15-1(1110)“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到数组中的同一个位置上形成链表,那么查询的时候就需要遍历这个链 表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hash值会与15-1(1110)进行“与”,那么 最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!而当数组长度为16时,即为2的n次方时,2n-1得到的二进制数的每个位上的值都为1,这使得在低位上&时,得到的和原hash的低位相同,加之hash(int h)方法对key的hashCode的进一步优化,加入了高位计算,就使得只有相同的hash值的两个值才会被放到数组中的同一个位置上形成链表。
所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
参考博文:http://www.cnblogs.com/ITtangtang/p/3948406.html
http://www.cnblogs.com/chenssy/p/3521565.html

























![[ansible]-ansible-playbook执行端口健康检查](https://image.dandelioncloud.cn/images/20221120/96d30ae461ed48a58ee018395aba0a40.png "[ansible]-ansible-playbook执行端口健康检查")








还没有评论,来说两句吧...