JVM内存模型
JVM内存模型
JVM内存模型大体分5部分:程序计数器(Program Counter Register)、JVM虚拟机栈(JVM Stacks)、本地方法栈(Native Method Stacks)、堆(Heap)、方法区(Method Area)
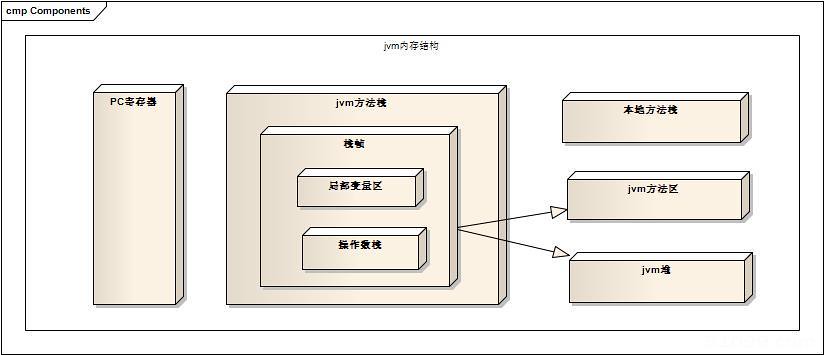
1、程序计数器(Program Counter Register)
这是一块比较小的内存,不在Ram上,而是直接划分在CPU上的,程序员无法直接操作它,它的作用是:JVM在解释字节码文件(.class)时,存储当前线程所执行的字节码的行号,只是一种概念模型,各种JVM所采用的方式不同,字节码解释器工作时,就是通过改变程序计数器的值来选取下一条要执行的指令,分支、循环、跳转、等基础功能都是依赖此技术区完成的。还有一种情况,就是我们常说的Java多线程方面的,多线程就是通过现程轮流切换而达到的,同一时刻,一个内核只能执行一个指令,所以,对于每一个程序来说,必须有一个计数器来记录程序的执行进度,这样,当现程恢复执行的时候,才能从正确的地方开始,所以,每个线程都必须有一个独立的程序计数器,这类计数器为线程私有的内存。
如果一个线程正在执行一个Java方法,则计数器记录的是字节码的指令的地址,如果执行的一个Native方法,则计数器的记录为空。
程序计数器是唯一一个在Java规范中没有任何OutOfMemoryError情况的区域。
2、JVM虚拟机栈(JVM Stacks)
VM虚拟机栈就是我们常说的堆栈的栈(我们常常把内存粗略分为堆和栈),和程序计数器一样,也是线程私有的,生命周期和线程一样,每个方法被执行的时候会产生一个栈帧。
栈用于存储局部变量表、动态链接、操作数栈、方法出口等信息。
栈用于存储局部变量表即:Java 8种数据类型,及引用类型(存放的是指向各个对象的内存地址)
操作数据栈作用
1、解析常量池里面的数据
2、方法执行完后处理方法返回,恢复调用方现场
3、方法执行过程中抛出异常时的异常处理,存储在一个异常表,当出现异常时虚拟机查找相应的异常表看是否有对应的Catch语句,如果没有就抛出异常终止这个方法调用
方法的执行过程就是栈帧在JVM中出栈和入栈的过程。
内存空间可以在编译期间就确定,运行期不在改变。这个内存区域会有两种可能的Java异常:StackOverFlowError和OutOfMemoryError。
3、本地方法栈(Native Method Stacks)
用来处理Java中的本地方法的,Java类的祖先类Object中有众多Native方法,如hashCode()、wait()等,他们的执行很多时候是借助于操作系统,但是JVM需要对他们做一些规范,来处理他们的执行过程。
在SUN的HOT SPOT虚拟机中,不区分本地方法栈和虚拟机栈。因此,也会抛出StackOverFlowError和OutOfMemoryError
4、堆(Heap)
因为Java性能的优化,主要就是针对这部分内存的。几乎(JIT)所有的对象实例及数组都是在堆上面分配的,可通过-Xmx和-Xms来控制堆的大小。
堆内存是垃圾回收的主要区域
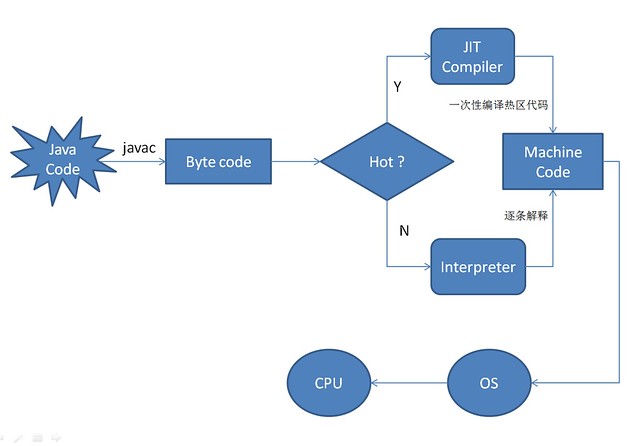
JIT 是 just in time 的缩写, 也就是即时编译编译器。使用即时编译器技术,能够加速 Java 程序的执行速度。
对于 Java 代码,刚开始都是被编译器编译成字节码文件,然后字节码文件会被交由 JVM 解释执行,所以可以说 Java 本身是一种半编译半解释执行的语言。Hot Spot VM 采用了 JIT compile 技术,将运行频率很高的字节码直接编译为机器指令执行以提高性能,所以当字节码被 JIT 编译为机器码的时候,要说它是编译执行的也可以。也就是说,运行时,部分代码可能由 JIT 翻译为目标机器指令(以 method 为翻译单位,还会保存起来,第二次执行就不用翻译了)直接执行。
5、方法区(Method Area)
方法区是所有线程共享的内存区域,用于存储已经被JVM加载的类信息、常量、静态变量等数据,一般来说,方法区属于持久代。
方法区中一个重要的概念:运行时常量池。主要用于存放在编译过程中产生的字面量(字面量简单理解就是常量)和引用。
一般情况,常量的内存分配在编译期间就能确定,但不一定全是,有一些可能就是运行时也可将常量放入常量池中,如String类中有个Native方法intern()
在JVM内存管理之外的一个内存区:直接内存。在JDK1.4中新加入类NIO类,引入了一种基于通道与缓冲区的I/O方式,它可以使用Native函数库直接分配堆外内存,即我们所说的直接内存,这样在某些场景中会提高程序的性能。
参考:http://blog.csdn.net/zhangerqing/article/details/8214365

























Deep Multi-instance Networks with Sparse Label Assignment for Whole Mammogram Classific")




")



还没有评论,来说两句吧...