JVM内存模型
一 先看jvm的知识结构
 ## 二 jvm的内存区域
## 二 jvm的内存区域
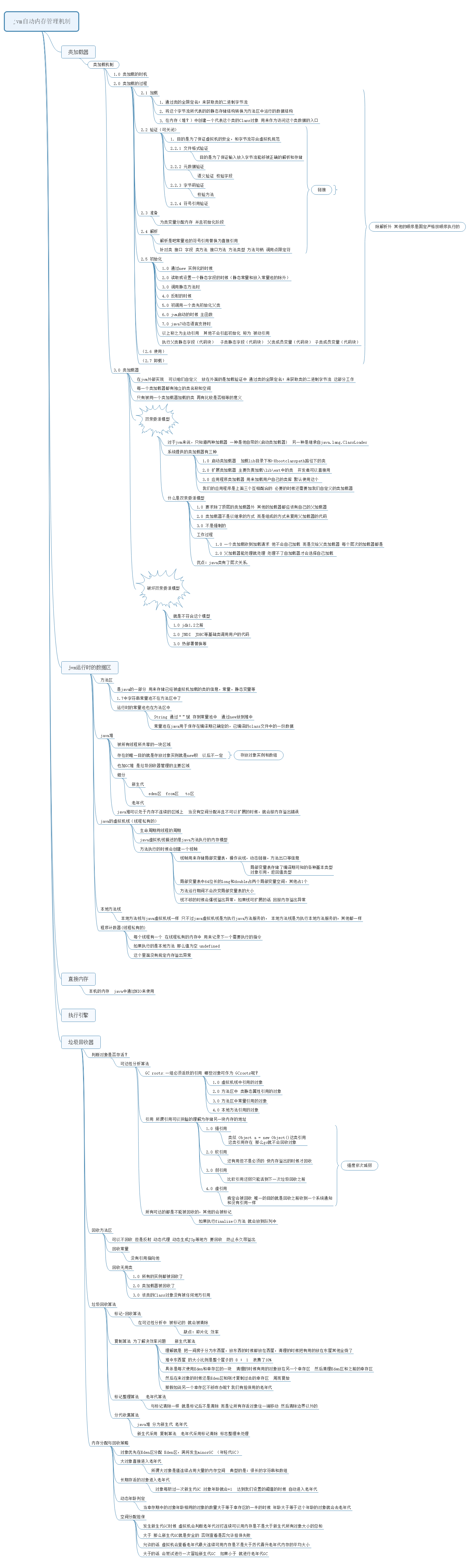
1. jvm内存区域
jvm一共由 java堆 方法区 Java栈 本地方法栈 pc计数器——————-这五个是运行时的数据区 还有类加载器 直接内存 垃圾回收器 执行引擎组成
1.1 Java堆
- 堆是分配实例的地方,是所有线程共享的 eg:A a = new A(); 对象A的分配的空间就是在堆中分配的
- 几乎所有的对象分配内存都是在堆中分配的,但是也有在栈中分配(逃逸分析时候会在栈中分配)
- 垃圾回收主要是针对堆进行的
1.2 方法区
方法区也可以理解为堆的一部分,只是存储的数据类型不一样,堆中存储的是对象实例的数据,例如 类中A的字段,方法,话句话说 举个例子:
class A{int a = 1;static int b = 4;final int c = 5;public A(){};public int getA(){return a;}}
这个类的结构就是存储在堆中,而关于这个类的信息就是存储在方法区中
也就是方法区中存储的是类信息,静态量 常量 JIT编译的代码等数据,,外加运行时的常量池
上述A中 这个类是类还是抽象类,还是接口,父类是什么,常量是什么,类变量是什么,类的名字是什么,都存储在方法区
1.3 pc计数器
pc计数器 记录的是将要执行的下一条指令的地址 如果是在执行本地方法中的代码 pc计数器的值为null
1.4 jvm栈
- 栈是方法执行的内存模型,每个方法的执行和退出就是栈帧的出栈和入栈的过程
- 每个方法对应一个栈帧,栈帧会存储方法的参数(操作数栈),局部变量表 返回值类型,动态链接(解析引用)
1.5 本地方法栈
功能同java栈 区别就是Java栈执行的是Java的方法 本地方法栈执行的是本地方法
2. 运行时的常量池
2.1 运行时的常量池存储在方法区中
2.2 主要存储 类变量 常量 编译期身生成的各种字面量和符号引用 字面量就是 String a =“字面量”; a就是符号引用, a的值就是字面量
2.3 String.intern() 从常量池中返回值
3. 对象的创建过程
首先判断这个类是否加载过美加载过就加载,加载过就通过指针碰撞或者空间列表的方式在堆中分配内存初始化字段的默认值 int的是0 boolean的是false 。。。。设置对象头信息 hashcode 分代年龄 锁信息等按我们程序的要求初始化 也就是 int a = 9;设置a的值是9 上一步是设置a的值是0
4. 对象的内存布局
对象有三部分组成 对象头,数据区,对齐填充
4.1 对象头
对象头部分记录对象的hash值,分代年龄,锁信息 偏向锁偏向的线程等等 对于数组来说还存储数组的长度 i那位对象的大小jvm是可知的,但是数组有多少个对象就不知道了;还会存储类型指针就是这个对象的类的信息——也就是指向方法区
4.2 实例数据
就是对象中的实际数据了
4.3 对齐填充
这部分是可有可无的,jvm要求对象的大小必须为8的整数倍,如果大小是就没必要填充了,否则就填充
5. 对象的访问定位
栈中的引用怎么找到队中对应的实例呢?
- 通过句柄访问 假设 A a = new A();
在堆中有个区域专门记录了实例A的位置 我们叫他句柄 句柄记录了实例的位置 以及类型的位置(一个指向堆,一个指向方法区)- 直接使用指针访问———栈中记录实例在堆中的地址

























Deep Multi-instance Networks with Sparse Label Assignment for Whole Mammogram Classific")




")



还没有评论,来说两句吧...