Flume-ng 多节点集群搭建
http://blog.csdn.net/u010695420/article/details/44978079
Flume NG是一个分布式、可靠、可用的系统,它能够将不同数据源的海量日志数据进行高效收集、聚合,最后存储到一个中心化数据存储系统中,方便进行数据分析。事实上flume也可以收集其他信息,不仅限于日志。由原来的Flume OG到现在的Flume NG,进行了架构重构,并且现在NG版本完全不兼容原来的OG版本。相比较而言,flume NG更简单更易于管理操作。
Flume OG:Flume original generation 即Flume 0.9.x版本
Flume NG:Flume next generation ,即Flume 1.x版本。
Flume NG用户参考手册:http://flume.apache.org/FlumeUserGuide.html#
Flume1.5.2下载地址:
http://www.apache.org/dyn/closer.cgi/flume/1.5.2/apache-flume-1.5.2-bin.tar.gz
简单比较一下两者的区别:
OG有三个组件agent、collector、master,agent主要负责收集各个日志服务器上的日志,将日志聚合到collector,可设置多个collector,master主要负责管理agent和collector,最后由collector把收集的日志写的HDFS中,当然也可以写到本地、给storm、给Hbase。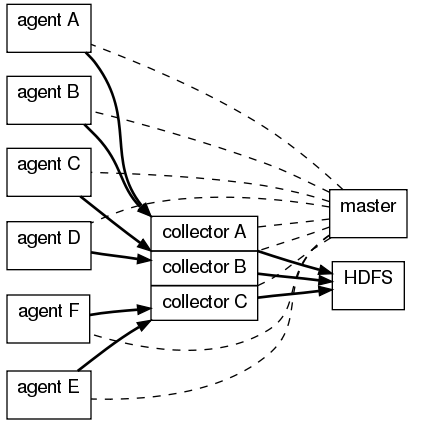
NG最大的改动就是不再有分工角色设置,所有的都是agent,可以彼此之间相连,多个agent连到一个agent,此agent也就相当于collector了,NG也支持负载均衡,具体参见http://shiyanjun.cn/archives/915.html。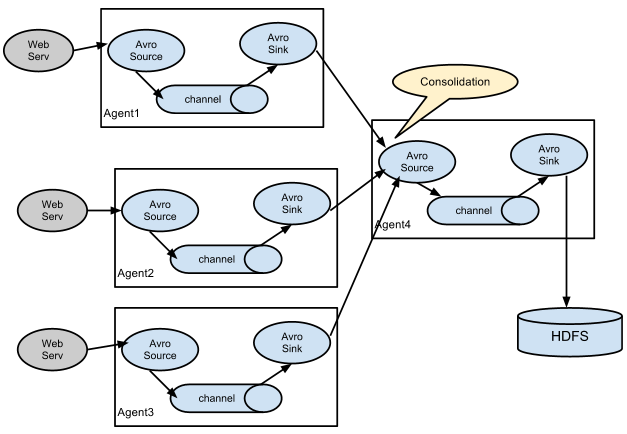
现在我们准备了三台机器(虚拟机也可以,但出现的问题也会很多,比如内存空间不足,网络连接问题,此处已哭晕)。
操作系统:CentOS 6.6
Flume版本:1.5.2
设置三台机器的IP地址分别为192.168.1.105,192.168.1.106,192.168.1.107,记得关闭防火墙:
命令service iptables stop
环境准备好之后,在flume/conf/下新建agent.conf文件,105和106配置一样,如下:
#AgentflumeAgent.channels = c1flumeAgent.sources = s1flumeAgent.sinks = k1#flumeAgent Spooling Directory Source#注(1)flumeAgent.sources.s1.type = spooldirflumeAgent.sources.s1.spoolDir =/usr/logs/flumeAgent.sources.s1.fileHeader = trueflumeAgent.sources.s1.deletePolicy =immediateflumeAgent.sources.s1.batchSize =1000flumeAgent.sources.s1.channels =c1flumeAgent.sources.s1.deserializer.maxLineLength =1048576#flumeAgent FileChannel#注(2)flumeAgent.channels.c1.type = fileflumeAgent.channels.c1.checkpointDir = /var/flume/spool/checkpointflumeAgent.channels.c1.dataDirs = /var/flume/spool/dataflumeAgent.channels.c1.capacity = 200000000flumeAgent.channels.c1.keep-alive = 30flumeAgent.channels.c1.write-timeout = 30flumeAgent.channels.c1.checkpoint-timeout=600# flumeAgent Sinks#注(3)flumeAgent.sinks.k1.channel = c1flumeAgent.sinks.k1.type = avro# connect to CollectorMainAgentflumeAgent.sinks.k1.hostname = 192.168.1.107flumeAgent.sinks.k1.port = 444441234567891011121314151617181920212223242526272829
我们设置107机器为汇聚节点,105和106的日志文件都将集中到这里,在flume/conf/下新建consolidatio.conf文件,配置如下:
#flumeConsolidationAgentflumeConsolidationAgent.channels = c1flumeConsolidationAgent.sources = s1flumeConsolidationAgent.sinks = k1#flumeConsolidationAgent Avro Source#注(4)flumeConsolidationAgent.sources.s1.type = avroflumeConsolidationAgent.sources.s1.channels = c1flumeConsolidationAgent.sources.s1.bind = 192.168.1.107flumeConsolidationAgent.sources.s1.port = 44444#flumeConsolidationAgent FileChannelflumeConsolidationAgent.channels.c1.type = fileflumeConsolidationAgent.channels.c1.checkpointDir = /var/flume/spool/checkpointflumeConsolidationAgent.channels.c1.dataDirs = /var/flume/spool/dataflumeConsolidationAgent.channels.c1.capacity = 200000000flumeConsolidationAgent.channels.c1.keep-alive = 30flumeConsolidationAgent.channels.c1.write-timeout = 30flumeConsolidationAgent.channels.c1.checkpoint-timeout=600##flumeConsolidationAgent Memory Channel#flumeConsolidationAgent.channels.c1.type = memory#flumeConsolidationAgent.channels.c1.capacity = 10000#flumeConsolidationAgent.channels.c1.transactionCapacity = 10000#flumeConsolidationAgent.channels.c1.byteCapacityBufferPercentage = 20#flumeConsolidationAgent.channels.c1.byteCapacity = 800000#flumeConsolidationAgent Sinks#注(5)flumeConsolidationAgent.sinks.k1.channel= c1flumeConsolidationAgent.sinks.k1.type = file_rollflumeConsolidationAgent.sinks.k1.sink.directory = /var/tmpflumeConsolidationAgent.sinks.k1.sink.rollInterval = 3600flumeConsolidationAgent.sinks.k1.batchSize = 100001234567891011121314151617181920212223242526272829303132333435
配置完成后,先启动107,命令行:
bin/flume-ng agent --conf conf --conf-file conf/consolidatio.conf --name flumeConsolidationAgent -Dflume.root.logger=DEBUG,console1
再启动105和106,命令行:
bin/flume-ng agent --conf conf --conf-file conf/agent.conf --name flumeAgent -Dflume.root.logger=DEBUG,console1
此处有三种模式运行:INFO、DEBUG、ERROR,以次容错度升高。
注(1):sources类型为spooldir,监控某一目录下的文件,一旦有文件进入,则收割。被收割的文件不能再打开编辑,此处设置收割完毕后直接删除文件,这儿我出现的一个问题是,直接手动往该目录下拷贝文件一旦文件大小高于20M左右就宕机,提前拷入则正常,后来查到原因是拷贝的的速度远远小于收割的速度,有种文件被操作的感觉,所以出错。
注(2):channel类型为file。
MemoryChannel: 所有的events被保存在内存中。优点是高吞吐。缺点是容量有限并且Agent死掉时会丢失内存中的数据。
FileChannel: 所有的events被保存在文件中。优点是容量较大且死掉时数据可恢复。缺点是速度较慢。
注(3):sink类型为avro,hostname都要指向的consolidation的IP,端口号可以任意设置,只要不冲突就行,这样也会出现问题,当107的flumeConsolidationAgent重新启动后会出现“地址已被占用的”错误,要么修改端口号,要么杀死该进程。
注(4):consolidation要绑定本机的IP,端口号也要与105和106一致。
注(5):此处我们将收集的文件存入本地,并没有写入HDFS,因为还要装Hadoop。这里要千万注意所有sinks的channel,比如x.sinks.k1.channel = c1中的channel一定不加s。
成功后,我们将看到如下信息:
但是单独使用flume意义不大,需要结合其他工具一起组成大数据架构。
大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合:
http://www.aboutyun.com/thread-6855-1-1.html(出处: about云开发)
Flume+Kafka+Strom基于分布式环境的结合使用:
http://www.aboutyun.com/thread-8915-1-1.html(出处: about云开发)
欢迎批评指正!



























 和心电图 (ECG) 基本工作原理")

")




还没有评论,来说两句吧...