【Hadoop集群搭建第三期】集群节点配置
【Hadoop集群搭建第一期】Ubuntu中的Hadoop及Java环境的安装和配置:https://blog.csdn.net/DXH924/article/details/103832306
【Hadoop集群搭建第二期】节点克隆及SSH无密码验证配置:
https://blog.csdn.net/DXH924/article/details/103841437
本期的任务是Hadoop集群搭建的重中之重,所有操作都是建立在前两期的基础上的
下面进入正题
【第一步】配置静态ip
VMware Workstation中点击【编辑】->【虚拟网络编辑器】->【更改设置】
选中VMnet8,去掉“使用本地DHCP服务将ip地址分配给虚拟机”前的勾,【应用】

下面操作三个节点都要进行,执行命令
sudo nano /etc/network/interfaces
在配置中添加,ip地址根据第一期中ifconfig得出的ip地址进行设定
此处的192.168.153.133为master的ip
auto ens33iface ens33 inet staticaddress 192.168.153.133netmask 255.255.255.0gateway 192.168.153.2dns-nameserver 114.114.114.114

保存配置并重启网卡
sudo /etc/init.d/networking restartsudo ifdown ens33sudo ifup ens33
命令ifconfig查看ens33的ip,重启三个主机后互ping,确保ip修改成功
这里需要改成之前hosts配置里面的ip地址

【第二步】配置Hadoop参数
以下操作在master中进行
执行如下命令,配置core-site.xml
cd /usr/local/hadoop/etc/hadoopsudo nano core-site.xml添加配置<property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property>

执行如下命令,配置hadoop-env.sh
sudo nano hadoop-env.sh在末尾添加export JAVA_HOME=/usr/lib/jvm/default-javaexport HDFS_NAMENODE_USER="hadoop"export HDFS_DATANODE_USER="hadoop"export HDFS_SECONDARYNAMENODE_USER="hadoop"export YARN_RESOURCEMANAGER_USER="hadoop"export YARN_NODEMANAGER_USER="hadoop"

执行如下命令,配置hdfs-site.xml
sudo nano hdfs-site.xml添加配置<property><name>dfs.namenode.name.dir</name><value>/usr/local/hadoop/hdfs/name</value></property><property><name>dfs.namenode.data.dir</name><value>/usr/local/hadoop/hdfs/data</value></property><property><name>dfs.replication</name><value>3</value></property>

执行如下命令,配置mapred-site.xml
sudo nano mapred-site.xml添加配置<property><name>mapreduce.framework.name</name><value>yarn</value></property>

执行如下命令,配置workers
sudo nano workers添加masterslave1slave2

执行如下命令,配置yarn-site.xml
sudo nano yarn-site.xml<property><name>yarn.resourcemanager.hostname</name><value>master</value></property><property><name>yarn.resoourcemanager.webapp.address</name><value>192.168.153.133:8088</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>

【第三步】将配置发送给slave节点
将 hadoop 目录从 master 拷贝到 slave1 与 slave2,覆盖原来的配置文件
由于之前配置了免密登录,所以不需要输入密码即可完成拷贝
scp -qr /usr/local/hadoop/etc/hadoop slave1:/usr/local/hadoop/etcscp -qr /usr/local/hadoop/etc/hadoop slave2:/usr/local/hadoop/etc
【第四步】创建临时文件目录 (三台机器都需创建)
创建的目录对应于hdfs-site.xml 中配置的目录
即/usr/local/hadoop/hdfs/name和/usr/local/hadoop/hdfs/data
输入命令
mkdir -p /usr/local/hadoop/hdfs/datamkdir -p /usr/local/hadoop/hdfs/name
【第五步】格式化 hdfs 文件系统
在master结点执行命令
hdfs namenode -format

出现“Storage directory /usr/local/hadoop/hdfs/name has been successfully formatted”提示
表示格式化成功

【第六步】启动Hadoop集群
master中执行命令
start-all.sh
执行命令jps查看进程
若有6个进程,即DataNode, NameNode, SecondaryNameNode,
Jps, ResourceManager以及NodeManager,说明Hadoop集群搭建成功

slave中执行命令jps
会看到3个进程,即DataNode, NodeManager以及Jps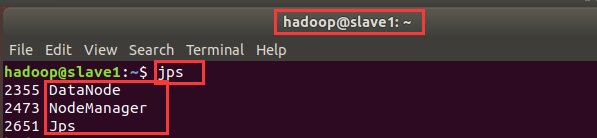
【第七步】查看可视化界面
web中进入master:8088查看集群信息

进入master:9870查看HDFS文件系统,【Utilities】->【browse the file system】,此时根目录下没有任何文件

【第八步】上传文件到HDFS
上传文件测试
cd /usr/local/hadoop #选择目录ls #查看目录文件hdfs -dfs -put LICENSE.txt / #上传LICENSE.txt到HDFS根目录下hdfs -dfs -ls / #查看HDFS文件目录

可视化页面也可查看HDFS中的文件
到此,Hadoop集群搭建完成!!!


































还没有评论,来说两句吧...